Infrequent freedreno update
11. Únor 2018 v 23:46
As is usually the case, I'm long overdue for an update. So this covers the last six(ish) months or so. The first part might be old news if you follow phoronix.
Also I r/e'd and added support for indirect compute, indirect draw, texture-gather, stencil textures, and ARB_framebuffer_no_attachments on a5xx. Which brings us pretty close to gles31 support. And over the holiday break I r/e'd and implemented tiled texture support, because moar fps ;-)
Ilia Mirkin also implemented indirect draw, stencil texture, and ARB_framebuffer_no_attachments for a4xx. Ilia and Wladimir J. van der Laan also landed a handful of a2xx and a20x fixes. (But there are more a20x fixes hanging out on a branch which we still need to rebase and merge.) It is definitely nice seeing older hw, which blob driver has long since dropped support for, getting some attention.
Fwiw, the v4l2 mem-to-mem driver interface is becoming the defacto standard for hw video decode/encode on SoC's. GStreamer has had support for a long time now. And more recently ffmpeg (v3.4) and kodi have gained support:
When I first started on freedreno, qcom support for upstream kernel was pretty dire (ie. I think serial console support might have worked on some ancient SoC). When I started, the only kernel that I could use to get the gpu running was old downstream msm android kernels (initially 2.6.35, and on later boards 3.4 and 3.10). The ifc6410 was the first board that I (eventually) could run an upstream kernel (after starting out with an msm-3.4 kernel), and the db410c was the first board I got where I never even used an downstream android kernel. Initially db410c was upstream kernel with a pile of patches, although the size of the patchset dropped over time. With db820c, that pattern is repeating again (ie. the patchset is already small enough that I managed to easily rebase it myself for after 4.14). Linaro and qcom have been working quietly in the background to upstream all the various drivers that something like drm/msm depend on to work (clk, genpd, gpio, i2c, and other lower level platform support). This is awesome to see, and the linaro/qcom developers behind this progress deserve all the thanks. Without much fanfare, snapdragon has gone from a hopeless case (from upstream perspective) to one of the better supported platforms!
Thanks to the upstream kernel support, and u-boot/UEFI support which I've mentioned before, Fedora 27 supports db410c out of the box (and the situation should be similar with other distro's that have new enough kernel (and gst/ffmpeg/kodi if you care about hw video decode). Note that the firmware for db410c (and db820c) has been merged in linux-firmware since that blog post.
In other news, things are starting to get interesting for snapdragon 845 (sdm845). Initial patches for a6xx GPU support have been posted (although I still need to my hands on a6xx hw to start r/e for userspace, so those probably won't be merged soon). And qcom has drm/msm display support buried away in their msm-4.9 tree (expect to see first round of patches for upstream soon.. it's a lot of code, so expect some refactoring before it is merged, but good to get this process started now).
Older News
In the last update, I mentioned basic a5xx compute shader support. Late last year (and landing in the mesa 18.0 branch) I had a chance to revisit compute support for a5xx, and finished:- image support
- shared variable support
- barriers, which involved some improvements to the ir3 instruction scheduler so barriers could be scheduled in the correct order (ie. for various types of barriers, certain instructions can't be move before/after the related barrier
Also I r/e'd and added support for indirect compute, indirect draw, texture-gather, stencil textures, and ARB_framebuffer_no_attachments on a5xx. Which brings us pretty close to gles31 support. And over the holiday break I r/e'd and implemented tiled texture support, because moar fps ;-)
Ilia Mirkin also implemented indirect draw, stencil texture, and ARB_framebuffer_no_attachments for a4xx. Ilia and Wladimir J. van der Laan also landed a handful of a2xx and a20x fixes. (But there are more a20x fixes hanging out on a branch which we still need to rebase and merge.) It is definitely nice seeing older hw, which blob driver has long since dropped support for, getting some attention.
Other News
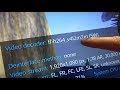
Not exactly freedreno related, but probably of some interest to freedreno users.. in the 4.14 kernel, my qcom_iommu driver finally landed! This was the last piece to having the gpu working on a vanilla upstream kernel on the dragonboard 410c. In addition, the camera driver also landed in 4.14, and venus, the v4l2 mem-to-mem driver for hw video decode/encode landed in 4.13. (The venus driver also already has support for db820c.)Fwiw, the v4l2 mem-to-mem driver interface is becoming the defacto standard for hw video decode/encode on SoC's. GStreamer has had support for a long time now. And more recently ffmpeg (v3.4) and kodi have gained support:
When I first started on freedreno, qcom support for upstream kernel was pretty dire (ie. I think serial console support might have worked on some ancient SoC). When I started, the only kernel that I could use to get the gpu running was old downstream msm android kernels (initially 2.6.35, and on later boards 3.4 and 3.10). The ifc6410 was the first board that I (eventually) could run an upstream kernel (after starting out with an msm-3.4 kernel), and the db410c was the first board I got where I never even used an downstream android kernel. Initially db410c was upstream kernel with a pile of patches, although the size of the patchset dropped over time. With db820c, that pattern is repeating again (ie. the patchset is already small enough that I managed to easily rebase it myself for after 4.14). Linaro and qcom have been working quietly in the background to upstream all the various drivers that something like drm/msm depend on to work (clk, genpd, gpio, i2c, and other lower level platform support). This is awesome to see, and the linaro/qcom developers behind this progress deserve all the thanks. Without much fanfare, snapdragon has gone from a hopeless case (from upstream perspective) to one of the better supported platforms!
Thanks to the upstream kernel support, and u-boot/UEFI support which I've mentioned before, Fedora 27 supports db410c out of the box (and the situation should be similar with other distro's that have new enough kernel (and gst/ffmpeg/kodi if you care about hw video decode). Note that the firmware for db410c (and db820c) has been merged in linux-firmware since that blog post.
More Recent News
More recently, I have been working on a batch of (mostly) compiler related enhancements to improve performance with things that have more complex shaders. In particular:- Switch over to NIR's support for lowering phi-web's to registers, instead of dealing with phi instructions in ir3. NIR has a much more sophisticated pass for coming out of SSA, which does a better job at avoiding the need to insert extra MOV instructions, although a bunch of RA (register allocation) related fixes were required. The end result is fewer instructions in resulting shader, and more importantly a reduction in register usage.
- Using NIR's peephole_select pass to lower if/else, instead of our own pass. This was a pretty small change (although it took some work to arrive at a decent threshold). Previously the ir3_nir_lower_if_else pass would try to lower all if/else to select instructions, but in extreme cases this is counter-productive as it increases register pressure. (Background: in simple cases for a GPU, executing both sides of an if/else and using a select instruction to choose the results makes sense, since GPUs tend to be a SIMT arch, and if you aren't executing both sides, you are stalling threads in a warp that took the opposite direction in the if/else.. but in extreme cases this increases register usage which reduces the # of warps in flight.) End result was 4x speedup in alu2 benchmark, although in the real world it tends to matter less (ie. most shaders aren't that complex).
- Better handling of sync flags across basic blocks
- Better instruction scheduling across basic blocks
- Better instruction scheduling for SFU instructions (ie. sqrt, rsqrt, sin, cos, etc) to avoid stalls on SFU.
- R/e and add support for (sat)urate flag flag (to avoid extra sequence of min.f + max.f instructions to clamp a result)
- And a few other tweaks.
In other news, things are starting to get interesting for snapdragon 845 (sdm845). Initial patches for a6xx GPU support have been posted (although I still need to my hands on a6xx hw to start r/e for userspace, so those probably won't be merged soon). And qcom has drm/msm display support buried away in their msm-4.9 tree (expect to see first round of patches for upstream soon.. it's a lot of code, so expect some refactoring before it is merged, but good to get this process started now).
![]()