Across the internet, from online forums such as Reddit to various other tech media outlets, there's a lot of furor around reports of Intel's top-end 14th and 13th Gen K series of processors running into stability issues. As Intel's flagship chips, these parts come aggressively clocked in order to maximize performance through various implementations of boost and turbo, leaving them running close to their limits out of the box. But with high-end motherboards further goosing these chips to wring even more performance out of them, it would seem that the Intel desktop ecosystem has finally reached a tipping point where all of these efforts to boost performance have pushed these flagship chips to unstable conditions. To that end, Intel has released new gudiance to its consumer motherboard partners, strongly encouraging them to actually implment Intel's stock power settings, and to use those baseline settings as their out-of-the-box default.
While the underlying conditions are nothing new – we've published stories time and time again about motherboard features such as multi-core enhancement (MCE) and raised power consumption limits that seek to maximize how hard and how long systems are able to turbo boost – the issue has finally come to a head in the last couple of months thanks to accumulating reports of system instability with Intel's 13900K and 14900K processors. These instability problems are eventually solved by either tamping down on these motherboard performance-boosting features – bringing the chips back down to something closer to Intel's official operating parameters – or downclocking the chips entirely.
Intel first began publicly investigating the matter on the 27th of February, when Intel's Communications Manager, Thomas Hannaford, posted a thread on Intel's Community Product Support Forms titled "Regarding Reports of 13th/14th Gen Unlocked Desktop Users Experiencing Stability Issues". In this thread, Thomas Hannaford said, "Intel is aware of reports regarding Intel Core 13th and 14th Gen unlocked desktop processors experiencing issues with certain workloads. We're engaged with our partners and are conducting analysis of the reported issues. If you are experiencing these issues, please reach out to Intel Customer Support for further assistance in the interim."
Since that post went up, additional reports have been circulating about instability issues across various online forums and message boards. The underlying culprit has been theorized to be motherboards implementing an array of strategies to improve chip performance, including aggressive multi-core enhancement settings, "unlimited" PL2 turbo, and reduced load line calibration settings. At no point do any of these settings overclock a CPU and push it to a higher clockspeed than it's validated for, but these settings do everything possible to keep a chip at the highest clockspeed possible at all times – and in the process seem to have gone a step too far.
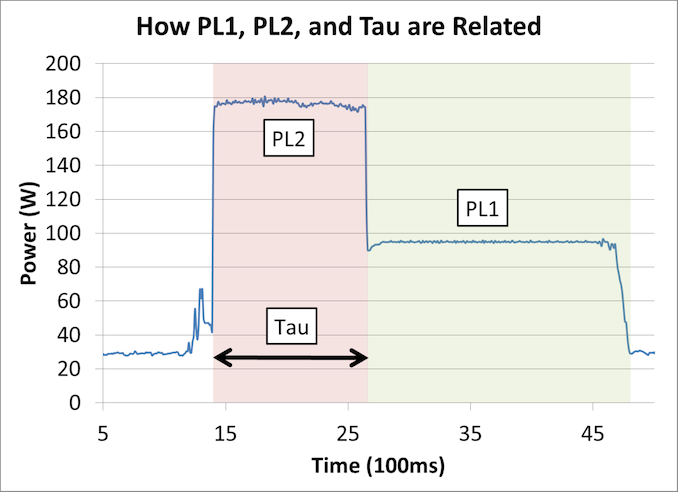
From "Why Intel Processors Draw More Power Than Expected: TDP and Turbo Explained"
We wrote a piece initially covering multi-core enhancement in 2012, detailing how motherboard manufacturers try to stay competitive with each other and leverage any headroom within the silicon to output the highest performance levels. And more recently, we've talked about how desktop systems with Intel chips are now regularly exceeding their rated TDPs – sometimes by extreme amounts – as motherboard vendors continue to push them to run as hard as possible for the best performance.
But things have changed since 2012. At the time, this wasn't so much of an issue, as overclocking was actually very favorable to increasing the performance of processors. But in 2024 with chips such as the Intel Core i9-14900K, we have CPUs shipping with a maximum turbo clock speed of 6.0 GHz and a peak power consumption of over 400 Watts, figures that were only a pipe dream a decade ago.
Jumping to the present time, over the weekend Intel released a statement about the matter to its partners, outlining their investigation so far and their suggestions/requests to their partners. That statement was quickly leaked to the press, with Igorslab.de and others breaking the news. Since then, we've been able to confirm through official sources that this is a real and accurate statement from Intel.
This statement reads as follows:
Intel® has observed that this issue may be related to out of specification operating conditions resulting in sustained high voltage and frequency during periods of elevated heat.
Analysis of affected processors shows some parts experience shifts in minimum operating voltages which may be related to operation outside of Intel® specified operating conditions.
While the root cause has not yet been identified, Intel® has observed the majority of reports of this issue are from users with unlocked/overclock capable motherboards.
Intel® has observed 600/700 Series chipset boards often set BIOS defaults to disable thermal and power delivery safeguards designed to limit processor exposure to sustained periods of high voltage and frequency, for example:
– Disabling Current Excursion Protection (CEP)
– Enabling the IccMax Unlimited bit
– Disabling Thermal Velocity Boost (TVB) and/or Enhanced Thermal Velocity Boost (eTVB)
– Additional settings which may increase the risk of system instability:
– Disabling C-states
– Using Windows Ultimate Performance mode
– Increasing PL1 and PL2 beyond Intel® recommended limits
Intel® requests system and motherboard manufacturers to provide end users with a default BIOS profile that matches Intel® recommended settings.
Intel® strongly recommends customer's default BIOS settings should ensure operation within Intel's recommended settings.
In addition, Intel® strongly recommends motherboard manufacturers to implement warnings for end users alerting them to any unlocked or overclocking feature usage.
Intel® is continuing to actively investigate this issue to determine the root cause and will provide additional updates as relevant information becomes available.
Intel® will be publishing a public statement regarding issue status and Intel® recommended BIOS setting recommendations targeted for May 2024.
One subtle undertone in this statement is that everything seems to revolve around motherboards, specifically their default settings. Looking to clarify matters, Intel has told me today that they aren't blaming motherboard vendors in the above statement to partners and OEMs. However, having had experience with multiple Z790 motherboards with Intel's Core i9-14900K, we know each vendor has a different idea of what the word 'default' means – and that none of them involve strictly sticking to Intel's own suggested values. These profiles within the firmware unlock power constraints to a very high level and go above and beyond what Intel recommends. One example is ICCMAX, which Intel recommends at 400A or below, whereas multiple Z790 motherboards will greatly exceed this value out of the box.
Impressing buyers and outperforming the competitors has become integral to every motherboard manufacturer's strategy, thanks to the highly competitive and commoditized nature of the motherboard market. As a result, the user experience is sometimes relegated to a low-priority goal. And while this focus on performance and overclocking features plays well in reviews and to overclockers and tinkerers looking to push their CPU to its very limit, as we are now seeing, it seems to have come at the cost of out-of-the-box stability, with overly-aggressive settings leading to systems being unstable even at default settings.
Especially concerning here is what all of this means for a CPU's VCore voltage, which is another aspect of system performance that motherboard vendors have complete control over. With the need to quickly modulate the VCore voltage to keep up with the load on the processor – to keep it high enough for stability, but not allow it to spike so high as to risk damage – it's a careful balancing act for motherboard vendors even when they're not trying to squeeze out every last bit of performance from a CPU. And when they are trying to squeeze out every last bit, then VCore is something to minimize in order to improve how long and hard a CPU can turbo, pushing a chip further towards potential instability.
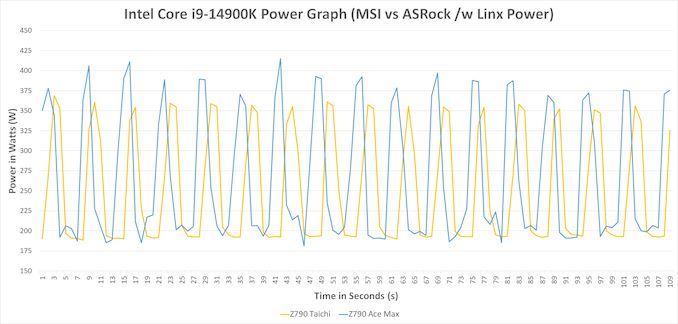
Pivoting to some real-world data highlighting these potential issues, when we reviewed the Intel Core i9-14900K, Intel's flagship Raptor Lake Refresh (RPL-R) processor, we tested with the default settings on both of our Z790 motherboards. From the above data, we can see the MSI MEG Z790 Ace Max was drawing up to 415 W when using Linx to place a very heavy workload on the chip. We also ran the same chip and workload on ASRock's Z790 Taichi Carrara to provide additional data points, where we found that it's power consumption maxed out at 375 W, around 10% lower than the MSI board.
In both cases, this is much higher than Intel's official PL2 limit for the Intel Core i9-14900K, which says that the chip should top out at 253 W for moderate periods of load. But, as we've seen time and time again, the official TDP ratings from Intel do not mean much to high-end motherboards, which almost universally default to higher settings. Motherboard vendors want to be competitive, and as such, higher default power settings allow vendors to claim that they deliver better performance than their rivals.
As further evidence of this, check out some of our recent motherboard reviews. I have assembled a small list of links to those reviews, where we've seen excessive CPU voltage or power consumption (or more often, both) when using the default settings on each motherboard, in each of the below reviews we see much higher power levels than Intel's official TDP values, which over the last several years we've come to expect. Still, some can be too high, especially with an already close-to-the-limit Core i9-14900K.
We have been communicating with Intel for most of the day to get official answers to what's happening. To that end, we have received an official statement from Intel, which reads as follows:
The recently publicized communications between Intel and its motherboard partners regarding motherboard settings and Intel Core 13th & 14th Gen K-SKU processors is intended to provide guidance on Intel recommended default settings. We are continuing to investigate with our partners the recent user reports of instability in certain workloads on these processors.
This BIOS default settings guidance is meant to improve stability for currently installed processors while Intel continues investigating root cause, not ascribe blame to Intel's partners:
Intel Raptor Lake (13th)/Raptor Lake Refresh (14th) Gen K Series SKU
Official Recommendations |
Parameter/Feature
(In BIOS/Software Settings) |
Value/Setting |
| Current Excursion Protection (CEP) |
Enable |
| Enhanced Thermal Velocity Boost (eTVB) |
Enable |
| Thermal Velocity Boost (TVB) |
Enable |
| TVB Voltage Optimizations |
Enable |
| ICCMAX Unlimited Bit |
Disable |
| TjMAX Offset |
0 |
| C-states |
Enable |
| ICCMAX |
Varies, Never >400A* |
| ICCMAX_App |
Varies* |
| Power Limits (PL's) |
Varies* |
* Please see the 13th Generation Intel® Core™ and Intel® Core™ 14th Generation Processors datasheet for more information
Intel continues to work with its partners to develop appropriate mitigations going forward.
Intel's official statement to us, which is likely their standpoint for the general public, highlights a list of recommended BIOS and software settings, such as those found in Intel's Extreme Tuning Utility (XTU). There's no mention of specific motherboard vendors or models, but the above settings should alleviate crashing and instability issues by preventing motherboards from pushing CPUs too hard.
It remains to be seen just how motherboard vendors will opt to address the issue, as all of the motherboard vendors we contacted today didn't have anything official to say about the matter. With that said, however, a few motherboard vendors have recently released a wave of new BIOSes, adding a new profile called "Intel Baseline" or similar. In all cases, these new BIOSes seem to do exactly what it says on the label, configuring the system to run at Intel's actual, suggested stock settings, and thus ensuring the stability of system in exchange for reduced performance.
With that said, these new Intel baseline settings are still not being used as the default settings for high-end motherboards. So the out-of-the-box user experience is still for MCE and other features to be enabled, pushing these processors to their performance limit. Users who actually want baseline performance – and the guaranteed stability it comes with – will still need to go into the BIOS and explicitly select this profile.
Ultimately, given the spec-defying state of high-end motherboards over the last decade, this is a badly-needed improvement. But still, as Intel has yet to wrap up their root cause investigation and issue formal guidance to consumers, we're not quite to the end of this saga just yet. There are still some developments to come, as we expect to hear more in May.