An introduction to Guidance: BabyAGI without OpenAI
- Twitter: theemozilla
- Jupyter Notebook: babyagi-without-openai-guidance.ipynb
Guidance¶
If you’re already convinced of how awesome Guidance is, you can skip this section
Guidance is a new template language from Microsoft that allows you to guide the output of lanugage models. This may not sound revolutionary on the surface, but if you’ve ever tried to compose together ouputs from a LM in a non-trivial manner and spent hours re-processing the same prompt or writing tons of boilerplate chaining code, Guidance really can be a next-level unlock.
One of the biggest frustrations when it comes to chaining LM outputs is trying to “force” the model to generate in a specific way, for example following certain steps or in a structure that’s easily programatically interpreted. Indeed, the classic chain-of-thought prompt (i.e. “let’s think about it step-by-step”) is merely a prompting technique to guide the model to reason about the task in a desireable way. But what if we could just like… make the model do what we want? That’s where Guidance comes in.
Guidance is essentially Handlebars templates for language models, where a magic gen command invokes the model in the context of the evaluated template up to this point.
As developers, we write the template structure of what we want the output of the model to be, and Guidance manages having the model “fill in the blanks”.
By way of illustration, consider:
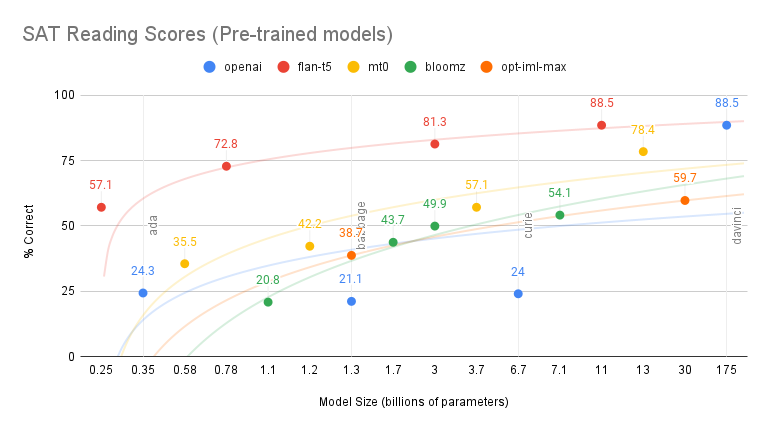
from IPython.display import Image from IPython.core.display import HTML Image(url="https://raw.githubusercontent.com/microsoft/guidance/main/docs/figures/json_animation.gif", width=376, height=234)

Here, the text on the white background is static, the blue background text represents variables passed in at runtime, and the green background text are the outputs generated by the language model. The Guidance code for this is:
The following is a character profile for an RPG game in JSON format.
```json
{
"id": "{{id}}",
"description": "{{description}}",
"name": "{{gen 'name'}}",
"age": {{gen 'age' pattern='[0-9]+' stop=','}},
"armor": "{{#select 'armor'}}leather{{or}}chainmail{{or}}plate{{/select}}",
"weapon": "{{select 'weapon' options=valid_weapons}}",
"class": "{{gen 'class'}}",
"mantra": "{{gen 'mantra' temperature=0.7}}",
"strength": {{gen 'strength' pattern='[0-9]+' stop=','}},
"items": [{{#geneach 'items' num_iterations=5 join=', '}}"{{gen 'this' temperature=0.7}}"{{/geneach}}]
}```
In Guidance we specify how we want our final text to look, using control statements such as gen to specify where the model should be used to generate specific pieces.
There are tons of different control statements — in the above example we use the select statement to choose between only a few options (underneath Guidance compares the log proabilities of the options and chooses the most likely one).
We can also specify regular expressions that define the valid form of an output (making strength be numeric).
The Guidance repo has tons of example notebooks that show off its various capabilities.
One thing I will say is that, as of this writing (May 2023) there is almost no formalized documentation as Guidance is still very much a work-in-progess.
I did all of my learning by looking through the example notebooks.
Local models in Guidance¶
One of the best things about Guidance is its first-class support of running on local models via transformers. I would go so far as to say that in Guidance local models are strictly better than using the OpenAI API (although it does support this as well). Perhaps its greatest feature from a quality-of-life perspective when using local models is “acceleration”.
Guidance acceleration works by caching the intermediate states of the model up to the boundary points within the template. When the the template is re-evaluated, Guidance can “skip ahead” to the point where the prompt actually changes. This greatly speeds up the core write-run-evaluate core developer loop when designing templates. If you’ve ever sat there re-running the same prompt for the ten thousandth time just to get to where you’ve made a change, then acceleration is truly a life saver.
BabyAGI¶
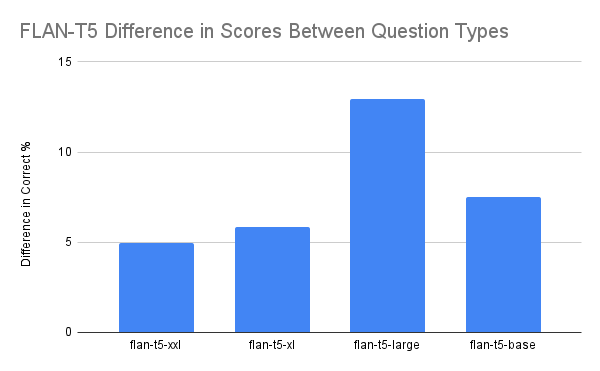
BabyAGI is a proof-of-concept “AGI”. In reality, it’s a task management system that uses a vector database and instructs the language model to plan out and exceute tasks aimed at completing a specific objective (for example, “paperclip the universe”).
Image(url="https://user-images.githubusercontent.com/21254008/235015461-543a897f-70cc-4b63-941a-2ae3c9172b11.png", width=496, height=367)

The reference BabyAGI code uses the OpenAI APIs.
I will refrain from editorializing here, but let’s just say I’d prefer to be able to do this using open source models  .
.
BabyAGI in Guidance¶
First, we need to install the prerequisites.
We’ll be using transformers and accelerate to run our local models and langchain, faiss-cpu, and sentence_transformers for embeddings and vector database.
!pip install transformers accelerate langchain faiss-cpu sentence_transformers ipywidgets
We’ll be using Vicuna as our language model. Vicuna has shown to be an excellent open-source competitor to GPT-3.5. It is a 13B parameter model finetuned from Llama.
Loading a 13B parameter model takes 52 GB of RAM when loaded at full precision or 26 GB at half precision.
transformers has the helpful load_in_8bit parameter that reduces this to 13 GB, but unfortunately Guidance doesn’t support this yet (until PR #8 merged).
I have a fork of Guidance that adds in support — install this if you want to use 8-bit quantization. Otherwise, the regular guidance package suffices.
# 8-bit quantization support !pip install git+https://github.com/jquesnelle/guidance@transformers-quantization-parameters bitsandbytes # or, regular guidance # !pip install guidance
Next, it’s time to load our model!
import guidance llm = guidance.llms.transformers.Vicuna( model="eachadea/vicuna-13b-1.1", device_map="auto", load_in_8bit=True )
We’ll use LangChain to help us with embeddings and vector databases.
The HuggingFaceEmbeddings class uses all-mpnet-base-v2 to generate embeddings, and we’ll use the simple FAISS vector database from Meta.
import faiss from langchain import InMemoryDocstore from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import FAISS embeddings_model = HuggingFaceEmbeddings(model_kwargs={"device": "cuda:0"}) embedding_size = 768 def make_vectorstore(): index = faiss.IndexFlatL2(embedding_size) return FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
Okay, let’s write some Guidance. BabyAGI has three core prompts: task execution, task creation, and task prioritization. We’ll start with the task execution prompt. The reference implementation can be found here.
execution_prompt = guidance(""" {{#system~}} {{llm.default_system_prompt}} {{~/system}} {{#user~}} You are an AI who performs one task based on the following objective: {{objective}}. Take into account these previously completed tasks: {{context}}. Your task: {{task}}. {{~/user}} {{#assistant~}} {{gen 'result'}} {{~/assistant~}} """)
Many models are “chat” trained.
That is to say, they’ve been finetuned to act as a chatbot.
To get the best performance out of these models, you need to prompt them in the same way that they were trained.
Unfortunately, each model has its own idiosyncrasies for this prompting.
Normally, this would mean you would need different prompts for each model.
However, Guidance solves this by the special #system, #user, and #assistant commands.
Several popular models are supported (Vicuna, StableLM, MPT) and adding support for a new model is a simple subclass.
Once supported, the same prompt can be used across different chat trained models.
In this prompt, objective, context, and task are variables we’ll pass in at runtime.
We’ll generate the result variable, which will be accessible as a property of the returned object when we call execution_prompt.
def get_top_tasks(vectorstore, query, k): results = vectorstore.similarity_search_with_score(query, k=k) if not results: return [] sorted_results, _ = zip(*sorted(results, key=lambda x: x[1], reverse=True)) return [str(item.page_content) for item in sorted_results] def execute_task(vectorstore, objective, task, k=5): context = get_top_tasks(vectorstore=vectorstore, query=objective, k=k) \ if vectorstore is not None else [] return execution_prompt(objective=objective, context=context, task=task, llm=llm)["result"]
sample_objective = "Write a weather report for SF today" FIRST_TASK = "Write a todo list to complete the objective" sample_execute_task = execute_task(vectorstore=None, objective=sample_objective, task=FIRST_TASK) sample_execute_task
systemA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.userYou are an AI who performs one task based on the following objective: Write a weather report for SF today. Take into account these previously completed tasks: []. Your task: Write a todo list to complete the objective.assistant1. Gather current weather data for San Francisco. 2. Analyze data to determine current weather conditions in San Francisco. 3. Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed. 4. Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns. 5. Organize the information in a logical and easy-to-understand format. 6. Review and edit the weather report for accuracy and clarity. 7. Present the weather report in a professional and engaging manner.
'1. Gather current weather data for San Francisco.\n2. Analyze data to determine current weather conditions in San Francisco.\n3. Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed.\n4. Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.\n5. Organize the information in a logical and easy-to-understand format.\n6. Review and edit the weather report for accuracy and clarity.\n7. Present the weather report in a professional and engaging manner.'
When executing in a Jupyter notebook, Guidance automatically presents the output in an easily digestable format.
We can see the seperate system, user, and assistant sections and see where runtime varabiles were inserted (blue) ana the model generated new text (green).
Every variable that is created via gen is available in the result object directly — already parsed!
Next up is the task creation prompt. A large part of the reference implementation is concerned with cleaning up the response from the model, and hoping (praying) it will follow instructions regarding how to structure the output so it can be programatically iterepreted. But, this is just the task the Guidance excels at!
Our goal is to have the model take whatever the output of the previous task was and create a list of tasks to carry out the objective. This is done iteratively, so we pass in any previously incomplete tasks, and ask the model for new tasks. While we politely ask the model to output the tasks as an array, with Guidance we can actually make it happen.
creation_prompt = guidance(""" {{#system~}} {{llm.default_system_prompt}} {{~/system}} {{#user~}} You are a task creation AI that uses the result of an execution agent to create new tasks with the following objective: {{objective}}. The last completed task has the result: {{result}}. This result was based on this task description: {{task_description}}. These are the incomplete tasks: {{incomplete_tasks}}. Based on the result, create new tasks to be completed by the AI system that do not overlap with the incomplete tasks. {{~/user}} {{#assistant~}} ```json [{{#geneach 'tasks' stop="]"}}{{#unless @first}}, {{/unless}}"{{gen 'this'}}"{{/geneach}}] ``` {{~/assistant~}} """)
The geneach command tells Guidance to do a looped generation, creating a list of tasks.
By placing geneach inside of [""] we can enforce a JSON array structure (the unless command is used to add neccessary commas).
def create_tasks(result, task_description, task_list, objective): response = creation_prompt( result=result, task_description=task_description, incomplete_tasks=task_list, objective=objective, llm=llm ) new_tasks = [task for task in response["tasks"] if task not in task_list] return [{"task_name": task_name} for task_name in new_tasks if task_name.strip()] sample_created_tasks = create_tasks( result=sample_execute_task, task_description=FIRST_TASK, task_list=[], objective=sample_objective ) sample_created_tasks
systemA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.userYou are a task creation AI that uses the result of an execution agent to create new tasks with the following objective: Write a weather report for SF today. The last completed task has the result: 1. Gather current weather data for San Francisco. 2. Analyze data to determine current weather conditions in San Francisco. 3. Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed. 4. Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns. 5. Organize the information in a logical and easy-to-understand format. 6. Review and edit the weather report for accuracy and clarity. 7. Present the weather report in a professional and engaging manner.. This result was based on this task description: Write a todo list to complete the objective. These are the incomplete tasks: []. Based on the result, create new tasks to be completed by the AI system that do not overlap with the incomplete tasks.assistant```json ["Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed.", "Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.", "Organize the information in a logical and easy-to-understand format.", "Review and edit the weather report for accuracy and clarity.", "Present the weather report in a professional and engaging manner."] ```
[{'task_name': 'Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed.'},
{'task_name': 'Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.'},
{'task_name': 'Organize the information in a logical and easy-to-understand format.'},
{'task_name': 'Review and edit the weather report for accuracy and clarity.'},
{'task_name': 'Present the weather report in a professional and engaging manner.'}]
Our tasks correctly generated and parsed!
We then place these in a dictionary under the key task_name for later use in the full BabyAGI procedure.
The last prompt to write is the task prioritization prompt.
prioritization_prompt = guidance(""" {{#system~}} {{llm.default_system_prompt}} {{~/system}} {{#user~}} You are a task prioritization AI tasked with cleaning the formatting of and reprioritizing the following tasks: {{task_names}}. Consider the ultimate objective of your team: {{objective}}. Do not remove any tasks. Return the result as a numbered list, like: #. First task #. Second task Start the task list with number {{next_task_id}}. {{~/user}} {{#assistant~}} {{#geneach 'tasks'}}{{#if (equal @index last_task_index)}}{{break}}{{/if}}{{add @index next_task_id}}. {{gen 'this' stop="\\n"}} {{/geneach}} {{~/assistant~}} """)
In the task creation prompt we asked the model to output the tasks as a JSON array. Now we’ll try a harder use case: an ordered numerical list starting with some arbitrary number.
Based on experience, the model often hallucinates here and invents new tasks or repeats them.
However, we want it to simply re-order the exisiting tasks.
While this could be solved with a redesigned prompt or a more aligned model, we can also use the if command to control the number of tasks that can be outputted and stop after a predetermined number.
Here, we compare the special @index of the current task being generated (a magic number updated by Guidance after each loop) and break out if it’s equal to the number of tasks we know we passed in.
def prioritize_tasks(this_task_id, task_list, objective): task_names = [t["task_name"] for t in task_list] next_task_id = int(this_task_id) + 1 response = prioritization_prompt( task_names=task_names, next_task_id=next_task_id, objective=objective, last_task_index=len(task_names) - 1, llm=llm ) return [ {"task_id": task_id, "task_name": task_name} for task_id, task_name in zip(range(next_task_id, next_task_id+len(task_list)), response["tasks"]) ] sample_prioritized_tasks = prioritize_tasks( this_task_id=1, task_list=sample_created_tasks, objective=sample_objective, ) sample_prioritized_tasks
systemA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.userYou are a task prioritization AI tasked with cleaning the formatting of and reprioritizing the following tasks: ['Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed.', 'Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.', 'Organize the information in a logical and easy-to-understand format.', 'Review and edit the weather report for accuracy and clarity.', 'Present the weather report in a professional and engaging manner.']. Consider the ultimate objective of your team: Write a weather report for SF today. Do not remove any tasks. Return the result as a numbered list, like: #. First task #. Second task Start the task list with number 2.assistant2. Review and edit the weather report for accuracy and clarity. 3. Organize the information in a logical and easy-to-understand format. 4. Present the weather report in a professional and engaging manner. 5. Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed. 6. Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.
[{'task_id': 2,
'task_name': 'Review and edit the weather report for accuracy and clarity.'},
{'task_id': 3,
'task_name': 'Organize the information in a logical and easy-to-understand format.'},
{'task_id': 4,
'task_name': 'Present the weather report in a professional and engaging manner.'},
{'task_id': 5,
'task_name': 'Write a clear and concise weather report for San Francisco based on the data gathered and analysis completed.'},
{'task_id': 6,
'task_name': 'Include any relevant information about the forecast for the rest of the day and any potential weather-related hazards or concerns.'}]
Now it’s time for the full BabyAGI procedure. It may be helpful to refer back to the diagram that shows the flow of logic, but essentially it’s our three prompts being run in succession.
from collections import deque def babyagi(objective, max_iterations=5): task_list = deque([{ "task_id": 1, "task_name": FIRST_TASK }]) task_id_counter = 1 vectorstore = make_vectorstore() while max_iterations is None or max_iterations > 0: if task_list: # Step 1: Pull the first task task = task_list.popleft() # Step 2: Execute the task result = execute_task( vectorstore=vectorstore, objective=objective, task=task["task_name"] ) this_task_id = int(task["task_id"]) # Step 3: Store the result result_id = f"result_{task['task_id']}" vectorstore.add_texts( texts=[result], metadatas=[{"task": task["task_name"]}], ids=[result_id], ) # Step 4: Create new tasks new_tasks = create_tasks( result=result, task_description=task["task_name"], task_list=[t["task_name"] for t in task_list], objective=objective, ) for new_task in new_tasks: task_id_counter += 1 new_task.update({"task_id": task_id_counter}) task_list.append(new_task) # Step 5: Reprioritize task list task_list = deque( prioritize_tasks( this_task_id, list(task_list), objective, ) ) max_iterations = None if max_iterations is None else max_iterations - 1 return result
babyagi("Write a weather report for Detroit today", max_iterations=4)
systemA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.userYou are a task prioritization AI tasked with cleaning the formatting of and reprioritizing the following tasks: ['Make any necessary updates to the report based on new data or changes in the weather conditions', 'Ensure the report is accurate and up-to-date', 'Evaluate the effectiveness of the written report and visual graphic in conveying the weather information to the audience', 'Analyze the gathered weather data to determine the current weather conditions', 'Write a clear and concise weather report for Detroit, including temperature, precipitation, wind speed and direction, and any other relevant information', 'Determine the current weather conditions in Detroit', 'Write a clear and concise weather report for Detroit, including temperature, precipitation, wind speed and direction, and any other relevant information', 'Prioritize the tasks based on their importance and urgency to achieve the ultimate objective of writing a weather report for Detroit today.', 'Execute the tasks in the order of priority.']. Consider the ultimate objective of your team: Write a weather report for Detroit today. Do not remove any tasks. Return the result as a numbered list, like: #. First task #. Second task Start the task list with number 5.assistant5. Prioritize the tasks based on their importance and urgency to achieve the ultimate objective of writing a weather report for Detroit today. 6. Execute the tasks in the order of priority. 7. Write a clear and concise weather report for Detroit, including temperature, precipitation, wind speed and direction, and any other relevant information. 8. Determine the current weather conditions in Detroit. 9. Evaluate the effectiveness of the written report and visual graphic in conveying the weather information to the audience. 10. Make any necessary updates to the report based on new data or changes in the weather conditions. 11. Analyze the gathered weather data to determine the current weather conditions. 12. Ensure the report is accurate and up-to-date. 13. Write a clear and concise weather report for Detroit, including temperature, precipitation, wind speed and direction, and any other relevant information.
'Here is the weather report for Detroit:\n\nTemperature: The temperature in Detroit today is expected to reach a high of 75 degrees Fahrenheit and a low of 55 degrees Fahrenheit.\n\nPrecipitation: There is a chance of scattered thunderstorms throughout the day, with a 30% chance of precipitation.\n\nWind: The wind speed in Detroit today is expected to be light, with an average speed of 5-10 miles per hour. The wind is blowing from the southwest.\n\nOther relevant information: The humidity in Detroit today is expected to be around 60%, and the atmospheric pressure is 29.94 inches of mercury.\n\nPlease note that this weather report is based on current data and is subject to change. It is always a good idea to check the weather forecast before making any plans.\n\nIf you would like a visual graphic of the weather report, please let me know and I will be happy to provide one.'
And there you have it, BabyAGI in Guidance using only local, open source models!
Hopefully this was a helpful introduction. Likely this will quickly get outdated as Guidance is under very active development.