Modern military shooters are in a strange place at the moment. Battlefield is licking its wounds after stepping on the landmine that was Battlefield 2042, while Call of Duty is running around like the dog that caught the car, the massive success of Warzone leaving the mainline series at a loss with what to do with itself.
It's a chaotic, uncertain time in one of multiplayer gaming's biggest spheres, and the various shenanigans of EA and Activision have left room for something new to make its mark in the genre. Enter Delta Force: Hawk Ops, which you'll be shocked to hear is not a Trauma Team-style game about performing surgery on birds of prey. Instead, it's a free-to-play military shooter in the Battlefield/CoD mould, based on the series that predates either, and it could be the shot of competence and stability that the genre sorely needs.
Currently running a month-long Alpha, Hawk Ops provides access to two of its three game modes. The first of these, Havoc Warfare, is a classic large-scale attack/defence scenario similar to Battlefield's Rush, with the attacking team trying to capture a linear sequence of control points, and the defending team attempting to hold back the tide until the attackers' collective pool of lives runs dry.
It's about to kick off in the centre of Kuttenberg, the sprawling medieval city at the heart of Kingdom Come: Deliverance 2. Menhard the sword master has offered to teach protagonist Henry of Skalitz a few tricks with the blade, but the lesson has been interrupted by Kuttenberg's official fencing …
The Fourth Amendment's protection against unreasonable searches and seizures extends to the length of a seizure, a federal court ruled last week, significantly restricting how long law enforcement can retain private property after an arrest.
"When the government seizes property incident to a lawful arrest, the Fourth Amendment requires that any continued possession of the property must be reasonable," wrote Judge Gregory Katsas of the U.S. Court of Appeals for the District of Columbia in a unanimous ruling.
Most courts of appeal to pass judgment on the issue—namely, the 1st, 2nd, 6th, 7th, and 11th circuits—have held that, once an item is seized, law enforcement can retain the item indefinitely without violating the Fourth Amendment. These precedents have allowed police to retain personal property without clear legal grounds, effectively stripping people of their property rights merely because they were arrested. The D.C. Court of Appeals' ruling complicates this general consensus.
Though law enforcement does not have to return property "instantaneously," Katsas wrote, the Fourth Amendment requires that any "continuing retention of seized property" be reasonable. So while police can use seized items for "legitimate law-enforcement purposes," such as for evidence at trial, and are permitted some delay for "matching a person with his effects," prolonged seizures serving no important function can implicate the Fourth Amendment, the court ruled.
Given that the D.C. court finds itself in the minority on the question, some say that the case may be primed for the Supreme Court if the District chooses to appeal. "This case has potential to make national precedent," Paul Belonick, a professor at the University of California, San Francisco law school, tells Reason. "The influential D.C. Circuit deliberately intensified a circuit split and put itself in the minority of circuits on the question, teeing it up cleanly for certiorari."
The plaintiffs each had their property seized by D.C.'s Metropolitan Police Department (MPD). Five of the plaintiffs were arrested during a Black Lives Matter protest in the Adams Morgan neighborhood of D.C. on August 13, 2020.
As they were arrested, MPD officers seized their phones and other items. Though the protesters did not face any charges and were, in Katsas' words, "quickly released," MPD retained their phones for around a year. Some of the plaintiffs had to wait over 14 months to get their property back.
In the meantime, the plaintiffs say that they were forced to replace their phones and lost access to the important information on the originals, including personal files, contacts, and passwords. "The plaintiffs have alleged that the seizures at issue, though lawful at their inception, later came to unreasonably interfere with their protected possessory interests in their own property," Katsas explained.
"MPD is aware of the ruling and will continue to work with our partners at the United States Attorney's Office to ensure that our members are trained appropriately to ensure compliance with recent rulings," a spokesperson for MPD tells Reason.
"Practically, this case is important because police have been exploiting a gap in the Fourth Amendment," Andrew Ferguson, a professor at American University's Washington College of Law, tells Reason. "In situations where there is a lawful arrest, but no prosecution, there are no clear rules on retaining personal property. In these cases, police have been confiscating phones to punish protestors."
Michael Perloff, the lead attorney for the plaintiffs, agreed that the D.C. Circuit's decision could set an important precedent going forward. "Nationally, we've seen litigants attempt to challenge similar practices only to fail because the court concluded that the Fourth Amendment does not limit the duration of a seizure," he tells Reason. "Moving forward, we are hopeful that the D.C. Circuit's opinion will lead courts to reconsider those rulings and, instead, enforce the Fourth Amendment as fully as the framers intended."
404k followers on Twitch @anniefuchsia on socials AnnieFucsia’s Favorite Games to Stream AnnieFuchsia is mainly a World of Warcraft streamer however she does play other games like Cyberpunk 2077 and most recently she powered through the main storyline in the new Avatar Frontiers of Pandora game all while dressed in full Navi costume. Viewer Engagement and […]
One of my less openly talked about guilty pleasures that I happily delve into is WWII battle simulators. Ever since Battlefield 1942 came out, the scale of the battles was something that I really immersed myself into and delivered countless hours of enjoyment. After BF42, I found that the WWII airplane simulators were especially my […]
One of the reasons why I don’t consider Chivalry II a traditional “hack and slash” is because I think it takes a bit of skill to play the game effectively. Unlike “hack and slashes” like God of war, for instance, mashing buttons can get you just as far as well executed skill moves
408k followers Maximum is one of the more popular streamers on Twitch exclusively playing World of Warcraft. As a sponsored member of team Liquid, some of his videos have over 1 million views on Twitch, which is no small feat. Several other of his past streams have over 500k views each. Maximum is no stranger […]
A selfie drone that makes the case for ditching GPS, obstacle avoidance, and controllers.
I’ve played around with a few DJI drones over the years but always found them to be too cumbersome to master and use spontaneously. The $349 HoverAir X1 from Zero Zero Robotics is different. This so-called “selfie drone” is so easy to use that it’s already an indispensable tool for my work and play, right out of the box.
For example, the HoverAir X1 is responsible for this review photo, this 360-degree GIF, and this overhead shot, as well as all of the follow, orbit, and zoom in / out shots used in this ID Buzz e-camper review. Each shot was made with just a touch of a button on the top of the X1 — no controller required — including all the drone footage used in this e-bikepacking video.
The best drone is the one you have with you and the ultra-lightweight HoverAir X1 can easily fit inside a pocket to be taken everywhere. It launches so quickly that I can impulsively grab a more interesting drone shot instead of just defaulting to my iPhone. It returns automatically to land in your hand.
The HoverAir X1 is not without limitations, and I did manage to break one review unit after falling on it. But I have to admit I love this little guy precisely because of its shortcomings, not in spite of them.
The HoverAir X1’s flying weight is about half that of DJI’s sub-250g Mini drones, so it, too, is exempt from registration and licensing requirements in most countries. It folds up into a 5 x 3.4 x 1.2-inch (127 x 86 x 31mm) package that’s so small and lightweight that I could comfortably carry it in a thigh pocket on long bike rides or trail runs.
The primary user interface for the X1 is two buttons on the drone itself. One turns the unit on, and the other cycles through five presets that lock the camera onto the user as the drone completes a predetermined flight path, shooting video or taking photos along the way:
Hover — floats in fixed space and tracks your movement
Follow — flies behind or in front of you at different heights and distances
Orbit — makes a wide circle overhead around a fixed center spot
Zoom out — flies away and up and then back in
Bird’s eye — for top-down shots directly over a fixed spot
There’s also a sixth mode that lets you assign a lightly customized flight pattern. The hover and follow modes can record videos or take photos for several minutes at a time, while the other flight modes begin and end at the point of launch and last for about 30 seconds.
The HoverAir app lets you tweak each of its automatic flight modes, including the altitude, distance, swapping between photo or video captures, portrait or landscape, and image quality. After some early experimentation to see what I liked, I rarely had to adjust these again.
In a metric I like to call “time to drone,” I can pull the X1 out of a pocket, unfold it, turn it on, select a predefined flight path, and set it aloft from an outstretched palm in less than 20 seconds. No DJI drone can come anywhere close.
The collapsed HoverAir X1 and battery vs. DJI Mini 3 Pro, battery, and controller.
And now expanded.
That’s not to say that the HoverAir can compete with DJI’s consumer drones on features or capabilities. The X1’s diminutive size means compromises were made, starting with a max video resolution of 2.7K/30fps.
Shots also start looking a little shaky in light winds around 10 knots (5.1m/s), and the X1 can’t even fly once winds exceed a moderate 15 knots (7.7m/s). It’s also relatively slow. The X1 can track me fine on a trail run, but it’ll start losing its object lock when I’m road biking at a not-very-fast pace of just 12mph (20km/h). Even when it can keep up, it’ll lose me when the elevation changes rapidly on a steep climb or descent.
Otherwise, the X1’s computer vision tracking is very good — it’s the main reason you’d buy this drone. But when it does lose track of me for whatever reason, it’ll just stop, hover in place, and then eventually land, even over water or a busy street. There is no return-to-home feature to ensure a safe landing and recovery. It can, however, be configured to play a sound to help find it.
The protective cage is built to expand and contract upon impact.
The X1 also lacks any obstacle avoidance. Instead, the drone’s four rotors are encased in a flexible plastic cage to protect the device from collisions. In most flight modes, the lack of avoidance tech isn’t really a problem so long as you give the immediate area a quick survey. It becomes an issue when the drone is in follow-me mode through narrow tree-lined trails, for example, or when walking around a sharp corner inside my home. Usually, it’ll just stop and hover in place if it runs into something, meaning I’ll have to double back to re-engage the tracking lock on my person or to collect it. But if it hits something when going faster — like chasing me on a bike — it’ll crash. My review X1 has already survived a few dozen crashes that sent it plummeting to the ground. It’s fine, other than a few scuff marks.
I did destroy another X1 when my full weight landed on it while testing some new clipless bike pedals (don’t judge!). The X1 is not indestructible, but it’s surprisingly robust for such a lightweight drone.
The HoverAir X1 also lacks any kind of advanced GPS positioning. Instead, it opts for a VIO (Visual Inertial Odometry) system to estimate its position in 3D space, indoors or out, so that its preset flight modes can return the drone to its original starting point. It worked very well in my testing, often living up to the HoverAir’s claim of “centimeter-level precision,” even when flying orbits around me with a 20-foot (six-meter) radius.
The drone also responds to a variety of hand gestures when the user is standing still. For example, you can send the X1 left or right with a wave of an arm or tell it to land with your arms crossed overhead. You can also just grab the drone out of the air and flip it upside down to turn those protected rotors off.
The HoverAir X1 does offer a manual Wi-Fi-connected flight mode whereby your phone becomes the controller. It’s fun, but I found it unresponsive at times, making it difficult to control flight with any real precision. I consider it a bonus feature you might want to use in a pinch.
The X1 is limited to 32GB of built-in storage without any option for microSD expansion. I’m currently using just 8.8GB to store the 113 videos and 60 images I’ve shot at max resolution over the last few months of testing. The footage transfers quickly to a phone over a direct Wi-Fi connection using the HoverAir app or over USB-C to a laptop. That USB-C connection will also charge the X1’s battery in about 55 minutes.
Hover mode selected and recording.
On paper, the X1 is dumb and unremarkable. But the HoverAir is so good at doing what many people actually need from a drone that its shortcomings rarely matter at all.
DJI is still the king of sweeping panoramas, but the HoverAir X1 makes a strong case for being the drone you choose to capture yourself doing things — indoors and out — especially for social media.
I do wish it was more capable so I could trust it to capture action over water when kitesurfing on windy days, keep up with me when road cycling at pace, or maintain its object lock when I’m bombing down a steep hill on a mountain bike. A 4K/60fps shooting mode would also be nice so long as none of these wishes increase the price too much.
Still, the X1 does 90 percent of what I want a drone to do without adding GPS, obstacle avoidance sensors, and a physical controller that’ll just make everything more expensive, more complicated, more cumbersome to carry, and slower to launch. Maybe DJI’s rumored Neo will fill in that last 10 percent because it certainly looks like a response to the HoverAir hype.
The HoverAir X1 lists for $429, but it’s nearly always on sale somewhere, often at or below $350. But I’d recommend opting for the $400-ish bundle that adds a dual-battery quick charger and two extra batteries that each only last about 10 to 12 minutes before needing a 35-minute recharge. Like the X1 itself, they’re so small and lightweight that you can easily bring them along to help document your next activity.
Apple is once again the focus of the EU’s competition policy. | Cath Virginia / The Verge
Apple’s App Store “steering” policies violate the EU’s Digital Markets Act meant to encourage competition, said regulators in their preliminary ruling Monday. The European Commission has also opened a new investigation into Apple’s support for alternative iOS marketplaces in Europe, including the core technology fee it charges developers.
“Our preliminary position is that Apple does not fully allow steering,” said Margrethe Vestager who heads up competition policy in Europe. “Steering is key to ensure that app developers are less dependent on gatekeepers’ app stores and for consumers to be aware of better offers.”
Under the DMA, Apple and other so-called gatekeepers must allow app developers to steer consumers to offers outside their app stores free of charge. Alphabet, Amazon, Apple, ByteDance, Meta, and Microsoft are the six gatekeepers who had to be fully compliant with rules as of March 2024.
“Throughout the past several months, Apple has made a number of changes to comply with the DMA in response to feedback from developers and the European Commission,” said Apple spokesperson Peter Ajemian in a statement sent to The Verge. “All developers doing business in the EU on the App Store have the opportunity to utilize the capabilities that we have introduced, including the ability to direct app users to the web to complete purchases at a very competitive rate. As we have done routinely, we will continue to listen and engage with the European Commission.”
Apple is the first to be charged under the DMA rules after the EU’s competition authority opened several investigations in March. (Meta and Google are also being scrutinized for noncompliance.) Apple has time to respond to the European Commission’s preliminary assessment ahead of its final ruling before March 2025. Apple could be fined up to 10 percent of its annual global revenue for infringement, or $38 billion based on last year’s numbers. That increases to 20 percent for repeat infringements.
Today we open a new case + we adopt preliminary findings against @Apple under the DMA.
We are concerned Apple's new business model makes it too hard for app developers to operate as alternative marketplaces & reach their end users on iOS.
The European Commission has also opened new proceedings into Apple’s support for alternative iOS app stores. The investigation is focused on the contentious Core Technology Fee, the laborious multistep process required for users to install the third-party marketplaces, and Apple’s eligibility requirements for developers.
“We have also opened proceedings against Apple in relation to its so-called core technology fee and various rules for allowing third party app stores and sideloading,” said Vestager. “The developers’ community and consumers are eager to offer alternatives to the App Store. We will investigate to ensure Apple does not undermine these efforts.”
On Friday, Apple blamed “regulatory uncertainties” related to the DMA for delaying the rollout of cornerstone iOS 18 features to European users this year. Apple blamed interoperability requirements that could undermine user privacy and data security.
Update, June 24th: Added Apple’s statement regarding anti-steering ruling.
Last month when Google introduced its new AI search tool, called AI Overviews, the company seemed confident that it had tested the tool sufficiently, noting in the announcement that “people have already used AI Overviews billions of times through our experiment in Search Labs.” The tool doesn’t just return links to Web pages, as in a typical Google search, but returns an answer that it has generated based on various sources, which it links to below the answer. But immediately after the launch users began posting examples of extremely wrong answers, including a pizza recipe that included glue and the interesting fact that a dog has played in the NBA.
Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.
While the pizza recipe is unlikely to convince anyone to squeeze on the Elmer’s, not all of AI Overview’s extremely wrong answers are so obvious—and some have the potential to be quite harmful. Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory and has a new book out about the online propagandists who “turn lies into reality.” She has studied the spread of medical misinformation via social media, so IEEE Spectrum spoke to her about whether AI search is likely to bring an onslaught of erroneous medical advice to unwary users.
I know you’ve been tracking disinformation on the Web for many years. Do you expect the introduction of AI-augmented search tools like Google’s AI Overviews to make the situation worse or better?
Renée DiResta: It’s a really interesting question. There are a couple of policies that Google has had in place for a long time that appear to be in tension with what’s coming out of AI-generated search. That’s made me feel like part of this is Google trying to keep up with where the market has gone. There’s been an incredible acceleration in the release of generative AI tools, and we are seeing Big Tech incumbents trying to make sure that they stay competitive. I think that’s one of the things that’s happening here.
We have long known that hallucinations are a thing that happens with large language models. That’s not new. It’s the deployment of them in a search capacity that I think has been rushed and ill-considered because people expect search engines to give them authoritative information. That’s the expectation you have on search, whereas you might not have that expectation on social media.
There are plenty of examples of comically poor results from AI search, things like how many rocks we should eat per day [a response that was drawn for an Onion article]. But I’m wondering if we should be worried about more serious medical misinformation. I came across one blog post about Google’s AI Overviews responses about stem-cell treatments. The problem there seemed to be that the AI search tool was sourcing its answers from disreputable clinics that were offering unproven treatments. Have you seen other examples of that kind of thing?
DiResta: I have. It’s returning information synthesized from the data that it’s trained on. The problem is that it does not seem to be adhering to the same standards that have long gone into how Google thinks about returning search results for health information. So what I mean by that is Google has, for upwards of 10 years at this point, had a search policy called Your Money or Your Life. Are you familiar with that?
I don’t think so.
DiResta: Your Money or Your Life acknowledges that for queries related to finance and health, Google has a responsibility to hold search results to a very high standard of care, and it’s paramount to get the information correct. People are coming to Google with sensitive questions and they’re looking for information to make materially impactful decisions about their lives. They’re not there for entertainment when they’re asking a question about how to respond to a new cancer diagnosis, for example, or what sort of retirement plan they should be subscribing to. So you don’t want content farms and random Reddit posts and garbage to be the results that are returned. You want to have reputable search results.
That framework of Your Money or Your Life has informed Google’s work on these high-stakes topics for quite some time. And that’s why I think it’s disturbing for people to see the AI-generated search results regurgitating clearly wrong health information from low-quality sites that perhaps happened to be in the training data.
So it seems like AI overviews is not following that same policy—or that’s what it appears like from the outside?
DiResta: That’s how it appears from the outside. I don’t know how they’re thinking about it internally. But those screenshots you’re seeing—a lot of these instances are being traced back to an isolated social media post or a clinic that’s disreputable but exists—are out there on the Internet. It’s not simply making things up. But it’s also not returning what we would consider to be a high-quality result in formulating its response.
I saw that Google responded to some of the problems with a blog post saying that it is aware of these poor results and it’s trying to make improvements. And I can read you the one bullet point that addressed health. It said, “For topics like news and health, we already have strong guardrails in place. In the case of health, we launched additional triggering refinements to enhance our quality protections.” Do you know what that means?
DiResta: That blog posts is an explanation that [AI Overviews] isn’t simply hallucinating—the fact that it’s pointing to URLs is supposed to be a guardrail because that enables the user to go and follow the result to its source. This is a good thing. They should be including those sources for transparency and so that outsiders can review them. However, it is also a fair bit of onus to put on the audience, given the trust that Google has built up over time by returning high-quality results in its health information search rankings.
I know one topic that you’ve tracked over the years has been disinformation about vaccine safety. Have you seen any evidence of that kind of disinformation making its way into AI search?
DiResta: I haven’t, though I imagine outside research teams are now testing results to see what appears. Vaccines have been so much a focus of the conversation around health misinformation for quite some time, I imagine that Google has had people looking specifically at that topic in internal reviews, whereas some of these other topics might be less in the forefront of the minds of the quality teams that are tasked with checking if there are bad results being returned.
What do you think Google’s next moves should be to prevent medical misinformation in AI search?
DiResta: Google has a perfectly good policy to pursue. Your Money or Your Life is a solid ethical guideline to incorporate into this manifestation of the future of search. So it’s not that I think there’s a new and novel ethical grounding that needs to happen. I think it’s more ensuring that the ethical grounding that exists remains foundational to the new AI search tools.
Strap in, pilot. It’s time to slingshot to new worlds. Whether you want to go farther than any Robloxian has gone before, discover the frigidly beautiful Ice World, or just need a boost and a cargo hold full of gems, let’s brief you with these Launch Into Space Simulatorcodes.
Selaco describes itself as a first-person shooter inspired by 1993's Doom and 2005's F.E.A.R. But to be perfectly honest, I think that undersells it. This wildly ambitious retro FPS plays like a potted history of the genre's golden age, melding all manner of ideas that emerged between the two key texts it cites as inspiration. The holistic worldbuilding of System Shock. The playful interactivity of Duke Nukem 3D. The crisp set-piece design of Half-Life. Selaco blends them all into a smooth, unctuous action experience. It's already one of the best retro shooters out there, and the damn thing's only a third finished.
You play as Dawn, a Security Captain aboard the titular Selaco (which I think is pronounced Sell-a-co, but I habitually say Sil Acko because I am irredeemably northern). Selaco is a gargantuan space station designed to look, sound, and smell exactly like Earth in the year 2255, because actual Earth has been devastated by some unspecified cataclysm. Selaco is the primary home of the surviving human race, then, but now it has been struck with a disaster of its own, as it's attacked by a force of purple-blooded supersoldiers.
None of this is clear at the game's start, however, with Dawn awakening in the guts of Selaco's Pathfinder Memorial hospital (following treatment for, amusingly, a pulled hamstring), which is already under heavy assault by heavily armed goons. The abrupt and somewhat unforgiving introduction sees you scrambling through the hospital's corridors as they rattle with nearby explosions, dodging gunfire as your enemies hunt you down. After a minute or two of breathless evasion, you finally pick up a weapon, moments before the soldiers kick down the door of the room you've just crawled into.
Across Europe and beyond, teams of young people are receiving data from the International Space Station (ISS) this week. That’s because they participated in the annual European Astro Pi Challenge, the unique programme we deliver in collaboration with ESA Education to give kids the chance to write code that runs in space.
The Astro Pi computers inside the International Space Station.
In this round of Astro Pi, over 26,400 young people took part across its two missions — Mission Space Lab and Mission Zero — and had their programs run on the Raspberry Pi computers on board the ISS.
Mission Space Lab teams find out the speed of the ISS
In Mission Space Lab, we asked young people to team up and write code to collect data on the ISS and calculate the speed at which the ISS is travelling. 236 teams wrote programs that passed all our tests and achieved flight status to run in space. And not only will the Mission Space Lab teams receive their participation certificates this week — they’ll also receive the data their programs captured on the ISS.
A picture of the Himalayas taken from space by the Astro Pi computers.
Many teams chose a feature extraction method to calculate the ISS’s speed, identifying two points on Earth from which to calculate the distance the ISS travelled over time. Using this method means using the high-quality camera on the Astro Pi computer to take some fantastic photos of Earth from the ISS’s World Observation Research Facility (WORF) window. Teams will receive these photos soon, which are unique views of Earth from space.
Feature extraction between two images
How fast does the ISS travel?
The actual speed that the ISS is travelling in space while at normal altitude is 7.66km/s. Its altitude can affect the speed, so it can vary, but the ISS’s boosters fire up if it dips too low.
To help teams with writing programs that can adapt to some of these variances, and to show them the type data they can collect, we gave them a programming tool we call Astro Pi Replay. Using this tool, teams can simulate how their program would run on the Astro Pi computers up in space.
The International Space Station orbiting Earth
This is the first time we asked Mission Space Lab teams to focus on a particular scientific question. So how did they do? The graph below shows some of the speeds that teams’ programs estimated.
The range of speeds calculated by Mission Space Lab teams
As you can see, a variety of speeds were estimated, but the average is fairly close to the ISS’s actual speed. Teams did a great job trying to solve the question and working like real space scientists. Once they receive their data this week, they can check how accurate their speed estimate was.
Mission Zero pixel art lights up astronauts’ daily tasks
In Astro Pi Mission Zero, a coding activity suitable for beginners, 16,039 teams of young people created code to make pixel art inspired by nature. Nearly half (44%) of the 24,409 participants were girls! 15,942 of the Mission Zero teams had their code run on the ISS after we checked that it followed the rules.
Mission Zero Submissions
Every team whose program ran on the ISS — with their pixel art showing for the astronauts to see as they worked — will receive certificates with the time, date, and location coordinates of their Mission Zero run.
We’ve been so impressed with this year’s pixel art creations that we’ve picked some as new examples for next year’s Mission Zero coding guide. That means young people will be able to choose one of a few pixel images to start with and recreate or remix them for their program. More info on that is coming soon, sign up to the Astro Pi newsletter to not miss it.
Let’s get ready for September
Thank you and congratulations to everyone who took part in the missions this year, and our special thanks to all the amazing educators who ran Astro Pi activities with young people.
The south of Italy photographed from space by the Astro Pi computers
For us, there is much to reflect on and celebrate from this year’s challenge. We’ve had the chance to run Mission Zero with young people in person and identify a few changes to help make the activity easier. As Mission Space Lab now involves simulating programs running on the ISS with our new Astro Pi Replay tool, we’ll be exploring how to improve this as well.
We hope to engage lots of previous and new participants in the Astro Pi Challenge when it starts up again in September. Sign up for the newsletter on astro-pi.org to be the first to hear about the new round.
Louisiana Gov. Jeff Landry last week signed a law that criminalizes approaching police officers within 25 feet, provided that the officer tells any would-be approachers to stand back, effectively creating a legal force field that law enforcement can activate at their discretion.
"No person shall knowingly or intentionally approach within twenty-five feet of a peace officer who is lawfully engaged in the execution of his official duties after the peace officer has ordered the person to stop approaching or to retreat," the law states. Offenders could receive a $500 fine and be jailed for up to 60 days.
The bill was authored by state Reps. Bryan Fontenot (R–Thibodaux), Michael T. Johnson (R–Pineville), and Roger Wilder (R–Denham Springs). Fontenotargued that the legislation would give law enforcement officials "peace of mind" as they carry out their duties. That's the same argument Florida Gov. Ron DeSantis made to justify signing Senate Bill 184 in April, which criminalizes approaching within 25 feet of a first responder with the intent to threaten, harass, or interfere with the official.
But some opponents of these laws believe they are overly broad and unnecessary.
"Requiring a 25-foot distance from a police officer may not be a practical or effective approach in many situations," state Rep. Delisha Boyd (D–New Orleans) tells Reason. "Policing situations vary widely, and a blanket requirement for a 25-foot distance may not account for the diverse scenarios officers encounter. Who on the scene will determine what exactly is 25 feet away? What happens if within that 25 feet is on my personal property?"
Louisiana already has a law outlawing "interfering with a law enforcement investigation." Critics of the new law say that an additional law proscribing the simple act of approaching police is superfluous.
One such critic is Meghan Garvey, the legislative chair and former president of the Louisiana Association of Criminal Defense Lawyers. Police work "is already protected from interference by current law," she tells Reason. "The measure criminalizes citizens for engaging in constitutionally protected activity and discourages citizen oversight of law enforcement."
The law, "like many other bills brought this session, seeks to make Louisianans more subservient to government," Garvey concludes.
The Louisiana Legislature passed a similar bill, House Bill 85, in June 2023, but that measure was vetoed by former Gov. John Bel Edwards. "The effect of this bill were it to become law would be to chill exercise of First Amendment rights and prevent bystanders from observing and recording police action," Edwards said in a statement explaining his veto.
Though the Supreme Court has declined to address the issue, there is significant legal precedent in the circuit courts—including in the 5th Circuit, which contains Louisiana—that the First Amendment's press and speech clauses collectively safeguard a "right to record the police." Last year, a federal judge struck down an Arizona measure that outlawed filming police from within 8 feet after receiving a verbal warning because it "prohibits or chills a substantial amount of First Amendment protected activity and is unnecessary to prevent interference with police officers given other Arizona laws in effect."
In Louisiana, "an officer could be arresting someone in a manner indicating excessive force, have a bystander approach to record the arrest, and the bystander could then be immediately told by the officer 'to stop approaching or to retreat,' chilling the bystander's right to record," Louisiana attorney Philip Adams tells Reason. "Thus, the bystander could be placed in a position in which the First Amendment right to record could be functionally neutered."
Sharing this solar generator’s batteries with a 3-in-1 solar fridge, freezer, and ice-making combo is a good idea that might get better.
Solar generators and battery-powered fridges are highly desirable additions to vans, boats, cabins, and sheds, or anywhere power and refrigeration is needed off the grid. Both are meant to be portable by necessity but suffer from the same issue: weight.
Bluetti just started shipping its SwapSolar kit that pairs an AC180T solar generator with its MultiCooler, a 3-in-1 solar-powered fridge, freezer, and ice maker. What makes this kit interesting is that the MultiCooler and AC180T devices can share the same B70 LFP batteries, which can be charged inside either device when plugged into your car’s 12V socket, a standard power outlet, or solar panels.
This modular approach has some other interesting benefits, too:
Divide these heavy devices into multiple components for easier transport.
Worry less about charging batteries or buying bigger ones by getting as many B70 batteries as you need to cover your average roadtrip, workday, or home blackout.
Repair or replace just the battery or the unit it powers should something go wrong or upgrades become available.
Building a modular ecosystem of products around small interchangeable batteries has already seen success by makers of handheld power tools. Bluetti is expanding the concept to devices needed for extended off-grid living, with more SwapSolar products coming.
Great, but first we need to see if the devices shipping today can independently justify the total price of the $2,000 SwapSolar kit.
Editor’s note: When this review was finished, we went back to take one last photo and discovered that the MultiCooler would not turn on for reasons explained below. We are therefore withholding its score until Bluetti can assure us it’s not a widespread defect.
The SwapSolar B70 battery at the heart of these systems holds 716.8Wh of energy and is built using LFP chemistry. LFP — short for lithium iron phosphate — batteries last longer, are safer, and work in a wider range of operating temperatures than the smaller and lighter NMC-based batteries they’re rapidly replacing. The B70 should hold 80 percent of its original charging capacity, even after 3,000 cycles.
Bluetti will sell you as many B70 batteries as you’d like, but right now, they only work with the AC180T solar generator and MultiCooler. The AC180T can be powered by one or two batteries, while the MultiCooler fits only one.
The AC180T solar generator fitted with two hot-swappable B70 batteries will continue charging my laptop uninterrupted after one battery is removed to power the MultiCooler.
MultiCooler
The 3-in-1 MultiCooler (model F045D) refrigerator, freezer, and ice maker is very similar to the EcoFlow Glacier I reviewed last year. However, the MultiCooler lacks EcoFlow’s dual-zone feature that lets you divide the main compartment into both a freezer and fridge that can run simultaneously. That could be a deal-breaker for some. On the other hand, Bluetti’s MultiCooler runs longer on battery and is usually a little quieter.
Noise is a critical factor for any device that runs all night within earshot of your bed in an RV, cabin, or boat. Bluetti’s MultiCooler is thankfully nearly silent until the compressor kicks in. Then it gets about as loud as a home theater projector, or about 35dB in my testing, as it cools the unit down. Cooling is relatively slow, however. Even with the refrigeration mode set to Max in the Bluetti app, it took 23 minutes to go from room temperature to 6 degrees Celsius / 43 degrees Fahrenheit and then another 17 minutes to reach -10C / 14F. That’s slower, but quieter, than the EcoFlow Glacier.
Bluetti consistently reported a lower temperature than my own trusty thermometer during testing. For example, my thermometer placed inside the unit read -8C / 17.6F when the app and MultiCooler display read -10C / 14F, and when the MultiCooler said it was 3C / 37.4F, the thermometer read 5C / 41F. At least it was consistently inconsistent, which is something I can work around.
Smart plug visualization showing the MultiCooler operating as a refrigerator before 11AM and freezer after. Each power spike corresponds to the compressor coming on to cool the device. It used 308Wh from the wall jack on this particular day.
The unit goes almost completely silent once it hits your defined temperature set in the app or on the physical display, interrupted by a few bubbles and scratches now and again that likely won’t be too annoying for most people. The compressor runs for about 10 minutes at around 33dB, followed by 20- to 40-minute gaps of near silence in my testing. It turns on with what sounds like five distinct clicks of a mechanical button and turns off with a slight rattle that’s noticeable when empty (the lightweight food baskets inside the fridge shake).
Ice making is a much noisier affair, as you’d expect, and occurs in its own dedicated compartment — not in the freezer. The first batch of ice takes about 23 minutes as the MultiCooler produces a loud 48dB from a distance of one meter. The noise is constant and only stops about one minute before the ice drops into the bucket. Each batch thereafter is just as loud but only takes about 12 minutes. You can select between small or large ice, which yields a sheet of two dozen small (or less small) hollow cubes. It can produce ice continuously until the one-liter water reservoir is empty — that’s about 100 cubes. In my testing, the ice was about half melted after being left in the closed bucket for six hours.
One quirk of making ice is that Bluetti stops cooling the main compartment to do it. That should be fine in all but the hottest environments, so long as the lid is left closed. To test the quality of the insulation, I turned off the MultiCooler that had been operating for a day at -10C / 14F while half full of frozen food. According to the app, it measured -8C / 17.6F after one hour, -6C / 21.2 F after two hours, and -5C / 23F after three hours. It was still at 1C / 34F some 14 hours later.
Battery life is very good. In Max refrigeration mode, I was able to bring the temperature down to -10C / 14F, make four batches of ice, and then maintain that temperature for 36 hours before a recharge was needed. In Eco mode, I started the timer when the temperature was already -10C / 14F, made two batches of ice, and maintained the temperature for 40 hours before the battery died. In both cases, the battery quit inelegantly with an E1 error (low battery voltage protection) at about 5 percent charge left. Bluetti tells me “this is normal” which is... come on.
Bluetti provides adapters to power the MultiCooler by three other methods: a 12V / 24V DC connection to a car socket; a standard AC wall jack; or up to 200W of direct connected solar panels, but only if there’s a battery inside. Bluetti didn’t provide any charging data like watts, voltage, and current when I connected a 200W solar panel to the MultiCooler — it just shows it charging on the display and in the app. The unit can make ice no matter how the unit is powered, unlike the EcoFlow Glacier.
The MultiCooler includes a handle and wheels as standard, which make it relatively easy to transport over flat ground when fully loaded. It’s still heavy even without the B70 battery installed, and the wheels are rather small, resulting in limited ground clearance — that means occasionally having to drag the MultiCooler over rougher terrains.
Unfortunately, as I was wrapping up this review, I found that the MultiCooler would not turn on after sitting idle for about a week. It is now back with Bluetti, and a preliminary report suggests that my issue was caused by a heatsink detaching from a MOS tube — a critical voltage control element on the MultiCooler’s circuitry — possibly as a result of rough handling during shipment. Bluetti will now determine if this is a one-off situation or a general defect that requires changes in the manufacturing and assembly process.
We will update this review and add a MultiCooler score when we get the final analysis from Bluetti.
I should also note that while 3-in-1 fridge, freezer, and ice-making combos are impressive in all they can do, they are also expensive compared to simple 12V portable car fridges that cost less than half as much. But those won’t make ice from the power of the Saharan sun, so what’s even the point?
AC180T
The AC180T solar generator is a nicely designed power station with a built-in MPPT charge controller to connect solar panels. Nearly all the outputs and display can be conveniently found on the front, with the AC input on the side. A lid on the top hides the two B70 slots, which are keyed to ensure the batteries are inserted correctly, for a total capacity of 1.43kWh.
For context, 1.43kWh is enough to keep a 6000BTU window air conditioner (400W) running for about six hours, boil about 35 liters of water from a 1000W electric kettle, or keep a Starlink internet from space system running for about a day and a half.
Bluetti’s modular approach really helps to divvy up the weight of the AC180T. Each 5.3 × 6.3 × 13.8in / 134 × 160 × 350mm battery weighs 18.7lbs / 8.5kg, which brings the total weight of the AC180T up to 58.4lbs / 26.5kg when both are inserted — that’s a lot for most people to carry.
When plugged into an AC wall jack and in the fastest “Turbo” mode, charging two batteries from zero to 100 percent took 77 minutes and produced about 44dB of noise (from one meter away) while drawing 1.4kW from the grid. Charging in Standard mode still produced 44dB but pulled only 920W, while Silent mode dropped things down to 37dB and 735W. Charging a single battery in Turbo mode took 66 minutes and pulled a steady 860W. In all cases, charging began to slow down at around 95 percent full, as you’d expect.
I also tested Bluetti’s claim that the AC180T can produce up to 1200W of continuous AC output with one battery inserted or up to 1800W with two hot-swappable batteries.
With one battery installed, I was able to run a microwave at around 1250W for three minutes without issue, but a 2100W hair dryer resulted in an inverter overload, causing it to shut down for safety. I then added the second battery and plugged in the same hair dryer, which ran fine at a steady 1874W, until I plugged in a 1200W toaster for a total load of 3074W, which quickly shut down the inverter with another overload. No smells, no funny noises, no mess, as you’d hope. So, both tests passed.
To test the hot-swappable claim, I started the 1250W microwave with two batteries inserted. It continued to run as I removed and reinserted one of the batteries. I then unplugged the microwave and plugged in the hair dryer, drawing 900W, which continued to blow as I removed and reinserted a battery. I then bumped the heat to max (drawing over 1850W) with two batteries installed, pulled one, and the hair dryer shut off within seconds. Good.
As with all power stations, the AC inverter will drain the battery when left on. With no load attached and the AC output turned on, my two AC180T batteries (1.43kWh) dropped 30 percent in 24 hours. That works out to about 17.92Wh lost per hour, or a steady 18W just to power the inverter, which is fairly efficient. Still, you should enable Bluetti’s AC Eco mode (on by default) to automatically turn off the AC inverter after a user-defined time of low or no load. Otherwise, those fully charged batteries will die in just over three days.
For what it’s worth, I was able to plug the MultiCooler directly into the 12V / 10A DC car jack on the AC180T with the included cable, which obviates the need to swap batteries if you can keep the units close together. You can also power the fridge off the AC180T’s AC port, of course, but DC is more efficient (no wasteful inverter).
The Bluetti app is fine, but it’s cluttered with promotions and only works with the MultiCooler and AC180T over Bluetooth, not Wi-Fi like EcoFlow’s products. That means you’ll have to be nearby to check on your battery status or to adjust temperatures.
Me writing this review from a remote workplace flanked by a Bluetti AC180T solar generator and MultiCooler to keep my Negroni on ice.
Conclusion
On their own, the SwapSolar AC180T solar generator and MultiCooler 3-in-1 fridge are each very competitive products — assuming, of course, that the defect on my MultiCooler review unit was an isolated issue. If so, then Bluetti’s SwapSolar kit is a winning combination.
Regardless, I hope to see Bluetti’s modular ecosystem approach adopted by competitors like EcoFlow, Jackery, and others. A company called Runhood has already been selling less powerful solar generators with modular batteries and accessories for over a year.
What SwapSolar is missing, however, is a small portable charging accessory to independently charge each B70 battery. Bluetti’s Evelyn Zou tells me that a “base” is in development to do exactly that. Then you only need to bring the base and battery into a shop, cafe, or gym to get things charged, instead of conspicuously dragging in the entire fridge or solar generator. The base will also convert the B70 battery into a standalone power source for your USB gadgets. Zou says that Bluetti is looking to expand the SwapSolar ecosystem in the future and is “actively working on new products.” But those are just promises for now, with no dates or prices.
Ideally, owners of the AC180T and MultiCooler and any other SwapSolar device could even upgrade to compatible batteries with improved chemistry over time. Or maybe it opens up a market to cheaper third-party alternatives. We’ll see!
Bluetti is selling the AC180T directly for $1,099. But the MultiCooler is still in that weird Indiegogo “indemand” phase — which means you’ll have to wait until August, according to Bluetti, if you prefer to buy directly from the company and avoid all the Indiegogo “perk” nonsense. The AC180T is covered by a five-year warranty, which drops to two years for the MultiCooler.
For the MultiCooler, my advice is to wait or look elsewhere until Bluetti explains itself.
The SwapSolar MultiCooler and AC180T combo kit is currently priced at $1,999 on Indiegogo. That sounds about right given that a comparable system from EcoFlow that combines the Glacier 3-in-1 fridge with a less powerful River 2 Pro solar generator currently sells for $1,499 or $2,799 when paired with a more powerful Delta 2 Max. The AC180T lists for $999 while the MultiCooler can be purchased separately for $799 (without a B70 battery).
Stephen Cass: Hello. I’m Stephen Cass, Special Projects Director at IEEE Spectrum. Before starting today’s episode hosted by Eliza Strickland, I wanted to give you all listening out there some news about this show.
This is our last episode of Fixing the Future. We’ve really enjoyed bringing you some concrete solutions to some of the world’s toughest problems, but we’ve decided we’d like to be able to go deeper into topics than we can in the course of a single episode. So we’ll be returning later in the year with a program of limited series that will enable us to do those deep dives into fascinating and challenging stories in the world of technology. I want to thank you all for listening and I hope you’ll join us again. And now, on to today’s episode.
Eliza Strickland: Hi, I’m Eliza Strickland for IEEE Spectrum‘s Fixing the Future podcast. Before we start, I want to tell you that you can get the latest coverage from some of Spectrum’s most important beats, including AI, climate change, and robotics, by signing up for one of our free newsletters. Just go to spectrum.IEEE.org/newsletters to subscribe.
Around the world, about 60 countries are contaminated with land mines and unexploded ordnance, and Ukraine is the worst off. Today, about a third of its land, an area the size of Florida, is estimated to be contaminated with dangerous explosives. My guest today is Gabriel Steinberg, who co-founded both the nonprofit Demining Research Community and the startup Safe Pro AI with his friend, Jasper Baur. Their technology uses drones and artificial intelligence to radically speed up the process of finding land mines and other explosives. Okay, Gabriel, thank you so much for joining me on Fixing the Future today.
Gabriel Steinberg: Yeah, thank you for having me.
Strickland: So I want to start by hearing about the typical process for demining, and so the standard operating procedure. What tools do people use? How long does it take? What are the risks involved? All that kind of stuff.
Steinberg: Sure. So humanitarian demining hasn’t changed significantly. There’s been evolutions, of course, since its inception and about the end of World War I. But mostly, the processes have been the same. People stand from a safe location and walk around an area in areas that they know are safe, and try to get as much intelligence about the contamination as they can. They ask villagers or farmers, people who work around the area and live around the area, about accidents and potential sightings of minefields and former battle positions and stuff. The result of this is a very general idea, a polygon, of where the contamination is. After that polygon and some prioritization based on danger to civilians and economic utility, the field goes into clearance. The first part is the non-technical survey, and then this is clearance. Clearance happens one of three ways, usually, but it always ends up with a person on the ground basically doing extreme gardening. They dig out a certain standard amount of the soil, usually 13 centimeters. And with a metal detector, they walk around the field and a mine probe. They find the land mines and nonexploded ordnance. So that always is how it ends.
To get to that point, you can also use mechanical assets, which are large tillers, and sometimes dogs and other animals are used to walk in lanes across the contaminated polygon to sniff out the land mines and tell the clearance operators where the land mines are.
Strickland: How do you hope that your technology will change this process?
Steinberg: Well, my technology is a drone-based mapping solution, basically. So we provide a software to the humanitarian deminers. They are already flying drones over these areas. Really, it started ramping up in Ukraine. The humanitarian demining organizations have started really adopting drones just because it’s such a massive problem. The extent is so extreme that they need to innovate. So we provide AI and mapping software for the deminers to analyze their drone imagery much more effectively. We hope that this process, or our software, will decrease the amount of time that deminers use to analyze the imagery of the land, thereby more quickly and more effectively constraining the areas with the most contamination. So if you can constrain an area, a polygon with a certainty of contamination and a high density of contamination, then you can deploy the most expensive parts of the clearance process, which are the humans and the machines and the dogs. You can deploy them to a very specific area. You can much more cost-effectively and efficiently demine large areas.
Strickland: Got it. So it doesn’t replace the humans walking around with metal detectors and dogs, but it gets them to the right spots faster.
Steinberg: Exactly. Exactly. At the moment, there is no conception of replacing a human in demining operations, and people that try to push that eventuality are usually disregarded pretty quickly.
Strickland: How did you and your co-founder, Jasper, first start experimenting with the use of drones and AI for detecting explosives?
Steinberg: So it started in 2016 with my partner, Jasper Baur, doing a research project at Binghamton University in the remote sensing and geophysics lab. And the project was to detect a specific anti-personnel land mine, thePFM-1. Then found— it’s a Russian-made land mine. It was previously found in Afghanistan. It still is found in Afghanistan, but it’s found in much higher quantities right now in Ukraine. And so his project was to detect the PFM-1 anti-personnel land mine using thermal imagery from drones. It sort of snowballed into quite an intensive research project. It had multiple papers from it, multiple researchers, some awards, and most notably, it beat NASA at a particular Tech Briefs competition. So that was quite a morale boost.
And at some point, Jasper had the idea to integrate AI into the project. Rightfully, he saw the real bottleneck as not the detecting of land mines in drone imagery, but the analysis of land mines in drone imagery. And that really has become— I mean, he knew, somehow, that that would really become the issue that everybody is facing. And everybody we talked to in Ukraine is facing that issue. So machine learning really was the key for solving that problem. And I joined the project in 2018 to integrate machine learning into the research project. We had some more papers, some more presentations, and we were nearing the end of our college tenure, of our undergraduate degree, in 2020. So at that time– but at that time, we realized how much the field needed this. We started getting more and more into the mine action field, and realizing how neglected the field was in terms of technology and innovation. And we felt an obligation to bring our technology, really, to the real world instead of just a research project. There were plenty of research projects about this, but we knew that it could be more and that it should. It really should be more. And we felt we had the– for some reason, we felt like we had the capability to make that happen.
So we formed a nonprofit, the Demining Research Community, in 2020 to try to raise some funding for this project. Our for-profit end of that, of our endeavors, was acquired by a company called Safe Pro Group in 2023. Yeah, 2023, about one year ago exactly. And the drone and AI technology became Safe Pro AI and our flagship product spotlight. And that’s where we’re bringing the technology to the real world. The Demining Research Community is providing resources for other organizations who want to do a similar thing, and is doing more research into more nascent technologies. But yeah, the real drone and AI stuff that’s happening in the real world right now is through Safe Pro.
Strickland: So in that early undergraduate work, you were using thermal sensors. I know now the Spotlight AI system is using more visual. Can you talk about the different modalities of sensing explosives and the sort of trade-offs you get with them?
Steinberg: Sure. So I feel like I should preface this by saying the more high tech and nascent the technology is, the more people want to see it apply to land mine detection. But really, we have found from the problems that people are facing, by far the most effective modality right now is just visual imagery. People have really good visual sensors built into their face, and you don’t need a trained geophysicist to observe the data and very, very quickly get actionable intelligence. There’s also plenty of other benefits. It’s cheaper, much more readily accessible in Ukraine and around the world to get built-in visual sensors on drones. And yeah, just processing the data, and getting the intelligence from the data, is way easier than anything else.
I’ll talk about three different modalities. Well, I guess I could talk about four. There’s thermal, ground penetrating radar, magnetometry, and lidar. So thermal is what we started with. Thermal is really good at detecting living things, as I’m sure most people can surmise. But it’s also pretty good at detecting land mines, mostly large anti-tank land mines buried under a couple millimeters, or up to a couple centimeters, of soil. It’s not super good at this. The research is still not super conclusive, and you have to do it at a very specific time of day, in the morning and at night when, basically the soil around the land mine heats up faster than the land mine and you cause a thermal anomaly, or the sun causes a thermal anomaly. So it can detect things, land mines, in some amount of depth in certain soils, in certain weather conditions, and can only detect certain types of land mines that are big and hefty enough. So yeah, that’s thermal.
Ground penetrating radar is really good for some things. It’s not really great for land mine detection. You have to have really expensive equipment. It takes a really long time to do the surveys. However, it can get plastic land mines under the surface. And it’s kind of the only modality that can do that with reliability. However, you need to train geophysicists to analyze the data. And a lot of the time, the signatures are really non-unique and there’s going to be a lot of false positives. Magnetometry is the other-- by the way, all of this is airborne that I’m referring to. Ground-based GPR and magnetometry are used in demining of various types, but airborne is really what I’m talking about.
For magnetometry, it’s more developed and more capable than ground penetrating radar. It’s used, actually, in the field in Ukraine in some scenarios, but it’s still very expensive. It needs a trained geophysicist to analyze the data, and the signatures are non-unique. So whether it’s a bottle can or a small anti-personnel land mine, you really don’t know until you dig it up. However, I think if I were to bet on one of the other modalities becoming increasingly useful in the next couple of years, it would be airborne magnetometry.
Lidar is another modality that people use. It’s pretty quick, also very expensive, but it can reliably map and find surface anomalies. So if you want to find former fighting positions, sometimes an indicator of that is a trench line or foxholes. Lidar is really good at doing that in conflicts from long ago. So there’s a paper that theHALO Trust published of flyinga lidar mission over former fighting positions, I believe, in Angola. And they reliably found a former trench line. And from that information, they confirmed that as a hazardous area. Because if there is a former front line on this position, you can pretty reliably say that there is going to be some explosives there.
Strickland: And so you’ve done some experiments with some of these modalities, but in the end, you found that the visual sensor was really the best bet for you guys?
Steinberg: Yeah. It’s different. The requirements are different for different scenarios and different locations, really. Ukraine has a lot of surface ordnance. Yeah. And that’s really the main factor that allows visual imagery to be so powerful.
Strickland: So tell me about what role machine learning plays in your Spotlight AI software system. Did you create a model trained on a lot of— did you create a model based on a lot of data showing land mines on the surface?
Steinberg: Yeah. Exactly. We used real-world data from inert, non-explosive items, and flew drone missions over them, and did some physical augmentation and some programmatic augmentation. But all of the items that we are training on are real-life Russian or American ordnance, mostly. We’re also using the real-world data in real minefields that we’re getting from Ukraine right now. That is, obviously, the most valuable data and the most effective in building a machine learning model. But yeah, a lot of our data is from inert explosives, as well.
Strickland: So you’ve talked a little bit about the current situation in Ukraine, but can you tell me more about what people are dealing with there? Are there a lot of areas where the battle has moved on and civilians are trying to reclaim roads or fields?
Steinberg: Yeah. So the fighting is constantly ongoing, obviously, in eastern Ukraine, but I think sometimes there’s a perspective of a stalemate. I think that’s a little misleading. There’s lots of action and violence happening on the front line, which constantly contaminates, cumulatively, the areas that are the front line and the gray zone, as well as areas up to 50 kilometers back from both sides. So there’s constantly artillery shells going into villages and cities along the front line. There’s constantly land mines, new mines, being laid to reinforce the positions. And there’s constantly mortars. And everything is constant. In some fights—I just watched the video yesterday—one of the soldiers said you could not count to five without an explosion going off. And this is just one location in one city along the front. So you can imagine the amount of explosive ordnance that are being fired, and inevitably 10, 20, 30 percent of them are sometimes not exploding upon impact, on top of all the land mines that are being purposely laid and not detonating from a vehicle or a person. These all just remain after the war. They don’t go anywhere. So yeah, Ukraine is really being littered with explosive ordnance and land mines every day.
This past year, there hasn’t been terribly much movement on the front line. But in the Ukrainian counteroffensive in 2020— I guess the last major Ukrainian counteroffensive where areas of Mykolaiv, which is in the southeast, were reclaimed, the civilians started repopulating the city almost immediately. There are definitely some villages that are heavily contaminated, that people just deserted and never came back to, and still haven’t come back to after them being liberated. But a lot of the areas that have been liberated, they’re people’s homes. And even if they’re destroyed, people would rather be in their homes than be refugees. And I mean, I totally understand that. And it just puts the responsibility on the deminers and the Ukrainian government to try to clear the land as fast as possible. Because after large liberations are made, people want to come back almost all the time. So it is a very urgent problem as the lines change and as land is liberated.
Strickland: And I think it was about a year ago that you and Jasper went to the Ukraine for a technology demonstration set up by the United Nations. Can you tell about that, and what the task was, and how your technology fared?
Steinberg: Sure. So yeah, the United Nations Development Program invited us to do a demonstration in northern Ukraine to see how our technology, and other technologies similar to it, performed in a military training facility in Ukraine. So everybody who’s doing this kind of thing, which is not many people, but there are some other organizations, they have their own metrics and their own test fields— not always, but it would be good if they did. But the UNDP said, “No, we want to standardize this and try to give recommendations to the organizations on the ground who are trying to adopt these technologies.” So we had five hours to survey the field and collect as much data as we could. And then we had 72 hours to return the results. We—
Strickland: Sorry. How big was the field?
Steinberg: The field was 25 hectares. So yeah, the audience at home can type 25 hectares to amount of football fields. I think it’s about 60. But it’s a large area. So we’d never done anything like that. That was really, really a shock that it was that large of an area. I think we’d only done half a hectare at a time up to that point. So yeah, it was pretty daunting. But we basically slept very, very little in those 72 hours, and as a result, produced what I think is one of the best results that the UNDP got from that test. We didn’t detect everything, but we detected most of the ordnance and land mines that they had laid. We also detected some that they didn’t know were there because it was a military training facility. So there were some mortars being fired that they didn’t know about.
Strickland: And I think Jasper told me that you had to sort of rewrite your software on the fly. You realized that the existing approach wasn’t going to work and you had to do some all-nighter to recode?
Steinberg: Yeah. Yeah, I remember us sitting in a Georgian restaurant— Georgia, the country, not the state, and racking our brain, trying to figure out how we were going to map this amount of land. We just found out how big the area was going to be and we were a little bit stunned. So we devised a plan to do it in two stages. The first stage was where we figured out in the drone images where the contaminated regions were. And then the second stage was to map those areas, just those areas. Now, our software can actually map the whole thing, and pretty casually too. So not to brag. But at the time, we had lots less development under our belt. And yeah, therefore we just had to brute force it through Georgian food and brainpower.
Strickland: You and Jasper just got back from another trip to the Ukraine a couple of weeks ago, I think. Can you talk about what you were doing on this trip, and who you met with?
Steinberg: Sure. This trip was much less stressful, although stressful in different ways than the UNDP demo. Our main objectives were to see operations in action. We had never actually been to real minefields before. We’d been in some perhaps contaminated areas, but never in a real minefield where you can say, “Here was the Russian position. There are the land mines. Do not go there.” So that was one of the main objectives. That was very powerful for us to see the villages that were destroyed and are denied to the citizens because of land mines and unexploded ordnance. It’s impossible to describe how that feels being there. It’s really impactful, and it makes the work that I’m doing feel not like I have a choice anymore. I feel very much obligated to do my absolute best to help these people.
Strickland: Well, I hope your work continues. I hope there’s less and less need for it over time. But yeah, thank you for doing this. It’s important work. And thanks for joining me on Fixing the Future.
Steinberg: My pleasure. Thank you for having me.
Strickland: That was Gabriel Steinberg speaking to me about the technology that he and Jasper Baur developed to help rid the world of land mines. I’m Eliza Strickland, and I hope you’ll join us next time on Fixing the Future.
Theory of mind—the ability to understand other people’s mental states—is what makes the social world of humans go around. It’s what helps you decide what to say in a tense situation, guess what drivers in other cars are about to do, and empathize with a character in a movie. And according to a new study, the large language models (LLM) that power ChatGPT and the like are surprisingly good at mimicking this quintessentially human trait.
“Before running the study, we were all convinced that large language models would not pass these tests, especially tests that evaluate subtle abilities to evaluate mental states,” says study coauthor Cristina Becchio, a professor of cognitive neuroscience at the University Medical Center Hamburg-Eppendorf in Germany. The results, which she calls “unexpected and surprising,” were published today—somewhat ironically, in the journal Nature Human Behavior.
The results don’t have everyone convinced that we’ve entered a new era of machines that think like we do, however. Two experts who reviewed the findings advised taking them “with a grain of salt” and cautioned about drawing conclusions on a topic that can create “hype and panic in the public.” Another outside expert warned of the dangers of anthropomorphizing software programs.
The researchers are careful not to say that their results show that LLMs actually possess theory of mind.
Becchio and her colleagues aren’t the first to claim evidence that LLMs’ responses display this kind of reasoning. In a preprint paper posted last year, the psychologist Michal Kosinski of Stanford University reported testing several models on a few common theory-of-mind tests. He found that the best of them, OpenAI’s GPT-4, solved 75 percent of tasks correctly, which he said matched the performance of six-year-old children observed in past studies. However, that study’s methods were criticized by other researchers who conducted follow-up experiments and concluded that the LLMs were often getting the right answers based on “shallow heuristics” and shortcuts rather than true theory-of-mind reasoning.
The authors of the present study were well aware of the debate. “Our goal in the paper was to approach the challenge of evaluating machine theory of mind in a more systematic way using a breadth of psychological tests,” says study coauthor James Strachan, a cognitive psychologist who’s currently a visiting scientist at the University Medical Center Hamburg-Eppendorf. He notes that doing a rigorous study meant also testing humans on the same tasks that were given to the LLMs: The study compared the abilities of 1,907 humans with those of several popular LLMs, including OpenAI’s GPT-4 model and the open-source Llama 2-70b model from Meta.
How to Test LLMs for Theory of Mind
The LLMs and the humans both completed five typical kinds of theory-of-mind tasks, the first three of which were understanding hints, irony, and faux pas. They also answered “false belief” questions that are often used to determine if young children have developed theory of mind, and go something like this: If Alice moves something while Bob is out of the room, where will Bob look for it when he returns? Finally, they answered rather complex questions about “strange stories” that feature people lying, manipulating, and misunderstanding each other.
Overall, GPT-4 came out on top. Its scores matched those of humans for the false-belief test, and were higher than the aggregate human scores for irony, hinting, and strange stories; it performed worse than humans only on the faux pas test. Interestingly, Llama-2’s scores were the opposite of GPT-4’s—it matched humans on false belief, but had worse-than-human performance on irony, hinting, and strange stories and better performance on faux pas.
“We don’t currently have a method or even an idea of how to test for the existence of theory of mind.” —James Strachan, University Medical Center Hamburg-Eppendorf
To understand what was going on with the faux pas results, the researchers gave the models a series of follow-up tests that probed several hypotheses. They came to the conclusion that GPT-4 was capable of giving the correct answer to a question about a faux pas, but was held back from doing so by “hyperconservative” programming regarding opinionated statements. Strachan notes that OpenAI has placed many guardrails around its models that are “designed to keep the model factual, honest, and on track,” and he posits that strategies intended to keep GPT-4 from hallucinating (that is, making stuff up) may also prevent it from opining on whether a story character inadvertently insulted an old high school classmate at a reunion.
Meanwhile, the researchers’ follow-up tests for Llama-2 suggested that its excellent performance on the faux pas tests were likely an artifact of the original question and answer format, in which the correct answer to some variant of the question “Did Alice know that she was insulting Bob”? was always “No.”
The researchers are careful not to say that their results show that LLMs actually possess theory of mind, and say instead that they “exhibit behavior that is indistinguishable from human behavior in theory of mind tasks.” Which raises the question: If an imitation is as good as the real thing, how do you know it’s not the real thing? That’s a question social scientists have never tried to answer before, says Strachan, because tests on humans assume that the quality exists to some lesser or greater degree. “We don’t currently have a method or even an idea of how to test for the existence of theory of mind, the phenomenological quality,” he says.
Critiques of the Study
The researchers clearly tried to avoid the methodological problems that caused Kosinski’s 2023 paper on LLMs and theory of mind to come under criticism. For example, they conducted the tests over multiple sessions so the LLMs couldn’t “learn” the correct answers during the test, and they varied the structure of the questions. But Yoav Goldberg and Natalie Shapira, two of the AI researchers who published the critique of the Kosinski paper, say they’re not convinced by this study either.
“Why does it matter whether text-manipulation systems can produce output for these tasks that are similar to answers that people give when faced with the same questions?” —Emily Bender, University of Washington
Goldberg made the comment about taking the findings with a grain of salt, adding that “models are not human beings,” and that “one can easily jump to wrong conclusions” when comparing the two. Shapira spoke about the dangers of hype, and also questions the paper’s methods. She wonders if the models might have seen the test questions in their training data and simply memorized the correct answers, and also notes a potential problem with tests that use paid human participants (in this case, recruited via the Prolific platform). “It is a well-known issue that the workers do not always perform the task optimally,” she tells IEEE Spectrum. She considers the findings limited and somewhat anecdotal, saying, “to prove [theory of mind] capability, a lot of work and more comprehensive benchmarking is needed.”
Emily Bender, a professor of computational linguistics at the University of Washington, has become legendary in the field for her insistence on puncturing the hype that inflates the AI industry (and often also the media reports about that industry). She takes issue with the research question that motivated the researchers. “Why does it matter whether text-manipulation systems can produce output for these tasks that are similar to answers that people give when faced with the same questions?” she asks. “What does that teach us about the internal workings of LLMs, what they might be useful for, or what dangers they might pose?” It’s not clear, Bender says, what it would mean for a LLM to have a model of mind, and it’s therefore also unclear if these tests measured for it.
Bender also raises concerns about the anthropomorphizing she spots in the paper, with the researchers saying that the LLMs are capable of cognition, reasoning, and making choices. She says the authors’ phrase “species-fair comparison between LLMs and human participants” is “entirely inappropriate in reference to software.” Bender and several colleagues recently posted a preprint paper exploring how anthropomorphizing AI systems affects users’ trust.
The results may not indicate that AI really gets us, but it’s worth thinking about the repercussions of LLMs that convincingly mimic theory of mind reasoning. They’ll be better at interacting with their human users and anticipating their needs, but they could also be better used for deceit or the manipulation of their users. And they’ll invite more anthropomorphizing, by convincing human users that there’s a mind on the other side of the user interface.
Google launched Android Auto in 2015, promising a better car infotainment system to make driving easier. It brought the familiar Android interface to car screens, ...
Keeping track of your gadgets can be a struggle, especially with the ever-growing number of connected devices. Google’s Find My Device app helps locate your ...
There are a variety of altars you can come across in Vampire Dynasty. Worshipped in the small village where you begin your journey, the Forest Mother has multiple altars scattered across the land. This is how to find all Forest Mother altars in Vampire Dynasty.
Where to Find the Forest Mother Altars in Vampire Dynasty
To earn the Worshipper Steam achievement, you have to visit five altars of the Forest Mother. These are wooden structures found in the wilds of the area, with one of them located right in the village. They often have animal remains at the base, an arch above them, and a bundle of purple flowers hanging from the top.
The Spirit of Hearth-Home event in League of Legends features a variety of mini-games, from assembly books using pictures on the bindings to performing music to cleaning Ornn’s workshop. Part of the event focuses on the scales in the Smelter and various ores. Here’s how to complete the Smelter puzzle in the League of Legends Spirit of Hearth-Home event.
How to Solve the Smelter Scales Puzzle in League of Legends
The Smelter is a room to the upper left of the Courtyard. Inside, you’ll find a giant scale with two pieces of ore on it. There are six spaces below the scales that need to be filled.
If you want to maximize Microsoft Copilot’s capabilities, you can enhance query responses with plugins like Spotify and Adobe. Recently, a new plugin called “Phone” ...
pMany of us will celebrate Mother’s Day over the weekend by remembering or being present with women who raised us, or with our families. But for the a href=https://www.prisonpolicy.org/reports/pie2024women.htmlmore than 190,000 women incarcerated in the United States this weekend/a, there will be no celebration./p
pClose to a href=https://www.sentencingproject.org/app/uploads/2023/05/Incarcerated-Women-and-Girls-1.pdf60 percent/a of these women serving prison sentences were the primary caregiver of their minor children before sentencing. All too often, a prison sentence tears them from their family connections and contact with their children, while severing their children from a vital source of emotional and financial support. State women’s prisons are often located in rural areas, with limited modes of transportation, and families struggle to visit./p
pAs a result, families have very few in-person visits, and must rely on postal mail, or pay inflated prices for telephone calls and video contacts. Compounding the lack of connection, women in many state prisons cannot even hold in their hands and cherish a card or drawing sent by their children. Many prisons a href=https://slate.com/technology/2018/12/pennsylvania-prison-scanned-mail-smart-communications.htmlhave done away with real mail/a, and now use vendors to intercept, scan, and destroy all postal mail, delivering poor quality printouts of the original letter to the incarcerated recipients weeks later for a fee./p
pIn addition to women sentenced to prison, more than a href=https://bjs.ojp.gov/sites/g/files/xyckuh236/files/media/document/cj0519st.pdf#page=462.4 million women/a spend at least one day in jail each year, and a href=https://www.vera.org/downloads/publications/overlooked-women-and-jails-report-updated.pdf80 percent of them/a are mothers of children under the age of 18. And more than 60 percent of women in our nation’s jails are presumed innocent and awaiting trial, a href=https://www.brennancenter.org/our-work/analysis-opinion/how-profit-shapes-bail-bond-systemjailed due to poverty and an inability to purchase their freedom/a by posting bail./p
pChildren with mothers incarcerated in local jails often fare no better than those whose mothers are in state prisons: Some jails have a class=Hyperlink SCXW228476086 BCX0 href=https://www.nytimes.com/2024/03/28/us/jail-visits-ban-michigan-lawsuit.html target=_blank rel=noreferrer noopenercompletely banned in-person visitation/a to require all visits be done by paid video, not because of COVID, but to boost their bottom line. A a class=Hyperlink SCXW228476086 BCX0 href=https://www.prisonpolicy.org/visitation/report.html target=_blank rel=noreferrer noopener2015 study/a found that 74 percent of jails had banned in-person visits after putting video visits into place. Even when women are able to have in-person visits with their children, jail visits are often done through a plexiglass barrier. Women cannot hold, hug, touch, or kiss their children./p
pAlthough many more men are incarcerated than women in the U.S., women’s rate of incarceration has grown a href=https://www.prisonpolicy.org/reports/women_overtime.htmltwice that of men in the past 40 years/a. Since 2009, while the overall number of people in prisons and jails has decreased, a href=https://www.prisonpolicy.org/reports/women_overtime.htmlwomen have fared worse than men in 35 states/a. Women and families of color are disproportionately affected by this increase. Black and Native American / Alaska Native women are a href=http://chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://bjs.ojp.gov/document/p22st.pdfincarcerated at double their share of the population of women in the United States. /a/p
div class=mp-md wp-link
div class=wp-link__img-wrapper
a
href=https://www.aclu.org/issues/prisoners-rights/women-prison
target=_blank
tabindex=-1
img width=700 height=350 src=https://www.aclu.org/wp-content/uploads/2024/05/9be40077d72d6d19f05757087e5331e2.jpg class=attachment-4x3_full size-4x3_full alt= decoding=async loading=lazy srcset=https://www.aclu.org/wp-content/uploads/2024/05/9be40077d72d6d19f05757087e5331e2.jpg 700w, https://www.aclu.org/wp-content/uploads/2024/05/9be40077d72d6d19f05757087e5331e2-400x200.jpg 400w, https://www.aclu.org/wp-content/uploads/2024/05/9be40077d72d6d19f05757087e5331e2-600x300.jpg 600w sizes=(max-width: 700px) 100vw, 700px / /a
/div
div class=wp-link__title
a
href=https://www.aclu.org/issues/prisoners-rights/women-prison
target=_blank
Women in Prison /a
/div
div class=wp-link__description
a
href=https://www.aclu.org/issues/prisoners-rights/women-prison
target=_blank
tabindex=-1
p class=is-size-7-mobile is-size-6-tabletThe ACLU works in courts, legislatures, and communities to defend and preserve the individual rights and liberties that the Constitution and the.../p
/a
/div
div class=wp-link__source p-4 px-6-tablet
a
href=https://www.aclu.org/issues/prisoners-rights/women-prison
target=_blank
tabindex=-1
p class=is-size-7Source: American Civil Liberties Union/p
/a
/div
/div
pWomen often become entangled with the criminal legal system due to trying to cope with poverty, limited access to child care, underemployment or unemployment, unstable housing, and physical and mental health challenges. They get thrown into a legal system that criminalizes survival behaviors such as selling drugs or sex work, and policies that charge and arrest persons for being present when crimes are committed by others, “aiding and abetting” others, or fighting back against domestic violence. Aa href=https://survivedandpunished.org/wp-content/uploads/2019/02/SP_ResearchAcrossWalls_FINAL-compressedfordigital.pdf study in California found/a that 93 percent of women incarcerated in state prison for a homicide of a partner were abused by the person they killed, and in two-thirds of those cases, the homicide occurred while attempting to protect themselves or their children./p
pIncarcerated women have high rates of histories of physical and sexual abuse, trauma, and mental health and substance use disorders. While incarcerated, a href=https://www.ktvu.com/news/u-s-senators-call-fci-dublin-transfer-of-women-appallingwomen are more likely than incarcerated men/a to face a href=https://thehill.com/opinion/4648109-feds-close-prison-dubbed-the-rape-club-but-accountability-is-needed/sexual abuse or harassment/a by correctional staff, and they experience serious psychological distress due to incarceration and the conditions in prisons. a href=https://www.aclu.org/cases/jensen-v-thornellTreatment in prisons/a or jails for mental health conditions, substance use disorders, and trauma is often nonexistent. Health care for physical medical conditions or pregnancy often is limited at best: Last year, through our a href=https://www.aclu.org/cases/jensen-v-thornelllawsuit/a, we learned the Arizona Department of Corrections was a href=https://www.azcentral.com/story/news/local/arizona/2023/01/02/arizona-inducing-labor-of-pregnant-prisoners-against-their-will/69768038007/inducing the labor/a of pregnant incarcerated people against their will. This came after we a href=https://kjzz.org/content/951486/pregnant-women-arizona-prison-suffering-miscarriages-giving-birth-alonedocumented inadequate prenatal and postpartum care/a of women in Arizona prisons in 2019, including a woman with serious mental illness who gave birth alone, in the toilet of her cell, at a maximum custody unit./p
pSo what can we do to honor incarcerated women and families? First, we can financially support the incredible work of community-based bail funds that help free mothers and bring them home to their children and families. Second, we can support criminal legal reform policies to stop mass incarceration./p
pThe a href=https://www.nationalbailout.org/National Bail Out/a is a Black-led and Black-centered collective of organizers and advocates who are working to abolish pretrial detention and mass incarceration. They have coordinated with a variety of other groups, including a href=https://southernersonnewground.org/our-work/freefromfear/black-mamas-bail-out-action/Southerners on New Ground (SONG)/a, to create the tactical mass bail out of #FreeBlackMamas to acknowledge the reality that incarceration of women disproportionately affects Black women. They work with partner organizations to post bail for incarcerated women year-round, but especially before Mother’s Day. This year, instead of (or in addition to) sending flowers to your favorite mothers, you can donate to a href=https://www.nationalbailout.org/partnersNational Bail Out or the 18 Black-led organizations they are working with across the country/a to help #FreeBlackMamas./p
pWe also need to address the root causes of the incarceration of women in this country, which is often due to poverty. While drug or property offenses account for about half of the charges for which women are incarcerated, policies must also focus on reducing a href=https://www.sacbee.com/opinion/op-ed/article272572946.htmlso-called “violent” offenses/a that women commit often in response to violence and abuse./p
pWhen we incarcerate women, we are causing irreparable damage to them, their families, and all of our communities./p
pAI is nearly impossible for us to escape these days. a href=https://www.forbes.com/sites/kalinabryant/2024/03/14/how-ai-is-reshaping-social-media-platforms-and-5-tips-for-success/Social media/a companies, a href=https://www.wired.com/story/student-papers-generative-ai-turnitin/schools/a, a href=https://www.npr.org/2022/05/12/1098601458/artificial-intelligence-job-discrimination-disabilitiesworkplaces/a, and even a href=https://www.theatlantic.com/technology/archive/2024/04/dating-apps-are-starting-crack/678022/dating apps/a are all trying to harness AI to remake their services and platforms, and AI can impact our lives in ways large and small. While many of these efforts are just getting underway — and often raise significant civil rights issues — you might be surprised to learn that America’s most prolific spy agency has for years been one of AI’s biggest adopters./p
pThe National Security Agency (NSA) is the self-described a href=https://www.nsa.gov/leader/a among U.S. intelligence agencies racing to develop and deploy AI. It’s also the agency that sweeps up vast quantities of our phone calls, text messages, and internet communications as it conducts a href=https://www.aclu.org/news/national-security/five-things-to-know-about-nsa-mass-surveillance-and-the-coming-fight-in-congressmass surveillance/a around the world. In recent years, AI has transformed many of the NSA’s daily operations: the agency uses AI tools to help a href=https://perma.cc/97GE-4ULZgather/a information on foreign governments, a href=https://fedtechmagazine.com/article/2022/10/intelligence-community-developing-new-uses-ai-perfconaugment/a human language processing, a href=https://www.wsj.com/articles/ai-helps-u-s-intelligence-track-hackers-targeting-critical-infrastructure-944553facomb/a through networks for cybersecurity threats, and even monitor its own analysts as they do their jobs./p
pUnfortunately, that’s about all we know. As the NSA a href=https://perma.cc/97GE-4ULZintegrates/a AI into some of its most profound decisions, it’s left us in the dark about how it uses AI and what safeguards, if any, are in place to protect everyday Americans and others around the globe whose privacy hangs in the balance./p
pThat’s why we’re suing to find out what the NSA is hiding. Today, the ACLU filed a href=https://www.aclu.org/documents/nsa-ai-foia-complainta lawsuit/a under the Freedom of Information Act to compel the release of recently completed studies, roadmaps, and reports that explain how the NSA is using AI and what impact it is having on people’s civil rights and civil liberties. Indeed, although much of the NSA’s surveillance is aimed at people overseas, those activities increasingly ensnare the sensitive communications and data of people in the United States as well./p
pBehind closed doors, the NSA has been studying the effects of AI on its operations for several years. A year-and-a-half ago, the Inspectors General at the Department of Defense and the NSA issued a a href=https://perma.cc/A4L3-EC4Kjoint report/a examining how the NSA has integrated AI into its operations. NSA officials have also publicly lauded the completion of a href=https://perma.cc/F4ZT-PNTBstudies/a, a href=https://perma.cc/EQB4-XDVCroadmaps/a, and a href=https://perma.cc/SXP8-4APAcongressionally-mandated plans/a on the agency’s use of novel technologies like generative AI in its surveillance activities. But despite transparency pledges, none of those documents have been released to the public, not even in redacted form./p
pThe government’s secrecy flies in the face of its own public commitments to transparency when it comes to AI. The Office of the Director of National Intelligence, which oversees the NSA and more than a dozen other intelligence agencies, has touted transparency as a core principle in its a href=https://www.dni.gov/files/ODNI/documents/AI_Ethics_Framework_for_the_Intelligence_Community_10.pdfArtificial Intelligence Ethics Framework for the Intelligence Community/a. And a href=https://trumpwhitehouse.archives.gov/presidential-actions/executive-order-promoting-use-trustworthy-artificial-intelligence-federal-government/#:~:text=Certain%20agencies%20have%20already%20adopted,National%20Intelligence's%20Principles%20of%20Artificialadministrations/a a href=https://www.whitehouse.gov/briefing-room/presidential-actions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/from both parties/a have reiterated that AI must be used in a manner that builds public confidence while also advancing principles of equity and justice. By failing to disclose the kinds of critical information sought in our lawsuit, the government is failing its own ethical standards: it is rapidly deploying powerful AI systems without public accountability or oversight./p
pThe government’s lack of transparency is especially concerning given the dangers that AI systems pose for people’s civil rights and civil liberties. As we’ve already seen in areas like a href=https://www.aclu.org/news/privacy-technology/how-face-recognition-fuels-racist-systems-of-policing-and-immigration-and-why-congress-must-act-nowlaw enforcement/a and a href=https://www.aclu.org/news/racial-justice/how-artificial-intelligence-might-prevent-you-from-getting-hiredemployment/a, using algorithmic systems to gather and analyze intelligence can compound privacy intrusions and perpetuate discrimination. AI systems may amplify biases already embedded in training data or rely on flawed algorithms, and they may have higher error rates when applied to people of color and marginalized communities. For example, built-in bias or flawed intelligence algorithms may lead to additional surveillance and investigation of individuals, exposing their lives to wide-ranging government scrutiny. In the most extreme cases, bad tips could be passed along to agencies like Department of Homeland Security or the FBI, leading to immigration consequences or even wrongful arrests./p
pAI tools have the potential to expand the NSA’s surveillance dragnet more than ever before, expose private facts about our lives through vast data-mining activities, and automate decisions that once relied on human expertise and judgment. These are dangerous, powerful tools, as the NSA’s own ethical principles recognize. The public deserves to know how the government is using them./p
div class=mp-md wp-link
div class=wp-link__img-wrapper
a
href=https://www.aclu.org/news/national-security/the-government-is-racing-to-deploy-ai-but-at-what-cost-to-our-freedom
target=_blank
tabindex=-1
img width=1200 height=628 src=https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76.jpg class=attachment-4x3_full size-4x3_full alt= decoding=async loading=lazy srcset=https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76.jpg 1200w, https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76-768x402.jpg 768w, https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76-400x209.jpg 400w, https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76-600x314.jpg 600w, https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76-800x419.jpg 800w, https://www.aclu.org/wp-content/uploads/2024/04/0c811044641e2e113a33ba4134743c76-1000x523.jpg 1000w sizes=(max-width: 1200px) 100vw, 1200px / /a
/div
div class=wp-link__title
a
href=https://www.aclu.org/news/national-security/the-government-is-racing-to-deploy-ai-but-at-what-cost-to-our-freedom
target=_blank
The Government is Racing to Deploy AI, But at What Cost to Our Freedom? /a
/div
div class=wp-link__description
a
href=https://www.aclu.org/news/national-security/the-government-is-racing-to-deploy-ai-but-at-what-cost-to-our-freedom
target=_blank
tabindex=-1
p class=is-size-7-mobile is-size-6-tabletOur FOIA request seeks to uncover information about what types of AI tools intelligence agencies are deploying, what rules constrain their use, and.../p
/a
/div
div class=wp-link__source p-4 px-6-tablet
a
href=https://www.aclu.org/news/national-security/the-government-is-racing-to-deploy-ai-but-at-what-cost-to-our-freedom
target=_blank
tabindex=-1
p class=is-size-7Source: American Civil Liberties Union/p
/a
/div
/div
As the dust settles on Fallout's first TV season, which appears to have been as universally beloved as any piece of media can be in today's world, the line that sticks with me most radiates from early in the show. As Ella Purnell's Vault Dweller Lucy sleeps beside her Scout badge-perfect campfire, she awakes to find Michael Emerson's fugitive scientist sitting nearby. All-too familiar with the perils of the Wasteland, Emerson's character urges her to return to the Vault from whence she came. This goes down with Lucy about as well as two litres of irradiated water, so instead the scientist posits a question. "Will you still want the same things, when you become a different animal altogether?"
It's an interesting question to ask in the context of Fallout itself, a series which is at once so recognisable and yet so different from its original form. On the one hand, you can trace Fallout's aesthetic all the way back to the opening cinematic of the first game, which juxtaposes a kitsch 1950s-style commercial with the blasted moonscape of post-nuclear America, all to the lilting vocals of the Ink Spots' "Maybe". It's interesting to return to now. Rare is it that a series' audiovisual identity emerges so fully formed, yet it's there in Fallout from Defcon one.
Yet the games beneath the Vault Boy iconography have changed dramatically in the last quarter-century, to the point where it remains a bone of contention within the Fallout community. There is something, the argument goes, that Interplay's isometric RPGs have which Bethesda's 3D, real-time open world games lack. Certainly, the more recent games have had their flaws. Fallout 3 arguably dialled back the colour of Fallout too much, while Fallout 4 leans heavily toward being a shooter at the cost of broader role-playing options. But these remain distinctly Fallout games in other ways, replete with that familiar visual identity, and in quests like the Gary-filled Vault 108 - as perfectly strange as the wasteland demands.
Young people taking part in the European Astro Pi Challenge are about to have their computer programs sent to the International Space Station (ISS). Astro Pi is run annually in collaboration by us and ESA Education, and offers two ways to get involved: Mission Zero and Mission Space Lab.
This year, over 25,000 young people from across Europe and eligible ESA Member States are getting their programs ‘uplinked’ to the Astro Pi computers aboard the ISS, where they will be running over the next few weeks.
Mission Zero teams send their art into space
Mission Zero is an exciting activity for kids with little or no experience with coding. We invite young people to create a Python program that displays an 8×8 pixel image or animation. This program then gets sent to the ISS, and each pixel art piece is displayed for 30 seconds on the LED matrix display of the Astro Pi computers on the ISS.
Astro Pis on the ISS
We picked the theme ‘fauna and flora’ as the inspiration for young people’s pixel art, as it proved so popular last year, and we weren’t disappointed: this year, 24,378 young people submitted 16,039 Mission Zero creations!
We’ve tested every program and are pleased to announce that 15,942 Mission Zero programs will be sent to run on the ISS from mid May.
Once again, we have been amazed at the wonderful images and animations that young people have created. Seeing all the images that have been submitted is one of the most enjoyable and inspiring things to do as we work on the Astro Pi Challenge. Here is a little selection of some of our favourites submitted this year:
A selection of Mission Zero submissions
Varied approaches: How different teams calculate ISS speed
For Mission Space Lab, we invite more experienced young coders to take on a scientific challenge: to calculate the speed that the ISS orbits Earth.
Teams are tasked with writing a program that uses the Astro Pis’ sensors and visible light camera to capture data for their calculations, and we have really enjoyed seeing the different approaches the teams have taken.
Some teams decided to calculate the distance between two points in photos of the Earth’s surface and combine this with how long it took for the ISS to pass over the points to find the speed. This particular method uses feature extraction and needs to account for ground sampling distance — how many square metres are represented in one pixel in an image of the ground taken from above — to get an accurate output.
We’ve also seen teams use data from the gyroscope to calculate the speed using the angle readings and photos to get their outputs. Yet other teams have derived the speed using equations of motion and sampling from the accelerometer.
Feature extraction example taken from images captured by the Astro Pis
All teams that took multiple samples from the Astro Pi sensors, or multiple images, had to decide how to output a final estimate for the speed of the ISS. Most teams opted to use the mean average. But a few teams chose to filter their samples to choose only the ‘best’ ones based on prior knowledge (Bayesian filtering), and some used a machine learning model and the Astro Pi’s machine learning dongle to select which images or data samples to use. Some teams even provided a certainty score along with their final estimate.
236 Mission Space Lab teams awarded flight status
However the team choses to approach the challenge, before their program can run on the ISS, we need to make sure of a few things. For a start, we check that they’ve followed the challenge rules and meet the ISS security requirements. Next, we check that the program can run without errors on the Astro Pis as the astronauts on board the ISS can’t stop what they’re doing to fix any problems.
So, all programs submitted to us must pass a rigorous testing process before they can be sent into space. We run each program on several replica Astro Pis, then run all the programs sequentially, to ensure there’s no problems. If the program passes testing, it’s awarded ‘flight status’ and can be sent to run in space.
This year, 236 teams have been awarded flight status. These teams represent 889 young people from 22 countries in Europe and ESA member states. The average age of these young people is 15, and 27% of them are girls. The UK has the most teams achieving flight status (61), followed by the Czech Republic (23) and Romania (22). You can see how this compares to last year and explore other breakdowns of participant data in the annual Astro Pi impact report.
Our congratulations to all the Mission Space Lab teams who’ve been awarded flight status: it is a great achievement. All these teams will be invited to join a live online Q&A with an ESA astronaut in June. We can’t wait to see what questions you send us for the astronaut.
A pause to recharge the ISS batteries
Normally, the Astro Pi programs run continuously from the end of April until the end of May. However, this year, there is an interesting event happening in the skies above us that means that programs will pause for a few days. The ISS will be moving its position on the ‘beta angle’ and pivoting its orientation to maximise the sunlight that it can capture with its solar panels.
The International Space Station
The ISS normally takes 90 minutes to complete its orbit, 45 minutes of which is in sunlight, and 45 minutes in darkness. When it moves along the beta angle, it will be in continual sunlight, allowing it to capture lots of solar energy and recharge its batteries. While in its new orientation, the ISS is exposed to increased heat from the sun so the window shutters must be closed to help the astronauts stay cool. That means taking photos of the Earth’s surface won’t be possible for a few days.
What next?
Once all of the programs have run, we will send the Mission Space Lab teams the data collected during their experiments. All successful Mission Zero and Mission Space Lab teams and mentors will also receive personal certificates to recognise their mission completion.
Congratulations to all of this year’s Astro Pi Challenge participants, and especially to all successful teams.
As the dust settles on Fallout's first TV season, which appears to have been as universally beloved as any piece of media can be in today's world, the line that sticks with me most radiates from early in the show. As Ella Purnell's Vault Dweller Lucy sleeps beside her Scout badge-perfect campfire, she awakes to find Michael Emerson's fugitive scientist sitting nearby. All-too familiar with the perils of the Wasteland, Emerson's character urges her to return to the Vault from whence she came. This goes down with Lucy about as well as two litres of irradiated water, so instead the scientist posits a question. "Will you still want the same things, when you become a different animal altogether?"
It's an interesting question to ask in the context of Fallout itself, a series which is at once so recognisable and yet so different from its original form. On the one hand, you can trace Fallout's aesthetic all the way back to the opening cinematic of the first game, which juxtaposes a kitsch 1950s-style commercial with the blasted moonscape of post-nuclear America, all to the lilting vocals of the Ink Spots' "Maybe". It's interesting to return to now. Rare is it that a series' audiovisual identity emerges so fully formed, yet it's there in Fallout from Defcon one.
Yet the games beneath the Vault Boy iconography have changed dramatically in the last quarter-century, to the point where it remains a bone of contention within the Fallout community. There is something, the argument goes, that Interplay's isometric RPGs have which Bethesda's 3D, real-time open world games lack. Certainly, the more recent games have had their flaws. Fallout 3 arguably dialled back the colour of Fallout too much, while Fallout 4 leans heavily toward being a shooter at the cost of broader role-playing options. But these remain distinctly Fallout games in other ways, replete with that familiar visual identity, and in quests like the Gary-filled Vault 108 - as perfectly strange as the wasteland demands.
Each year, the AI Index lands on virtual desks with a louder virtual thud—this year, its 393 pages are a testament to the fact that AI is coming off a really big year in 2023. For the past three years, IEEE Spectrum has read the whole damn thing and pulled out a selection of charts that sum up the current state of AI (see our coverage from 2021, 2022, and 2023).
This year’s report, published by the Stanford Institute for Human-Centered Artificial Intelligence (HAI), has an expanded chapter on responsible AI and new chapters on AI in science and medicine, as well as its usual roundups of R&D, technical performance, the economy, education, policy and governance, diversity, and public opinion. This year is also the first time that Spectrum has figured into the report, with a citation of an article published here about generative AI’s visual plagiarism problem.
1. Generative AI investment skyrockets
While corporate investment was down overall last year, investment in generative AI went through the roof. Nestor Maslej, editor-in-chief of this year’s report, tells Spectrum that the boom is indicative of a broader trend in 2023, as the world grappled with the new capabilities and risks of generative AI systems like ChatGPT and the image-generating DALL-E 2. “The story in the last year has been about people responding [to generative AI],” says Maslej, “whether it’s in policy, whether it’s in public opinion, or whether it’s in industry with a lot more investment.” Another chart in the report shows that most of that private investment in generative AI is happening in the United States.
2. Google is dominating the foundation model race
Foundation models are big multipurpose models—for example, OpenAI’s GPT-3 and GPT-4 are the foundation model that enable ChatGPT users to write code or Shakespearean sonnets. Since training these models typically requires vast resources, Industry now makes most of them, with academia only putting out a few. Companies release foundation models both to push the state-of-the-art forward and to give developers a foundation on which to build products and services. Google released the most in 2023.
3. Closed models outperform open ones
One of the hot debates in AI right now is whether foundation models should be open or closed, with some arguing passionately that open models are dangerous and others maintaining that open models drive innovation. The AI Index doesn’t wade into that debate, but instead looks at trends such as how many open and closed models have been released (another chart, not included here, shows that of the 149 foundation models released in 2023, 98 were open, 23 gave partial access through an API, and 28 were closed).
The chart above reveals another aspect: Closed models outperform open ones on a host of commonly used benchmarks. Maslej says the debate about open versus closed “usually centers around risk concerns, but there’s less discussion about whether there are meaningful performance trade-offs.”
4. Foundation models have gotten super expensive
Here’s why industry is dominating the foundation model scene: Training a big one takes very deep pockets. But exactly how deep? AI companies rarely reveal the expenses involved in training their models, but the AI Index went beyond the typical speculation by collaborating with the AI research organization Epoch AI. To come up with their cost estimates, the report explains, the Epoch team “analyzed training duration, as well as the type, quantity, and utilization rate of the training hardware” using information gleaned from publications, press releases, and technical reports.
It’s interesting to note that Google’s 2017 transformer model, which introduced the architecture that underpins almost all of today’s large language models, was trained for only US $930.
5. And they have a hefty carbon footprint
The AI Index team also estimated the carbon footprint of certain large language models. The report notes that the variance between models is due to factors including model size, data center energy efficiency, and the carbon intensity of energy grids. Another chart in the report (not included here) shows a first guess at emissions related to inference—when a model is doing the work it was trained for—and calls for more disclosures on this topic. As the report notes: “While the per-query emissions of inference may be relatively low, the total impact can surpass that of training when models are queried thousands, if not millions, of times daily.”
6. The United States leads in foundation models
While Maslej says the report isn’t trying to “declare a winner to this race,” he does note that the United States is leading in several categories, including number of foundation models released (above) and number of AI systems deemed significant technical advances. However, he notes that China leads in other categories including AI patents granted and installation of industrial robots.
7. Industry calls new PhDs
This one is hardly a surprise, given the previously discussed data about industry getting lots of investment for generative AI and releasing lots of exciting models. In 2022 (the most recent year for which the Index has data), 70 precent of new AI PhDs in North America took jobs in industry. It’s a continuation of a trend that’s been playing out over the last few years.
8. Some progress on diversity
For years, there’s been little progress on making AI less white and less male. But this year’s report offers a few hopeful signs. For example, the number of non-white and female students taking the AP computer science exam is on the rise. The graph above shows the trends for ethnicity, while another graph, not included here, shows that 30 percent of the students taking the exam are now girls.
Another graph in the report shows that at the undergraduate level, there’s also a positive trend in increasing ethnic diversity among North American students earning bachelor degrees in computer science, although the number of women earning CS bachelor degrees has barely budged over the last five years. Says Maslej, “it’s important to know that there’s still a lot of work to be done here.”
9. Chatter in earnings calls
Businesses are awake to the possibilities of AI. The Index got data about Fortune 500 companies’ earnings calls from Quid, a market intelligence firm that used natural language processing tools to scan for all mentions of “artificial intelligence,” “AI,” “machine learning,” “ML,” and “deep learning.” Nearly 80 percent of the companies included discussion of AI in their calls. “I think there’s a fear in business leaders that if they don’t use this technology, they’re going to miss out,” Maslej says.
And while some of that chatter is likely just CEOs bandying about buzzwords, another graph in the report shows that 55 percent of companies included in a McKinsey survey have implemented AI in at least one business unit.
10. Costs go down, revenues go up
And here’s why AI isn’t just a corporate buzzword: The same McKinsey survey showed that the integration of AI has caused companies’ costs to go down and their revenues go up. Overall, 42 percent of respondents said they’d seen reduced costs, and 59 percent claimed increased revenue.
Other charts in the report suggest that this impact on the bottom line reflects efficiency gains and better worker productivity. In 2023, a number of studies in different fields showed that AI enabled workers to complete tasks more quickly and produce better quality work. One study looked at coders using Copilot, while others looked at consultants, call center agents, and law students. “These studies also show that although every worker benefits, AI helps lower-skilled workers more than it does high-skilled workers,” says Maslej.
11. Corporations do perceive risks
This year, the AI Index team ran a global survey of 1,000 corporations with revenues of at least $500 million to understand how businesses are thinking about responsible AI. The results showed that privacy and data governance is perceived as the greatest risk across the globe, while fairness (often discussed in terms of algorithmic bias) still hasn’t registered with most companies. Another chart in the report shows that companies are taking action on their perceived risks: The majority of organizations across regions have implemented at least one responsible AI measure in response to relevant risks.
12. AI can’t beat humans at everything... yet
In recent years, AI systems have outperformed humans on a range of tasks, including reading comprehension and visual reasoning, and Maslej notes that the pace of AI performance improvement has also picked up. “A decade ago, with a benchmark like ImageNet, you could rely on that to challenge AI researchers for for five or six years,” he says. “Now, a new benchmark is introduced for competition-level mathematics and the AI starts at 30 percent, and then in a year it gets to 90 percent.” While there are still complex cognitive tasks where humans outperform AI systems, let’s check in next year to see how that’s going.
13. Developing norms of AI responsibility
When an AI company is preparing to release a big model, it’s standard practice to test it against popular benchmarks in the field, thus giving the AI community a sense of how models stack up against each other in terms of technical performance. However, it has been less common to test models against responsible AI benchmarks that assess such things as toxic language output (RealToxicityPrompts and ToxiGen), harmful bias in responses (BOLD and BBQ), and a model’s degree of truthfulness (TruthfulQA). That’s starting to change, as there’s a growing sense that checking one’s model against theses benchmarks is, well, the responsible thing to do. However, another chart in the report shows that consistency is lacking: Developers are testing their models against different benchmarks, making comparisons harder.
14. Laws both boost and constrain AI
Between 2016 and 2023, the AI Index found that 33 countries had passed at least one law related to AI, with most of the action occurring in the United States and Europe; in total, 148 AI-related bills have been passed in that timeframe. The Index researchers also classified bills as either expansive laws that aim to enhance a country’s AI capabilities or restrictive laws that place limits on AI applications and usage. While many bills continue to boost AI, the researchers found a global trend toward restrictive legislation.
15. AI makes people nervous
The Index’s public opinion data comes from a global survey on attitudes toward AI, with responses from 22,816 adults (ages 16 to 74) in 31 countries. More than half of respondents said that AI makes them nervous, up from 39 percent the year before. And two-thirds of people now expect AI to profoundly change their daily lives in the next few years.
Maslej notes that other charts in the index show significant differences in opinion among different demographics, with young people being more inclined toward an optimistic view of how AI will change their lives. Interestingly, “a lot of this kind of AI pessimism comes from Western, well-developed nations,” he says, while respondents in places like Indonesia and Thailand said they expect AI’s benefits to outweigh its harms.
I'm beginning to think we should bury Vampire: The Masquerade back in the forsaken graveyard where it was originally dug up, or at least banish the toothy reprobate back to its pen & paper castle. I don't know how White Wolf's RPG is viewed in the land of table tops these days, but here in computerville it has delivered exactly one good video game in the last 25 years (and don't come gibbering to me about 2022's Swansong, it wasn't fit to polish Bloodlines' fangs). Sure, Bloodlines 2 might prove a winner, but given years of delays and a developer change, I'll believe it when I see it.
Which brings us to Vampire: The Masquerade - Justice, the beleaguered series' first prowl through the rain-slick streets of VR. In theory, this should be exactly my cup of haemoglobin; a gothic, linear stealth game where you use your vampire powers to sneak across the rooftops of Venice. In its mechanics and design, Justice aspires to be a cut down version of Dishonored. Unfortunately, it's in the cutting down where most of its problems arise. It's too cramped, too basic, and too fuzzy around the edges, and the whole experience ends up being a bit mid.
As someone who finds games about cars wot go fast only intermittently interesting, I'd expect a game about cars wot go slow to be positively soporific. Speed is, ultimately, the modus operandi of a car. It gets you where you need to go faster than a horse, and doesn't do annoying things like pooing on your patio or dying (also, potentially, on your patio). Surely, then, playing a game about cars moving at the speed of a dead patio horse defeats the point, like playing a first-person shooter where all the guns fire backwards.
Expeditions: A Mudrunner Game demonstrates this not to be the case. This bouncy, slimy off-roading simulator is the most fun I've had with an imaginary car since 2018's Jalopy. This is partly because it is as much a physics puzzler filled with limitless conundrums as it is a game about driving, but also because, like Jalopy, it envisions the car as something more than a way to boost egos by doing a big circle.
Dark Forces emerges from Nightdive's bacta tank refreshed and ready for action, combining classic FPS mayhem with thrilling espionage-themed missions.
"This is too easy" quips Kyle Katarn as he snatches the Death Star plans in Dark Forces' opening mission. What took Rogue One two-and-a-half ponderous hours to unspool, LucasArts' shooter pulls off in ten thrilling minutes. For Katarn, a cocky mercenary in tentative accord with the Rebel Alliance, stealing the Death Star plans is just another contract. In, out, job done.
Katarn's confidence and competence is echoed both in Dark Forces at large and Nightdive's work restoring it. The remaster is a consummately professional overhaul, making the game look just how you remember it in a way that belies the work involved to get it to this stage. In doing so, Nightdive reveals a shooter that hits the brief like a proton torpedo, a Doom clone elevated by its vivid, imaginative expansion upon the Star Wars universe.
Like a demon summoned by fresh blood on its altar, Wrath: Aeon of Ruin first arose at the height of the retro-shooter revival. Developed in a modified Quake engine with levels designed by contributors to mods like Arcane Dimensions, it looked set to conquer all in its path when it arrived in 2019. Its Early Access showcased amazing weapons, splattering enemies, a knotty, secret-filled hubworld, and maps you'd sell your soul for.
Then it went back to sleep for five years. In 2021, developer KillPixel admitted the project had been sorely hindered by the Covid 19 pandemic. But the full game would be out in Summer 2022. That became Spring 2023, which then became February 2024. In that time the retro shooter continued to evolve, giving us its Doom (Prodeus), its Duke Nukem (Ion Fury) and its Hexen (AMID EVIL). All the while Wrath's presence faded, looking less like a spiritual successor to Quake, and more like a rerun of Daikatana.
Now though, Wrath is finished, and unlike John Romero's white elephant, you can see why it took so long. This isn't so much a first-person shooter as it is an ode to 3D level design, a dimension-hopping adventure of colossal scale and variety that bends the Quake engine into frankly obscene positions. Sadly, this is as much a criticism as it is a compliment, for in its strive to provide the grandest shooting galleries in existence, the shooting itself gets a little lost along the way.
Generative AI is today’s buzziest form of artificial intelligence, and it’s what powers chatbots like ChatGPT, Ernie, LLaMA, Claude, and Command—as well as image generators like DALL-E 2, Stable Diffusion, Adobe Firefly, and Midjourney. Generative AI is the branch of AI that enables machines to learn patterns from vast datasets and then to autonomously produce new content based on those patterns. Although generative AI is fairly new, there are already many examples of models that can produce text, images, videos, and audio.
Many “foundation models” have been trained on enough data to be competent in a wide variety of tasks. For example, a large language model can generate essays, computer code, recipes, protein structures, jokes, medical diagnostic advice, and much more. It can also theoretically generate instructions for building a bomb or creating a bioweapon, though safeguards are supposed to prevent such types of misuse.
What’s the difference between AI, machine learning, and generative AI?
Artificial intelligence (AI) refers to a wide variety of computational approaches to mimicking human intelligence.
Machine learning (ML) is a subset of AI; it focuses on algorithms that enable systems to learn from data and improve their performance. Before generative AI came along, most ML models learned from datasets to perform tasks such as classification or prediction. Generative AI is a specialized type of ML involving models that perform the task of generating new content, venturing into the realm of creativity.
What architectures do generative AI models use?
Generative models are built using a variety of neural network architectures—essentially the design and structure that defines how the model is organized and how information flows through it. Some of the most well-known architectures are
variational autoencoders (VAEs), generative adversarial networks (GANs), and transformers. It’s the transformer architecture, first shown in this seminal 2017 paper from Google, that powers today’s large language models. However, the transformer architecture is less suited for other types of generative AI, such as image and audio generation.
Autoencoders learn efficient representations of data through an
encoder-decoder framework. The encoder compresses input data into a lower-dimensional space, known as the latent (or embedding) space, that preserves the most essential aspects of the data. A decoder can then use this compressed representation to reconstruct the original data. Once an autoencoder has been trained in this way, it can use novel inputs to generate what it considers the appropriate outputs. These models are often deployed in image-generation tools and have also found use in drug discovery, where they can be used to generate new molecules with desired properties.
With generative adversarial networks (GANs), the training involves a
generator and a discriminator that can be considered adversaries. The generator strives to create realistic data, while the discriminator aims to distinguish between those generated outputs and real “ground truth” outputs. Every time the discriminator catches a generated output, the generator uses that feedback to try to improve the quality of its outputs. But the discriminator also receives feedback on its performance. This adversarial interplay results in the refinement of both components, leading to the generation of increasingly authentic-seeming content. GANs are best known for creating deepfakes but can also be used for more benign forms of image generation and many other applications.
The transformer is arguably the reigning champion of generative AI architectures for its ubiquity in today’s powerful large language models (LLMs). Its strength lies in its attention mechanism, which enables the model to focus on different parts of an input sequence while making predictions. In the case of language models, the input consists of strings of words that make up sentences, and the transformer predicts what words will come next (we’ll get into the details below). In addition, transformers can process all the elements of a sequence in parallel rather than marching through it from beginning to end, as earlier types of models did; this
parallelization makes training faster and more efficient. When developers added vast datasets of text for transformer models to learn from, today’s remarkable chatbots emerged.
How do large language models work?
A transformer-based LLM is trained by giving it a vast dataset of text to learn from. The attention mechanism comes into play as it processes sentences and looks for patterns. By looking at all the words in a sentence at once, it gradually begins to understand which words are most commonly found together and which words are most important to the meaning of the sentence. It learns these things by trying to predict the next word in a sentence and comparing its guess to the ground truth. Its errors act as feedback signals that cause the model to adjust the weights it assigns to various words before it tries again.
These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
To explain the training process in slightly more technical terms, the text in the training data is broken down into elements called
tokens, which are words or pieces of words—but for simplicity’s sake, let’s say all tokens are words. As the model goes through the sentences in its training data and learns the relationships between tokens, it creates a list of numbers, called a vector, for each one. All the numbers in the vector represent various aspects of the word: its semantic meanings, its relationship to other words, its frequency of use, and so on. Similar words, like elegant and fancy, will have similar vectors and will also be near each other in the vector space. These vectors are called word embeddings. The parameters of an LLM include the weights associated with all the word embeddings and the attention mechanism. GPT-4, the OpenAI model that’s considered the current champion, is rumored to have more than 1 trillion parameters.
Given enough data and training time, the LLM begins to understand the subtleties of language. While much of the training involves looking at text sentence by sentence, the attention mechanism also captures relationships between words throughout a longer text sequence of many paragraphs. Once an LLM is trained and is ready for use, the attention mechanism is still in play. When the model is generating text in response to a prompt, it’s using its predictive powers to decide what the next word should be. When generating longer pieces of text, it predicts the next word in the context of all the words it has written so far; this function increases the coherence and continuity of its writing.
Why do large language models hallucinate?
You may have heard that LLMs sometimes “hallucinate.” That’s a polite way to say they make stuff up very convincingly. A model sometimes generates text that fits the context and is grammatically correct, yet the material is erroneous or nonsensical. This bad habit stems from LLMs training on vast troves of data drawn from the Internet, plenty of which is not factually accurate. Since the model is simply trying to predict the next word in a sequence based on what it has seen, it may generate plausible-sounding text that has no grounding in reality.
Why is generative AI controversial?
One source of controversy for generative AI is the provenance of its training data. Most AI companies that train large models to generate text, images, video, and audio have
not been transparent about the content of their training datasets. Various leaks and experiments have revealed that those datasets include copyrighted material such as books, newspaper articles, and movies. A number of lawsuits are underway to determine whether use of copyrighted material for training AI systems constitutes fair use, or whether the AI companies need to pay the copyright holders for use of their material.
On a related note, many people are concerned that the widespread use of generative AI will take jobs away from creative humans who make art, music, written works, and so forth. People are also concerned that it could take jobs from humans who do a wide range of white-collar jobs, including translators, paralegals, customer-service representatives, and journalists. There have already been a few
troubling layoffs, but it’s hard to say yet whether generative AI will be reliable enough for large-scale enterprise applications. (See above about hallucinations.)
Finally, there’s the danger that generative AI will be used to make bad stuff. And there are of course many categories of bad stuff it could theoretically be used for. Generative AI can be used for personalized scams and phishing attacks: For example, using “voice cloning,” scammers can
copy the voice of a specific person and call the person’s family with a plea for help (and money). All formats of generative AI—text, audio, image, and video—can be used to generate misinformation by creating plausible-seeming representations of things that never happened, which is a particularly worrying possibility when it comes to elections. (Meanwhile, as IEEE Spectrum reported this week, the U.S. Federal Communications Commission has responded by outlawing AI-generated robocalls.) Image- and video-generating tools can be used to produce nonconsensual pornography, although the tools made by mainstream companies disallow such use. And chatbots can theoretically walk a would-be terrorist through the steps of making a bomb, nerve gas, and a host of other horrors. Although the big LLMs have safeguards to prevent such misuse, some hackers delight in circumventing those safeguards. What’s more, “uncensored” versions of open-source LLMs are out there.
Despite such potential problems, many people think that generative AI can also make people more productive and could be used as a tool to enable entirely new forms of creativity. We’ll likely see both disasters and creative flowerings and plenty else that we don’t expect. But knowing the basics of how these models work is increasingly crucial for tech-savvy people today. Because no matter how sophisticated these systems grow, it’s the humans’ job to keep them running, make the next ones better, and with any luck, help people out too.
Andrew Ng has serious street cred in artificial intelligence. He pioneered the use of graphics processing units (GPUs) to train deep learning models in the late 2000s with his students at Stanford University, cofounded Google Brain in 2011, and then served for three years as chief scientist for Baidu, where he helped build the Chinese tech giant’s AI group. So when he says he has identified the next big shift in artificial intelligence, people listen. And that’s what he told IEEE Spectrum in an exclusive Q&A.
Ng’s current efforts are focused on his company
Landing AI, which built a platform called LandingLens to help manufacturers improve visual inspection with computer vision. He has also become something of an evangelist for what he calls the data-centric AI movement, which he says can yield “small data” solutions to big issues in AI, including model efficiency, accuracy, and bias.
The great advances in deep learning over the past decade or so have been powered by ever-bigger models crunching ever-bigger amounts of data. Some people argue that that’s an unsustainable trajectory. Do you agree that it can’t go on that way?
Andrew Ng: This is a big question. We’ve seen foundation models in NLP [natural language processing]. I’m excited about NLP models getting even bigger, and also about the potential of building foundation models in computer vision. I think there’s lots of signal to still be exploited in video: We have not been able to build foundation models yet for video because of compute bandwidth and the cost of processing video, as opposed to tokenized text. So I think that this engine of scaling up deep learning algorithms, which has been running for something like 15 years now, still has steam in it. Having said that, it only applies to certain problems, and there’s a set of other problems that need small data solutions.
When you say you want a foundation model for computer vision, what do you mean by that?
Ng: This is a term coined by Percy Liang and some of my friends at Stanford to refer to very large models, trained on very large data sets, that can be tuned for specific applications. For example, GPT-3 is an example of a foundation model [for NLP]. Foundation models offer a lot of promise as a new paradigm in developing machine learning applications, but also challenges in terms of making sure that they’re reasonably fair and free from bias, especially if many of us will be building on top of them.
What needs to happen for someone to build a foundation model for video?
Ng: I think there is a scalability problem. The compute power needed to process the large volume of images for video is significant, and I think that’s why foundation models have arisen first in NLP. Many researchers are working on this, and I think we’re seeing early signs of such models being developed in computer vision. But I’m confident that if a semiconductor maker gave us 10 times more processor power, we could easily find 10 times more video to build such models for vision.
Having said that, a lot of what’s happened over the past decade is that deep learning has happened in consumer-facing companies that have large user bases, sometimes billions of users, and therefore very large data sets. While that paradigm of machine learning has driven a lot of economic value in consumer software, I find that that recipe of scale doesn’t work for other industries.
It’s funny to hear you say that, because your early work was at a consumer-facing company with millions of users.
Ng: Over a decade ago, when I proposed starting the Google Brain project to use Google’s compute infrastructure to build very large neural networks, it was a controversial step. One very senior person pulled me aside and warned me that starting Google Brain would be bad for my career. I think he felt that the action couldn’t just be in scaling up, and that I should instead focus on architecture innovation.
“In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.”
—Andrew Ng, CEO & Founder, Landing AI
I remember when my students and I published the first
NeurIPS workshop paper advocating using CUDA, a platform for processing on GPUs, for deep learning—a different senior person in AI sat me down and said, “CUDA is really complicated to program. As a programming paradigm, this seems like too much work.” I did manage to convince him; the other person I did not convince.
I expect they’re both convinced now.
Ng: I think so, yes.
Over the past year as I’ve been speaking to people about the data-centric AI movement, I’ve been getting flashbacks to when I was speaking to people about deep learning and scalability 10 or 15 years ago. In the past year, I’ve been getting the same mix of “there’s nothing new here” and “this seems like the wrong direction.”
How do you define data-centric AI, and why do you consider it a movement?
Ng: Data-centric AI is the discipline of systematically engineering the data needed to successfully build an AI system. For an AI system, you have to implement some algorithm, say a neural network, in code and then train it on your data set. The dominant paradigm over the last decade was to download the data set while you focus on improving the code. Thanks to that paradigm, over the last decade deep learning networks have improved significantly, to the point where for a lot of applications the code—the neural network architecture—is basically a solved problem. So for many practical applications, it’s now more productive to hold the neural network architecture fixed, and instead find ways to improve the data.
When I started speaking about this, there were many practitioners who, completely appropriately, raised their hands and said, “Yes, we’ve been doing this for 20 years.” This is the time to take the things that some individuals have been doing intuitively and make it a systematic engineering discipline.
The data-centric AI movement is much bigger than one company or group of researchers. My collaborators and I organized a
data-centric AI workshop at NeurIPS, and I was really delighted at the number of authors and presenters that showed up.
You often talk about companies or institutions that have only a small amount of data to work with. How can data-centric AI help them?
Ng: You hear a lot about vision systems built with millions of images—I once built a face recognition system using 350 million images. Architectures built for hundreds of millions of images don’t work with only 50 images. But it turns out, if you have 50 really good examples, you can build something valuable, like a defect-inspection system. In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.
When you talk about training a model with just 50 images, does that really mean you’re taking an existing model that was trained on a very large data set and fine-tuning it? Or do you mean a brand new model that’s designed to learn only from that small data set?
Ng: Let me describe what Landing AI does. When doing visual inspection for manufacturers, we often use our own flavor of RetinaNet. It is a pretrained model. Having said that, the pretraining is a small piece of the puzzle. What’s a bigger piece of the puzzle is providing tools that enable the manufacturer to pick the right set of images [to use for fine-tuning] and label them in a consistent way. There’s a very practical problem we’ve seen spanning vision, NLP, and speech, where even human annotators don’t agree on the appropriate label. For big data applications, the common response has been: If the data is noisy, let’s just get a lot of data and the algorithm will average over it. But if you can develop tools that flag where the data’s inconsistent and give you a very targeted way to improve the consistency of the data, that turns out to be a more efficient way to get a high-performing system.
“Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.”
—Andrew Ng
For example, if you have 10,000 images where 30 images are of one class, and those 30 images are labeled inconsistently, one of the things we do is build tools to draw your attention to the subset of data that’s inconsistent. So you can very quickly relabel those images to be more consistent, and this leads to improvement in performance.
Could this focus on high-quality data help with bias in data sets? If you’re able to curate the data more before training?
Ng: Very much so. Many researchers have pointed out that biased data is one factor among many leading to biased systems. There have been many thoughtful efforts to engineer the data. At the NeurIPS workshop, Olga Russakovsky gave a really nice talk on this. At the main NeurIPS conference, I also really enjoyed Mary Gray’s presentation, which touched on how data-centric AI is one piece of the solution, but not the entire solution. New tools like Datasheets for Datasets also seem like an important piece of the puzzle.
One of the powerful tools that data-centric AI gives us is the ability to engineer a subset of the data. Imagine training a machine-learning system and finding that its performance is okay for most of the data set, but its performance is biased for just a subset of the data. If you try to change the whole neural network architecture to improve the performance on just that subset, it’s quite difficult. But if you can engineer a subset of the data you can address the problem in a much more targeted way.
When you talk about engineering the data, what do you mean exactly?
Ng: In AI, data cleaning is important, but the way the data has been cleaned has often been in very manual ways. In computer vision, someone may visualize images through a Jupyter notebook and maybe spot the problem, and maybe fix it. But I’m excited about tools that allow you to have a very large data set, tools that draw your attention quickly and efficiently to the subset of data where, say, the labels are noisy. Or to quickly bring your attention to the one class among 100 classes where it would benefit you to collect more data. Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.
For example, I once figured out that a speech-recognition system was performing poorly when there was car noise in the background. Knowing that allowed me to collect more data with car noise in the background, rather than trying to collect more data for everything, which would have been expensive and slow.
What about using synthetic data, is that often a good solution?
Ng: I think synthetic data is an important tool in the tool chest of data-centric AI. At the NeurIPS workshop, Anima Anandkumar gave a great talk that touched on synthetic data. I think there are important uses of synthetic data that go beyond just being a preprocessing step for increasing the data set for a learning algorithm. I’d love to see more tools to let developers use synthetic data generation as part of the closed loop of iterative machine learning development.
Do you mean that synthetic data would allow you to try the model on more data sets?
Ng: Not really. Here’s an example. Let’s say you’re trying to detect defects in a smartphone casing. There are many different types of defects on smartphones. It could be a scratch, a dent, pit marks, discoloration of the material, other types of blemishes. If you train the model and then find through error analysis that it’s doing well overall but it’s performing poorly on pit marks, then synthetic data generation allows you to address the problem in a more targeted way. You could generate more data just for the pit-mark category.
“In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models.”
—Andrew Ng
Synthetic data generation is a very powerful tool, but there are many simpler tools that I will often try first. Such as data augmentation, improving labeling consistency, or just asking a factory to collect more data.
To make these issues more concrete, can you walk me through an example? When a company approaches Landing AI and says it has a problem with visual inspection, how do you onboard them and work toward deployment?
Ng: When a customer approaches us we usually have a conversation about their inspection problem and look at a few images to verify that the problem is feasible with computer vision. Assuming it is, we ask them to upload the data to the LandingLens platform. We often advise them on the methodology of data-centric AI and help them label the data.
One of the foci of Landing AI is to empower manufacturing companies to do the machine learning work themselves. A lot of our work is making sure the software is fast and easy to use. Through the iterative process of machine learning development, we advise customers on things like how to train models on the platform, when and how to improve the labeling of data so the performance of the model improves. Our training and software supports them all the way through deploying the trained model to an edge device in the factory.
How do you deal with changing needs? If products change or lighting conditions change in the factory, can the model keep up?
Ng: It varies by manufacturer. There is data drift in many contexts. But there are some manufacturers that have been running the same manufacturing line for 20 years now with few changes, so they don’t expect changes in the next five years. Those stable environments make things easier. For other manufacturers, we provide tools to flag when there’s a significant data-drift issue. I find it really important to empower manufacturing customers to correct data, retrain, and update the model. Because if something changes and it’s 3 a.m. in the United States, I want them to be able to adapt their learning algorithm right away to maintain operations.
In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models. The challenge is, how do you do that without Landing AI having to hire 10,000 machine learning specialists?
So you’re saying that to make it scale, you have to empower customers to do a lot of the training and other work.
Ng: Yes, exactly! This is an industry-wide problem in AI, not just in manufacturing. Look at health care. Every hospital has its own slightly different format for electronic health records. How can every hospital train its own custom AI model? Expecting every hospital’s IT personnel to invent new neural-network architectures is unrealistic. The only way out of this dilemma is to build tools that empower the customers to build their own models by giving them tools to engineer the data and express their domain knowledge. That’s what Landing AI is executing in computer vision, and the field of AI needs other teams to execute this in other domains.
Is there anything else you think it’s important for people to understand about the work you’re doing or the data-centric AI movement?
Ng: In the last decade, the biggest shift in AI was a shift to deep learning. I think it’s quite possible that in this decade the biggest shift will be to data-centric AI. With the maturity of today’s neural network architectures, I think for a lot of the practical applications the bottleneck will be whether we can efficiently get the data we need to develop systems that work well. The data-centric AI movement has tremendous energy and momentum across the whole community. I hope more researchers and developers will jump in and work on it.
You likely know the processor in your PC, but identifying the motherboard might be a bit unclear. Under normal circumstances, many PC users don’t really ...
Since November, registration is open for Mission Space Lab, part of the European Astro Pi Challenge 2023/24. The Astro Pi Challenge is an ESA Education project run in collaboration with us here at the Raspberry Pi Foundation that gives young people up to age 19 the amazing opportunity to write computer programs that run on board the International Space Station (ISS). It is free to take part and young people can participate in two missions: Mission Zero, designed for beginners, and Mission Space Lab, designed for more experienced coders.
This year, Mission Space Lab has a brand-new format. As well as introducing a new activity for teams to work on, we have created new resources to support teams and mentors, and developed a special tool to help teams test their programs.
A big motivator for these changes was to make the activity more accessible and enable more young people to have their code run in space. Listening to feedback from participants and mentors, we are creating the opportunity for even more teams to submit programs that run on the ISS this year, by offering a specific activity and providing more extensive support materials.
A scientific task
For this year’s mission, ESA astronauts have given teams a specific scientific task to solve: to calculate the speed that the ISS is travelling as it orbits the Earth. People working in science often investigate a specific phenomenon or try to solve a particular problem. They have to use their knowledge and skills and the available tools to find ways to answer their research question. For Mission Space Lab, teams will work just like this. They will look at what sensors are available on the Astro Pi computers on board the ISS, develop a solution, and then write a Python program to execute it. To test their program, they will use the new Astro Pi Replay software tool we’ve created, which simulates running their program on board the ISS.
The Astro Pi computers
To help teams and mentors take part in Mission Space Lab, we are providing a variety of supporting materials:
Our mentor guide has everything mentors need to support their teams through Mission Space Lab, including guidance for structuring the mission and tips to help teams solve problems.
Our creator guide helps young people design and create their programs. It provides information and technical instructions to help young people develop their coding skills and create a program that can be run on the Astro Pis on board the ISS.
We have created an ISS speed project guide that shows an example of how the scientific task can be solved using photos captured by the Astro Pi’s camera.
We have also run virtual sessions to help mentors and teams familiarise themselves with the new Mission Space Lab activity, and to ask any technical questions they might have. You can watch the recordings of these sessions on YouTube:
Astro Pi Replay is a new simulation tool that we have developed to support Mission Space Lab teams to test their programs. The tool simulates running programs on the Astro Pi computers on board the ISS. It is a Python library available as a plug-in to install in the Thonny IDE where teams write their programs. Thanks to this tool, teams can develop and test their programs on any computer that supports Python, without the need for hardware like the Astro Pi units on board the ISS.
The Astro Pi Replay tool works by replaying a data set captured by a Mission Space Lab team in May 2023. The data set includes readings from the Astro Pi ‘s sensors, and images taken by its visible-light camera like the ones below. Whenever teams run their programs in Thonny with Astro Pi Replay, the tool replays some of this historical data. That means teams can use the historical data to test their programs and calculations.
The Mediterranean sea with the coastlines of Sicily and Tunisia
The Irish Sea with the coastlines of Great Britain and Ireland
The coastline of southern Egypt and the Red Sea
One of the benefits of using this simulation tool is that it gives teams a taste of what they can expect if their program is run on the ISS. By replaying a sequence of data captured by the Astro Pis in space, teams using sensors will be able to see what kind of data can be collected, and teams using the camera will be able to see some incredible Earth observation images.
If you’re curious about how Astro Pi Replay works, you’ll be pleased to hear we are making it open source soon. That means you’ll be able to look at the source code and find out exactly what the library does and how.
Get involved
Community members have consistently reported how amazing it is for teams to receive unique Earth observation photos and sensor data from the Astro Pis, and how great the images and data are to inspire young people to participate in their computing classes, clubs, or events. Through the changes we’ve made to Mission Space Lab this year, we want to support as many young people as possible to have the opportunity to engage in space science and capture their own data from the ISS.
If you want a taste of how fantastic Astro Pi is for learners, watch the story of St Joseph’s, a rural Irish school where participating in Astro Pi has inspired the whole community.
Submissions for Mission Space Lab 2023/24 are open until 19 February 2024, so there’s still time to take part! You can find full details and eligibility criteria at astro-pi.org/mission-space-lab.
If you have any questions about the European Astro Pi Challenge, please get in touch at contact@astro-pi.org.

 Hands on with Warhorse Studios' massive sequel.
Hands on with Warhorse Studios' massive sequel.



/cdn.vox-cdn.com/uploads/chorus_asset/file/25556678/IMG_8594.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25556680/IMG_8690.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25557006/IMG_8706.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25556645/IMG_8515.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25556644/IMG_8521.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25556635/IMG_8491.jpeg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25556629/IMG_8423.jpeg)


 Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.
Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.











/cdn.vox-cdn.com/uploads/chorus_asset/file/25466129/Hover_20240426_1714137151896.0_ezgif.com_optimize_ezgif.com_optimize.gif)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25431529/IMG_4066.jpg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25434067/Hover_20240425_1714135816951.0.jpeg)























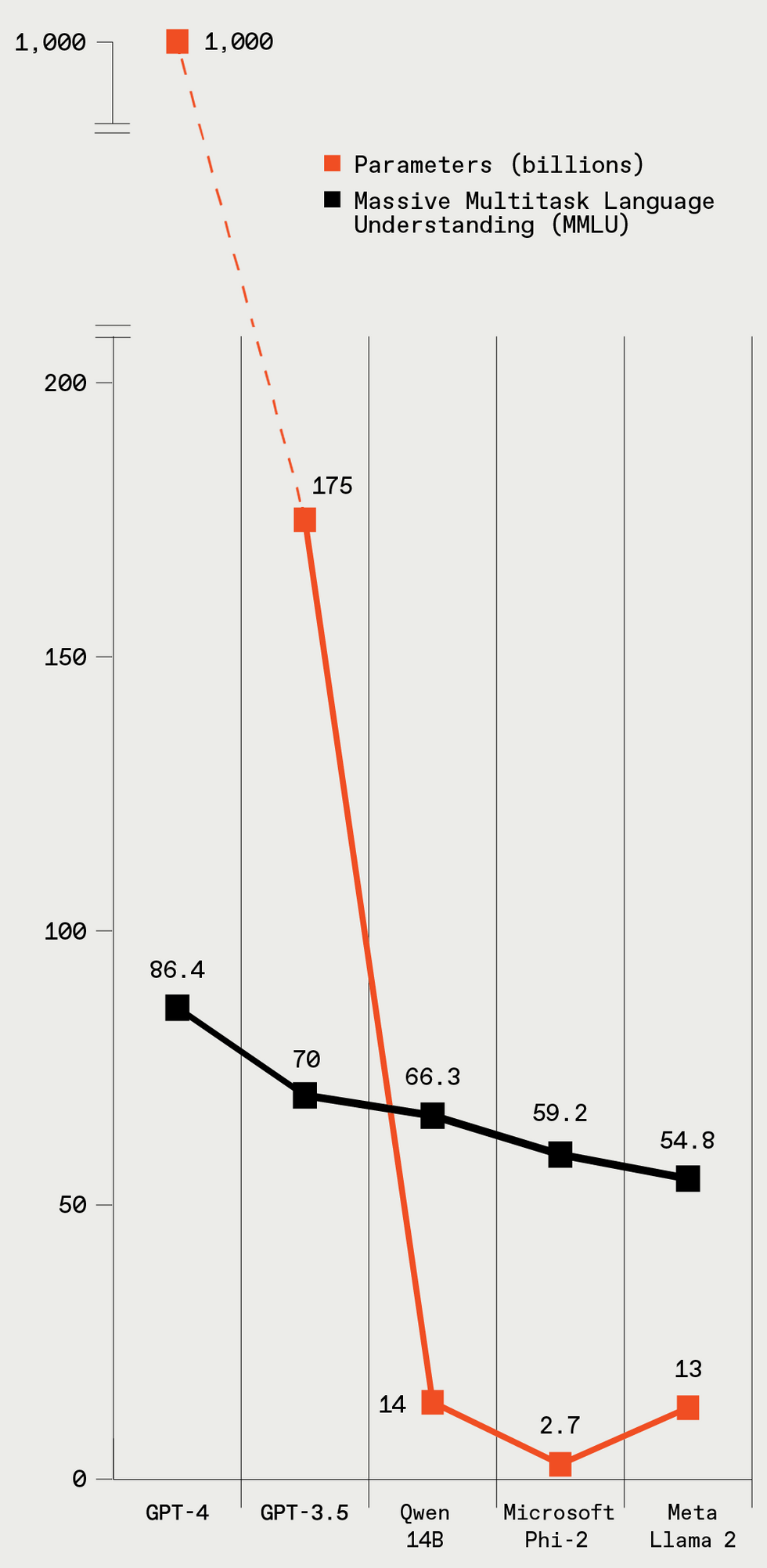 These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum










:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25424932/Hover_20240429_1714372038159.0__1_.jpeg){kind=link}
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25466129/Hover_20240426_1714137151896.0_ezgif.com_optimize_ezgif.com_optimize.gif){kind=link}
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25434067/Hover_20240425_1714135816951.0.jpeg){kind=link}
![[link]](https://i.redd.it/i3l4veyu3yjc1.png){kind=link}