The Ansys SimAI™ cloud-enabled generative artificial intelligence (AI) platform combines the predictive accuracy of Ansys simulation with the speed of generative AI. Because of the software’s versatile underlying neural networks, it can extend to many types of simulation, including structural applications.
This white paper shows how the SimAI cloud-based software applies to highly nonlinear, transient structural simulations, such as automobile crashes, and includes:
Vehicle kinematics and deformation
Forces acting upon the vehicle
How it interacts with its environment
How understanding the changing and rapid sequence of events helps predict outcomes
These simulations can reduce the potential for occupant injuries and the severity of vehicle damage and help understand the crash’s overall dynamics. Ultimately, this leads to safer automotive design.
After withdrawing his lawsuit in June for unknown reasons, Elon Musk has revived a complaint accusing OpenAI and its CEO Sam Altman of fraudulently inducing Musk to contribute $44 million in seed funding by promising that OpenAI would always open-source its technology and prioritize serving the public good over profits as a permanent nonprofit.
Instead, Musk alleged that Altman and his co-conspirators—"preying on Musk’s humanitarian concern about the existential dangers posed by artificial intelligence"—always intended to "betray" these promises in pursuit of personal gains.
As OpenAI's technology advanced toward artificial general intelligence (AGI) and strove to surpass human capabilities, "Altman set the bait and hooked Musk with sham altruism then flipped the script as the non-profit’s technology approached AGI and profits neared, mobilizing Defendants to turn OpenAI, Inc. into their personal piggy bank and OpenAI into a moneymaking bonanza, worth billions," Musk's complaint said.
Last month when Google introduced its new AI search tool, called AI Overviews, the company seemed confident that it had tested the tool sufficiently, noting in the announcement that “people have already used AI Overviews billions of times through our experiment in Search Labs.” The tool doesn’t just return links to Web pages, as in a typical Google search, but returns an answer that it has generated based on various sources, which it links to below the answer. But immediately after the launch users began posting examples of extremely wrong answers, including a pizza recipe that included glue and the interesting fact that a dog has played in the NBA.
Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.
While the pizza recipe is unlikely to convince anyone to squeeze on the Elmer’s, not all of AI Overview’s extremely wrong answers are so obvious—and some have the potential to be quite harmful. Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory and has a new book out about the online propagandists who “turn lies into reality.” She has studied the spread of medical misinformation via social media, so IEEE Spectrum spoke to her about whether AI search is likely to bring an onslaught of erroneous medical advice to unwary users.
I know you’ve been tracking disinformation on the Web for many years. Do you expect the introduction of AI-augmented search tools like Google’s AI Overviews to make the situation worse or better?
Renée DiResta: It’s a really interesting question. There are a couple of policies that Google has had in place for a long time that appear to be in tension with what’s coming out of AI-generated search. That’s made me feel like part of this is Google trying to keep up with where the market has gone. There’s been an incredible acceleration in the release of generative AI tools, and we are seeing Big Tech incumbents trying to make sure that they stay competitive. I think that’s one of the things that’s happening here.
We have long known that hallucinations are a thing that happens with large language models. That’s not new. It’s the deployment of them in a search capacity that I think has been rushed and ill-considered because people expect search engines to give them authoritative information. That’s the expectation you have on search, whereas you might not have that expectation on social media.
There are plenty of examples of comically poor results from AI search, things like how many rocks we should eat per day [a response that was drawn for an Onion article]. But I’m wondering if we should be worried about more serious medical misinformation. I came across one blog post about Google’s AI Overviews responses about stem-cell treatments. The problem there seemed to be that the AI search tool was sourcing its answers from disreputable clinics that were offering unproven treatments. Have you seen other examples of that kind of thing?
DiResta: I have. It’s returning information synthesized from the data that it’s trained on. The problem is that it does not seem to be adhering to the same standards that have long gone into how Google thinks about returning search results for health information. So what I mean by that is Google has, for upwards of 10 years at this point, had a search policy called Your Money or Your Life. Are you familiar with that?
I don’t think so.
DiResta: Your Money or Your Life acknowledges that for queries related to finance and health, Google has a responsibility to hold search results to a very high standard of care, and it’s paramount to get the information correct. People are coming to Google with sensitive questions and they’re looking for information to make materially impactful decisions about their lives. They’re not there for entertainment when they’re asking a question about how to respond to a new cancer diagnosis, for example, or what sort of retirement plan they should be subscribing to. So you don’t want content farms and random Reddit posts and garbage to be the results that are returned. You want to have reputable search results.
That framework of Your Money or Your Life has informed Google’s work on these high-stakes topics for quite some time. And that’s why I think it’s disturbing for people to see the AI-generated search results regurgitating clearly wrong health information from low-quality sites that perhaps happened to be in the training data.
So it seems like AI overviews is not following that same policy—or that’s what it appears like from the outside?
DiResta: That’s how it appears from the outside. I don’t know how they’re thinking about it internally. But those screenshots you’re seeing—a lot of these instances are being traced back to an isolated social media post or a clinic that’s disreputable but exists—are out there on the Internet. It’s not simply making things up. But it’s also not returning what we would consider to be a high-quality result in formulating its response.
I saw that Google responded to some of the problems with a blog post saying that it is aware of these poor results and it’s trying to make improvements. And I can read you the one bullet point that addressed health. It said, “For topics like news and health, we already have strong guardrails in place. In the case of health, we launched additional triggering refinements to enhance our quality protections.” Do you know what that means?
DiResta: That blog posts is an explanation that [AI Overviews] isn’t simply hallucinating—the fact that it’s pointing to URLs is supposed to be a guardrail because that enables the user to go and follow the result to its source. This is a good thing. They should be including those sources for transparency and so that outsiders can review them. However, it is also a fair bit of onus to put on the audience, given the trust that Google has built up over time by returning high-quality results in its health information search rankings.
I know one topic that you’ve tracked over the years has been disinformation about vaccine safety. Have you seen any evidence of that kind of disinformation making its way into AI search?
DiResta: I haven’t, though I imagine outside research teams are now testing results to see what appears. Vaccines have been so much a focus of the conversation around health misinformation for quite some time, I imagine that Google has had people looking specifically at that topic in internal reviews, whereas some of these other topics might be less in the forefront of the minds of the quality teams that are tasked with checking if there are bad results being returned.
What do you think Google’s next moves should be to prevent medical misinformation in AI search?
DiResta: Google has a perfectly good policy to pursue. Your Money or Your Life is a solid ethical guideline to incorporate into this manifestation of the future of search. So it’s not that I think there’s a new and novel ethical grounding that needs to happen. I think it’s more ensuring that the ethical grounding that exists remains foundational to the new AI search tools.
Enlarge/ Features like Image Playground won't arrive in Europe at the same time as other regions. (credit: Apple)
Three major features in iOS 18 and macOS Sequoia will not be available to European users this fall, Apple says. They include iPhone screen mirroring on the Mac, SharePlay screen sharing, and the entire Apple Intelligence suite of generative AI features.
In a statement sent to Financial Times, The Verge, and others, Apple says this decision is related to the European Union's Digital Markets Act (DMA). Here's the full statement, which was attributed to Apple spokesperson Fred Sainz:
Two weeks ago, Apple unveiled hundreds of new features that we are excited to bring to our users around the world. We are highly motivated to make these technologies accessible to all users. However, due to the regulatory uncertainties brought about by the Digital Markets Act (DMA), we do not believe that we will be able to roll out three of these features — iPhone Mirroring, SharePlay Screen Sharing enhancements, and Apple Intelligence — to our EU users this year.
Specifically, we are concerned that the interoperability requirements of the DMA could force us to compromise the integrity of our products in ways that risk user privacy and data security. We are committed to collaborating with the European Commission in an attempt to find a solution that would enable us to deliver these features to our EU customers without compromising their safety.
It is unclear from Apple's statement precisely which aspects of the DMA may have led to this decision. It could be that Apple is concerned that it would be required to give competitors like Microsoft or Google access to user data collected for Apple Intelligence features and beyond, but we're not sure.
“Generative AI is reshaping industries and opening new opportunities for innovation and growth,” NVIDIA founder and CEO Jensen Huang said in an address ahead of this week’s COMPUTEX technology conference in Taipei.
“Today, we’re at the cusp of a major shift in computing,” Huang told the audience, clad in his trademark black leather jacket. “The intersection of AI and accelerated computing is set to redefine the future.”
Huang spoke ahead of one of the world’s premier technology conferences to an audience of more than 6,500 industry leaders, press, entrepreneurs, gamers, creators and AI enthusiasts gathered at the glass-domed National Taiwan University Sports Center set in the verdant heart of Taipei.
The theme: NVIDIA accelerated platforms are in full production, whether through AI PCs and consumer devices featuring a host of NVIDIA RTX-powered capabilities or enterprises building and deploying AI factories with NVIDIA’s full-stack computing platform.
“The future of computing is accelerated,” Huang said. “With our innovations in AI and accelerated computing, we’re pushing the boundaries of what’s possible and driving the next wave of technological advancement.”
‘One-Year Rhythm’
More’s coming, with Huang revealing a roadmap for new semiconductors that will arrive on a one-year rhythm. Revealed for the first time, the Rubin platform will succeed the upcoming Blackwell platform, featuring new GPUs, a new Arm-based CPU — Vera — and advanced networking with NVLink 6, CX9 SuperNIC and the X1600 converged InfiniBand/Ethernet switch.
“Our company has a one-year rhythm. Our basic philosophy is very simple: build the entire data center scale, disaggregate and sell to you parts on a one-year rhythm, and push everything to technology limits,” Huang explained.
NVIDIA’s creative team used AI tools from members of the NVIDIA Inception startup program, built on NVIDIA NIM and NVIDIA’s accelerated computing, to create the COMPUTEX keynote. Packed with demos, this showcase highlighted these innovative tools and the transformative impact of NVIDIA’s technology.
‘Accelerated Computing Is Sustainable Computing’
NVIDIA is driving down the cost of turning data into intelligence, Huang explained as he began his talk.
“Accelerated computing is sustainable computing,” he emphasized, outlining how the combination of GPUs and CPUs can deliver up to a 100x speedup while only increasing power consumption by a factor of three, achieving 25x more performance per Watt over CPUs alone.
“The more you buy, the more you save,” Huang noted, highlighting this approach’s significant cost and energy savings.
Industry Joins NVIDIA to Build AI Factories to Power New Industrial Revolution
Leading computer manufacturers, particularly from Taiwan, the global IT hub, have embraced NVIDIA GPUs and networking solutions. Top companies include ASRock Rack, ASUS, GIGABYTE, Ingrasys, Inventec, Pegatron, QCT, Supermicro, Wistron and Wiwynn, which are creating cloud, on-premises and edge AI systems.
The NVIDIA MGX modular reference design platform now supports Blackwell, including the GB200 NVL2 platform, designed for optimal performance in large language model inference, retrieval-augmented generation and data processing.
AMD and Intel are supporting the MGX architecture with plans to deliver, for the first time, their own CPU host processor module designs. Any server system builder can use these reference designs to save development time while ensuring consistency in design and performance.
Next-Generation Networking with Spectrum-X
In networking, Huang unveiled plans for the annual release of Spectrum-X products to cater to the growing demand for high-performance Ethernet networking for AI.
NVIDIA Spectrum-X, the first Ethernet fabric built for AI, enhances network performance by 1.6x more than traditional Ethernet fabrics. It accelerates the processing, analysis and execution of AI workloads and, in turn, the development and deployment of AI solutions.
CoreWeave, GMO Internet Group, Lambda, Scaleway, STPX Global and Yotta are among the first AI cloud service providers embracing Spectrum-X to bring extreme networking performance to their AI infrastructures.
NVIDIA NIM to Transform Millions Into Gen AI Developers
With NVIDIA NIM, the world’s 28 million developers can now easily create generative AI applications. NIM — inference microservices that provide models as optimized containers — can be deployed on clouds, data centers or workstations.
NIM also enables enterprises to maximize their infrastructure investments. For example, running Meta Llama 3-8B in a NIM produces up to 3x more generative AI tokens on accelerated infrastructure than without NIM.
Nearly 200 technology partners — including Cadence, Cloudera, Cohesity, DataStax, NetApp, Scale AI, and Synopsys — are integrating NIM into their platforms to speed generative AI deployments for domain-specific applications, such as copilots, code assistants, digital human avatars and more. Hugging Face is now offering NIM — starting with Meta Llama 3.
“Today we just posted up in Hugging Face the Llama 3 fully optimized, it’s available there for you to try. You can even take it with you,” Huang said. “So you could run it in the cloud, run it in any cloud, download this container, put it into your own data center, and you can host it to make it available for your customers.”
NVIDIA Brings AI Assistants to Life With GeForce RTX AI PCs
NVIDIA’s RTX AI PCs, powered by RTX technologies, are set to revolutionize consumer experiences with over 200 RTX AI laptops and more than 500 AI-powered apps and games.
And Microsoft and NVIDIA are collaborating to help developers bring new generative AI capabilities to their Windows native and web apps with easy API access to RTX-accelerated SLMs that enable RAG capabilities that run on-device as part of Windows Copilot Runtime.
NVIDIA Robotics Adopted by Industry Leaders
NVIDIA is spearheading the $50 trillion industrial digitization shift, with sectors embracing autonomous operations and digital twins — virtual models that enhance efficiency and cut costs. Through its Developer Program, NVIDIA offers access to NIM, fostering AI innovation.
Taiwanese manufacturers are transforming their factories using NVIDIA’s technology, with Huang showcasing Foxconn’s use of NVIDIA Omniverse, Isaac and Metropolis to create digital twins, combining vision AI and robot development tools for enhanced robotic facilities.
“The next wave of AI is physical AI. AI that understands the laws of physics, AI that can work among us,” Huang said, emphasizing the importance of robotics and AI in future developments.
The NVIDIA Isaac platform provides a robust toolkit for developers to build AI robots, including AMRs, industrial arms and humanoids, powered by AI models and supercomputers like Jetson Orin and Thor.
“Robotics is here. Physical AI is here. This is not science fiction, and it’s being used all over Taiwan. It’s just really, really exciting,” Huang added.
Global electronics giants are integrating NVIDIA’s autonomous robotics into their factories, leveraging simulation in Omniverse to test and validate this new wave of AI for the physical world. This includes over 5 million preprogrammed robots worldwide.
“All the factories will be robotic. The factories will orchestrate robots, and those robots will be building products that are robotic,” Huang explained.
Huang emphasized NVIDIA Isaac’s role in boosting factory and warehouse efficiency, with global leaders like BYD Electronics, Siemens, Teradyne Robotics and Intrinsic adopting its advanced libraries and AI models.
NVIDIA AI Enterprise on the IGX platform, with partners like ADLINK, Advantech and ONYX, delivers edge AI solutions meeting strict regulatory standards, essential for medical technology and other industries.
Huang ended his keynote on the same note he began it on, paying tribute to Taiwan and NVIDIA’s many partners there. “Thank you,” Huang said. “I love you guys.”
Photos of Brazilian kids—sometimes spanning their entire childhood—have been used without their consent to power AI tools, including popular image generators like Stable Diffusion, Human Rights Watch (HRW) warned on Monday.
This act poses urgent privacy risks to kids and seems to increase risks of non-consensual AI-generated images bearing their likenesses, HRW's report said.
An HRW researcher, Hye Jung Han, helped expose the problem. She analyzed "less than 0.0001 percent" of LAION-5B, a dataset built from Common Crawl snapshots of the public web. The dataset does not contain the actual photos but includes image-text pairs derived from 5.85 billion images and captions posted online since 2008.
But such conveniences barely hint at the massive, sweeping changes to employment predicted by some analysts. And already, in ways large and small, striking and subtle, the tech world’s notables are grappling with changes, both real and envisioned, wrought by the onset of generative AI. To get a better idea of how some of them view the future of generative AI, IEEE Spectrum asked three luminaries—an academic leader, a regulator, and a semiconductor industry executive—about how generative AI has begun affecting their work. The three, Andrea Goldsmith, Juraj Čorba, and Samuel Naffziger, agreed to speak with Spectrum at the 2024 IEEE VIC Summit & Honors Ceremony Gala, held in May in Boston.
Juraj Čorba, senior expert on digital regulation and governance, Slovak Ministry of Investments, Regional Development
Samuel Naffziger, senior vice president and a corporate fellow at Advanced Micro Devices
Andrea Goldsmith
Andrea Goldsmith is dean of engineering at Princeton University.
There must be tremendous pressure now to throw a lot of resources into large language models. How do you deal with that pressure? How do you navigate this transition to this new phase of AI?
Andrea J. Goldsmith
Andrea Goldsmith: Universities generally are going to be very challenged, especially universities that don’t have the resources of a place like Princeton or MIT or Stanford or the other Ivy League schools. In order to do research on large language models, you need brilliant people, which all universities have. But you also need compute power and you need data. And the compute power is expensive, and the data generally sits in these large companies, not within universities.
So I think universities need to be more creative. We at Princeton have invested a lot of money in the computational resources for our researchers to be able to do—well, not large language models, because you can’t afford it. To do a large language model… look at OpenAI or Google or Meta. They’re spending hundreds of millions of dollars on compute power, if not more. Universities can’t do that.
But we can be more nimble and creative. What can we do with language models, maybe not large language models but with smaller language models, to advance the state of the art in different domains? Maybe it’s vertical domains of using, for example, large language models for better prognosis of disease, or for prediction of cellular channel changes, or in materials science to decide what’s the best path to pursue a particular new material that you want to innovate on. So universities need to figure out how to take the resources that we have to innovate using AI technology.
We also need to think about new models. And the government can also play a role here. The [U.S.] government has this new initiative, NAIRR, or National Artificial Intelligence Research Resource, where they’re going to put up compute power and data and experts for educators to use—researchers and educators.
That could be a game-changer because it’s not just each university investing their own resources or faculty having to write grants, which are never going to pay for the compute power they need. It’s the government pulling together resources and making them available to academic researchers. So it’s an exciting time, where we need to think differently about research—meaning universities need to think differently. Companies need to think differently about how to bring in academic researchers, how to open up their compute resources and their data for us to innovate on.
As a dean, you are in a unique position to see which technical areas are really hot, attracting a lot of funding and attention. But how much ability do you have to steer a department and its researchers into specific areas? Of course, I’m thinking about large language models and generative AI. Is deciding on a new area of emphasis or a new initiative a collaborative process?
Goldsmith: Absolutely. I think any academic leader who thinks that their role is to steer their faculty in a particular direction does not have the right perspective on leadership. I describe academic leadership as really about the success of the faculty and students that you’re leading. And when I did my strategic planning for Princeton Engineering in the fall of 2020, everything was shut down. It was the middle of COVID, but I’m an optimist. So I said, “Okay, this isn’t how I expected to start as dean of engineering at Princeton.” But the opportunity to lead engineering in a great liberal arts university that has aspirations to increase the impact of engineering hasn’t changed. So I met with every single faculty member in the School of Engineering, all 150 of them, one-on-one over Zoom.
And the question I asked was, “What do you aspire to? What should we collectively aspire to?” And I took those 150 responses, and I asked all the leaders and the departments and the centers and the institutes, because there already were some initiatives in robotics and bioengineering and in smart cities. And I said, “I want all of you to come up with your own strategic plans. What do you aspire to in these areas? And then let’s get together and create a strategic plan for the School of Engineering.” So that’s what we did. And everything that we’ve accomplished in the last four years that I’ve been dean came out of those discussions, and what it was the faculty and the faculty leaders in the school aspired to.
So we launched a bioengineering institute last summer. We just launched Princeton Robotics. We’ve launched some things that weren’t in the strategic plan that bubbled up. We launched a center on blockchain technology and its societal implications. We have a quantum initiative. We have an AI initiative using this powerful tool of AI for engineering innovation, not just around large language models, but it’s a tool—how do we use it to advance innovation and engineering? All of these things came from the faculty because, to be a successful academic leader, you have to realize that everything comes from the faculty and the students. You have to harness their enthusiasm, their aspirations, their vision to create a collective vision.
What are the most important organizations and governing bodies when it comes to policy and governance on artificial intelligence in Europe?
Juraj Čorba
Juraj Čorba: Well, there are many. And it also creates a bit of a confusion around the globe—who are the actors in Europe? So it’s always good to clarify. First of all we have the European Union, which is a supranational organization composed of many member states, including my own Slovakia. And it was the European Union that proposed adoption of a horizontal legislation for AI in 2021. It was the initiative of the European Commission, the E.U. institution, which has a legislative initiative in the E.U. And the E.U. AI Act is now finally being adopted. It was already adopted by the European Parliament.
So this started, you said 2021. That’s before ChatGPT and the whole large language model phenomenon really took hold.
Čorba: That was the case. Well, the expert community already knew that something was being cooked in the labs. But, yes, the whole agenda of large models, including large language models, came up only later on, after 2021. So the European Union tried to reflect that. Basically, the initial proposal to regulate AI was based on a blueprint of so-called product safety, which somehow presupposes a certain intended purpose. In other words, the checks and assessments of products are based more or less on the logic of the mass production of the 20th century, on an industrial scale, right? Like when you have products that you can somehow define easily and all of them have a clearly intended purpose. Whereas with these large models, a new paradigm was arguably opened, where they have a general purpose.
So the whole proposal was then rewritten in negotiations between the Council of Ministers, which is one of the legislative bodies, and the European Parliament. And so what we have today is a combination of this old product-safety approach and some novel aspects of regulation specifically designed for what we call general-purpose artificial intelligence systems or models. So that’s the E.U.
By product safety, you mean, if AI-based software is controlling a machine, you need to have physical safety.
Čorba: Exactly. That’s one of the aspects. So that touches upon the tangible products such as vehicles, toys, medical devices, robotic arms, et cetera. So yes. But from the very beginning, the proposal contained a regulation of what the European Commission called stand-alone systems—in other words, software systems that do not necessarily command physical objects. So it was already there from the very beginning, but all of it was based on the assumption that all software has its easily identifiable intended purpose—which is not the case for general-purpose AI.
Also, large language models and generative AI in general brings in this whole other dimension, of propaganda, false information, deepfakes, and so on, which is different from traditional notions of safety in real-time software.
Čorba: Well, this is exactly the aspect that is handled by another European organization, different from the E.U., and that is the Council of Europe. It’s an international organization established after the Second World War for the protection of human rights, for protection of the rule of law, and protection of democracy. So that’s where the Europeans, but also many other states and countries, started to negotiate a first international treaty on AI. For example, the United States have participated in the negotiations, and also Canada, Japan, Australia, and many other countries. And then these particular aspects, which are related to the protection of integrity of elections, rule-of-law principles, protection of fundamental rights or human rights under international law—all these aspects have been dealt with in the context of these negotiations on the first international treaty, which is to be now adopted by the Committee of Ministers of the Council of Europe on the 16th and 17th of May. So, pretty soon. And then the first international treaty on AI will be submitted for ratifications.
So prompted largely by the activity in large language models, AI regulation and governance now is a hot topic in the United States, in Europe, and in Asia. But of the three regions, I get the sense that Europe is proceeding most aggressively on this topic of regulating and governing artificial intelligence. Do you agree that Europe is taking a more proactive stance in general than the United States and Asia?
Čorba: I’m not so sure. If you look at the Chinese approach and the way they regulate what we call generative AI, it would appear to me that they also take it very seriously. They take a different approach from the regulatory point of view. But it seems to me that, for instance, China is taking a very focused and careful approach. For the United States, I wouldn’t say that the United States is not taking a careful approach because last year you saw many of the executive orders, or even this year, some of the executive orders issued by President Biden. Of course, this was not a legislative measure, this was a presidential order. But it seems to me that the United States is also trying to address the issue very actively. The United States has also initiated the first resolution of the General Assembly at the U.N. on AI, which was passed just recently. So I wouldn’t say that the E.U. is more aggressive in comparison with Asia or North America, but maybe I would say that the E.U. is the most comprehensive. It looks horizontally across different agendas and it uses binding legislation as a tool, which is not always the case around the world. Many countries simply feel that it’s too early to legislate in a binding way, so they opt for soft measures or guidance, collaboration with private companies, et cetera. Those are the differences that I see.
Do you think you perceive a difference in focus among the three regions? Are there certain aspects that are being more aggressively pursued in the United States than in Europe or vice versa?
Čorba: Certainly the E.U. is very focused on the protection of human rights, the full catalog of human rights, but also, of course, on safety and human health. These are the core goals or values to be protected under the E.U. legislation. As for the United States and for China, I would say that the primary focus in those countries—but this is only my personal impression—is on national and economic security.
Samuel Naffziger
Samuel Naffziger is senior vice president and a corporate fellow at Advanced Micro Devices, where he is responsible for technology strategy and product architectures. Naffziger was instrumental in AMD’s embrace and development of chiplets, which are semiconductor dies that are packaged together into high-performance modules.
To what extent is large language model training starting to influence what you and your colleagues do at AMD?
Samuel Naffziger
Samuel Naffziger: Well, there are a couple levels of that. LLMs are impacting the way a lot of us live and work. And we certainly are deploying that very broadly internally for productivity enhancements, for using LLMs to provide starting points for code—simple verbal requests, such as “Give me a Python script to parse this dataset.” And you get a really nice starting point for that code. Saves a ton of time. Writing verification test benches, helping with the physical design layout optimizations. So there’s a lot of productivity aspects.
The other aspect to LLMs is, of course, we are actively involved in designing GPUs [graphics processing units] for LLM training and for LLM inference. And so that’s driving a tremendous amount of workload analysis on the requirements, hardware requirements, and hardware-software codesign, to explore.
So that brings us to your current flagship, the Instinct MI300X, which is actually billed as an AI accelerator. How did the particular demands influence that design? I don’t know when that design started, but the ChatGPT era started about two years ago or so. To what extent did you read the writing on the wall?
Naffziger: So we were just into the MI300—in 2019, we were starting the development. A long time ago. And at that time, our revenue stream from the Zen [an AMD architecture used in a family of processors] renaissance had really just started coming in. So the company was starting to get healthier, but we didn’t have a lot of extra revenue to spend on R&D at the time. So we had to be very prudent with our resources. And we had strategic engagements with the [U.S.] Department of Energy for supercomputer deployments. That was the genesis for our MI line—we were developing it for the supercomputing market. Now, there was a recognition that munching through FP64 COBOL code, or Fortran, isn’t the future, right? [laughs] This machine-learning [ML] thing is really getting some legs.
So we put some of the lower-precision math formats in, like Brain Floating Point 16 at the time, that were going to be important for inference. And the DOE knew that machine learning was going to be an important dimension of supercomputers, not just legacy code. So that’s the way, but we were focused on HPC [high-performance computing]. We had the foresight to understand that ML had real potential. Although certainly no one predicted, I think, the explosion we’ve seen today.
So that’s how it came about. And, just another piece of it: We leveraged our modular chiplet expertise to architect the 300 to support a number of variants from the same silicon components. So the variant targeted to the supercomputer market had CPUs integrated in as chiplets, directly on the silicon module. And then it had six of the GPU chiplets we call XCDs around them. So we had three CPU chiplets and six GPU chiplets. And that provided an amazingly efficient, highly integrated, CPU-plus-GPU design we call MI300A. It’s very compelling for the El Capitan supercomputer that’s being brought up as we speak.
But we also recognize that for the maximum computation for these AI workloads, the CPUs weren’t that beneficial. We wanted more GPUs. For these workloads, it’s all about the math and matrix multiplies. So we were able to just swap out those three CPU chiplets for a couple more XCD GPUs. And so we got eight XCDs in the module, and that’s what we call the MI300X. So we kind of got lucky having the right product at the right time, but there was also a lot of skill involved in that we saw the writing on the wall for where these workloads were going and we provisioned the design to support it.
Earlier you mentioned 3D chiplets. What do you feel is the next natural step in that evolution?
Naffziger: AI has created this bottomless thirst for more compute [power]. And so we are always going to be wanting to cram as many transistors as possible into a module. And the reason that’s beneficial is, these systems deliver AI performance at scale with thousands, tens of thousands, or more, compute devices. They all have to be tightly connected together, with very high bandwidths, and all of that bandwidth requires power, requires very expensive infrastructure. So if a certain level of performance is required—a certain number of petaflops, or exaflops—the strongest lever on the cost and the power consumption is the number of GPUs required to achieve a zettaflop, for instance. And if the GPU is a lot more capable, then all of that system infrastructure collapses down—if you only need half as many GPUs, everything else goes down by half. So there’s a strong economic motivation to achieve very high levels of integration and performance at the device level. And the only way to do that is with chiplets and with 3D stacking. So we’ve already embarked down that path. A lot of tough engineering problems to solve to get there, but that’s going to continue.
And so what’s going to happen? Well, obviously we can add layers, right? We can pack more in. The thermal challenges that come along with that are going to be fun engineering problems that our industry is good at solving.
Microsoft recently caught state-backed hackers using its generative AI tools to help with their attacks. In the security community, the immediate questions weren’t about how hackers were using the tools (that was utterly predictable), but about how Microsoft figured it out. The natural conclusion was that Microsoft was spying on its AI users, looking for harmful hackers at work.
Some pushed back at characterizing Microsoft’s actions as “spying.” Of course cloud service providers monitor what users are doing. And because we expect Microsoft to be doing something like this, it’s not fair to call it spying.
We see this argument as an example of our shifting collective expectations of privacy. To understand what’s happening, we can learn from an unlikely source: fish.
In the mid-20th century, scientists began noticing that the number of fish in the ocean—so vast as to underlie the phrase “There are plenty of fish in the sea”—had started declining rapidly due to overfishing. They had already seen a similar decline in whale populations, when the post-WWII whaling industry nearly drove many species extinct. In whaling and later in commercial fishing, new technology made it easier to find and catch marine creatures in ever greater numbers. Ecologists, specifically those working in fisheries management, began studying how and when certain fish populations had gone into serious decline.
One scientist, Daniel Pauly, realized that researchers studying fish populations were making a major error when trying to determine acceptable catch size. It wasn’t that scientists didn’t recognize the declining fish populations. It was just that they didn’t realize how significant the decline was. Pauly noted that each generation of scientists had a different baseline to which they compared the current statistics, and that each generation’s baseline was lower than that of the previous one.
What seems normal to us in the security community is whatever was commonplace at the beginning of our careers.
Pauly called this “shifting baseline syndrome” in a 1995 paper. The baseline most scientists used was the one that was normal when they began their research careers. By that measure, each subsequent decline wasn’t significant, but the cumulative decline was devastating. Each generation of researchers came of age in a new ecological and technological environment, inadvertently masking an exponential decline.
Pauly’s insights came too late to help those managing some fisheries. The ocean suffered catastrophes such as the complete collapse of the Northwest Atlantic cod population in the 1990s.
Internet surveillance, and the resultant loss of privacy, is following the same trajectory. Just as certain fish populations in the world’s oceans have fallen 80 percent, from previously having fallen 80 percent, from previously having fallen 80 percent (ad infinitum), our expectations of privacy have similarly fallen precipitously. The pervasive nature of modern technology makes surveillance easier than ever before, while each successive generation of the public is accustomed to the privacy status quo of their youth. What seems normal to us in the security community is whatever was commonplace at the beginning of our careers.
Historically, people controlled their computers, and software was standalone. The always-connected cloud-deployment model of software and services flipped the script. Most apps and services are designed to be always-online, feeding usage information back to the company. A consequence of this modern deployment model is that everyone—cynical tech folks and even ordinary users—expects that what you do with modern tech isn’t private. But that’s because the baseline has shifted.
AI chatbots are the latest incarnation of this phenomenon: They produce output in response to your input, but behind the scenes there’s a complex cloud-based system keeping track of that input—both to improve the service and to sell you ads.
Shifting baselines are at the heart of our collective loss of privacy. The U.S. Supreme Court has long held that our right to privacy depends on whether we have a reasonable expectation of privacy. But expectation is a slippery thing: It’s subject to shifting baselines.
The question remains: What now? Fisheries scientists, armed with knowledge of shifting-baseline syndrome, now look at the big picture. They no longer consider relative measures, such as comparing this decade with the last decade. Instead, they take a holistic, ecosystem-wide perspective to see what a healthy marine ecosystem and thus sustainable catch should look like. They then turn these scientifically derived sustainable-catch figures into limits to be codified by regulators.
In privacy and security, we need to do the same. Instead of comparing to a shifting baseline, we need to step back and look at what a healthy technological ecosystem would look like: one that respects people’s privacy rights while also allowing companies to recoup costs for services they provide. Ultimately, as with fisheries, we need to take a big-picture perspective and be aware of shifting baselines. A scientifically informed and democratic regulatory process is required to preserve a heritage—whether it be the ocean or the Internet—for the next generation.
Building on more than a dozen years of stacking wins at the COMPUTEX trade show’s annual Best Choice Awards, NVIDIA was today honored with BCAs for its latest technologies.
The awards — judged on the functionality, innovation and market potential of products exhibited at the leading computer and technology expo — were announced ahead of the show, which runs from June 4-7, in Taipei.
NVIDIA founder and CEO Jensen Huang will deliver a COMPUTEX keynote address on Sunday, June 2, at 7 p.m. Taiwan time, at the NTU Sports Center and online.
NVIDIA AI Enterprise Takes Gold
NVIDIA AI Enterprise — a cloud-native software platform that streamlines the development and deployment of copilots and other generative AI applications — won a Golden Award.
The platform lifts the burden of maintaining and securing complex AI software, so businesses can focus on building and harnessing the technology’s game-changing insights.
Microservices that come with NVIDIA AI Enterprise — including NVIDIA NIM and NVIDIA CUDA-X — optimize model performance and run anywhere with enterprise-grade security, support and stability, offering users a smooth transition from prototype to production.
Plus, the platform’s ability to improve AI performance results in better overall utilization of computing resources. This means companies using NVIDIA AI Enterprise need fewer servers to support the same workloads, greatly reducing their energy costs and data center footprint.
More BCA Wins for NVIDIA Technologies
NVIDIA GH200 and Spectrum-X were named best in their respective categories.
The NVIDIA GH200 Grace Hopper Superchip is the world’s first truly heterogeneous accelerated platform for AI and high-performance computing workloads. It combines the power-efficient NVIDIA Grace CPU with an NVIDIA Hopper architecture-based GPU over a high-bandwidth 900GB/s coherent NVIDIA NVLink chip-to-chip interconnect.
The Spectrum-X platform, featuring NVIDIA Spectrum SN5600 switches and NVIDIA BlueField-3 SuperNICs, is the world’s first Ethernet fabric built for AI, accelerating generative AI network performance 1.6x over traditional Ethernet fabrics.
It can serve as the backend AI fabric for any AI cloud or large enterprise deployment, and is available from major server manufacturers as part of the full NVIDIA AI stack.
NVIDIA Partners Recognized
Other BCA winners include NVIDIA partners Acer, ASUS, MSI and YUAN, which were given Golden Awards for their respective laptops, gaming motherboards and smart-city applications — all powered by NVIDIA technologies, such as NVIDIA GeForce RTX 4090 GPUs, the NVIDIA Studio platform for creative workflows and the NVIDIA Jetson platform for edge AI and robotics.
ASUS also won a Computer and System Category Award, while MSI won a Gaming and Entertainment Category Award.
Learn more about the latest generative AI, HPC and networking technologies by joining NVIDIA at COMPUTEX.
Generative AI (GenAI) burst onto the scene and into the public’s imagination with the launch of ChatGPT in late 2022. Users were amazed at the natural language processing chatbot’s ability to turn a short text prompt into coherent humanlike text including essays, language translations, and code examples. Technology companies – impressed with ChatGPT’s abilities – have started looking for ways to improve their own products or customer experiences with this innovative technology. Since the ‘cost’ of adding GenAI includes a significant jump in computational complexity and power requirements versus previous AI models, can this class of AI algorithms be applied to practical edge device applications where power, performance and cost are critical? It depends.
What is GenAI?
A simple definition of GenAI is ‘a class of machine learning algorithms that can produce various types of content including human like text and images.’ Early machine learning algorithms focused on detecting patterns in images, speech or text and then making predictions based on the data. For example, predicting the percentage likelihood that a certain image included a cat. GenAI algorithms take the next step – they perceive and learn patterns and then generate new patterns on demand by mimicking the original dataset. They generate a new image of a cat or describe a cat in detail.
While ChatGPT might be the most well-known GenAI algorithm, there are many available, with more being released on a regular basis. Two major types of GenAI algorithms are text-to-text generators – aka chatbots – like ChatGPT, GPT-4, and Llama2, and text-to-image generative model like DALLE-2, Stable Diffusion, and Midjourney. You can see example prompts and their returned outputs of these two types of GenAI models in figure 1. Because one is text based and one is image based, these two types of outputs will demand different resources from edge devices attempting to implement these algorithms.
Fig. 1: Example GenAI outputs from a text-to-image generator (DALLE-2) and a text-to-text generator (ChatGPT).
Edge device applications for Gen AI
Common GenAI use cases require connection to the internet and from there access to large server farms to compute the complex generative AI algorithms. However, for edge device applications, the entire dataset and neural processing engine must reside on the individual edge device. If the generative AI models can be run at the edge, there are potential use cases and benefits for applications in automobiles, cameras, smartphones, smart watches, virtual and augmented reality, IoT, and more.
Deploying GenAI on edge devices has significant advantages in scenarios where low latency, privacy or security concerns, or limited network connectivity are critical considerations.
Consider the possible application of GenAI in automotive applications. A vehicle is not always in range of a wireless signal, so GenAI needs to run with resources available on the edge. GenAI could be used for improving roadside assistance and converting a manual into an AI-enhanced interactive guide. In-car uses could include a GenAI-powered virtual voice assistant, improving the ability to set navigation, play music or send messages with your voice while driving. GenAI could also be used to personalize your in-cabin experience.
Other edge applications could benefit from generative AI. Augmented Reality (AR) edge devices could be enhanced by locally generating overlay computer-generated imagery and relying less heavily on cloud processing. While connected mobile devices can use generative AI for translation services, disconnected devices should be able to offer at least a portion of the same capabilities. Like our automotive example, voice assistant and interactive question-and-answer systems could benefit a range of edge devices.
While uses cases for GenAI at the edge exist now, implementations must overcome the challenges related to computational complexity and model size and limitations of power, area, and performance inherent in edge devices.
What technology is required to enable GenAI?
To understand GenAI’s architectural requirements, it is helpful to understand its building blocks. At the heart of GenAI’s rapid development are transformers, a relatively new type of neural network introduced in a Google Brain paper in 2017. Transformers have outperformed established AI models like Recurrent Neural Networks (RNNs) for natural language processing and Convolutional Neural Networks (CNNs) for images, video or other two- or three-dimensional data. A significant architectural improvement of a transformer model is its attention mechanism. Transformers can pay more attention to specific words or pixels than legacy AI models, drawing better inferences from the data. This allows transformers to better learn contextual relationships between words in a text string compared to RNNs and to better learn and express complex relationships in images compared to CNNs.
Fig. 2: Parameter sizes for various machine learning algorithms.
GenAI models are pre-trained on vast amounts of data which allows them to better recognize and interpret human language or other types of complex data. The larger the datasets, the better the model can process human language, for instance. Compared to CNN or vision transformer machine learning models, GenAI algorithms have parameters – the pretrained weights or coefficients used in the neural network to identify patterns and create new ones – that are orders of magnitude larger. We can see in figure 2 that ResNet50 – a common CNN algorithm used for benchmarking – has 25 million parameters (or coefficients). Some transformers like BERT and Vision Transformer (ViT) have parameters in the hundreds of millions. While other transformers, like Mobile ViT, have been optimized to better fit in embedded and mobile applications. MobileViT is comparable to the CNN model MobileNet in parameters.
Compared to CNN and vision transformers, ChatGPT requires 175 billion parameters and GPT-4 requires 1.75 trillion parameters. Even GPUs implemented in server farms struggle to execute these high-end large language models. How could an embedded neural processing unit (NPU) hope to complete so many parameters given the limited memory resources of edge devices? The answer is they cannot. However, there is a trend toward making GenAI more accessible in edge device applications, which have more limited computation resources. Some LLM models are tuned to reduce the resource requirements for a reduced parameter set. For example, Llama-2 offers a 70 billion parameter version of their model, but they also have created smaller models with fewer parameters. Llama-2 with seven billion parameters is still large, but it is within reach of a practical embedded NPU implementation.
There is no hard threshold for generative AI running on the edge, however, text-to-image generators like Stable Diffusion with one billion parameters can run comfortably on an NPU. And the expectation is for edge devices to run LLMs up to six to seven billion parameters. MLCommons have added GPT-J, a six billion parameter GenAI model, to their MLPerf edge AI benchmark list.
Running GenAI on the edge
GenAI algorithms require a significant amount of data movement and computation complexity (with transformer support). The balance of those two requirements can determine whether a given architecture is compute-bound – not enough multiplications for the data available – or memory bound – not enough memory and/or bandwidth for all the multiplications required for processing. Text-to-image has a better mix of compute and bandwidth requirements – more computations needed for processing two dimensional images and fewer parameters (in the one billion range). Large language models are more lopsided. There is less compute required, but a significantly large amount of data movement. Even the smaller (6-7B parameter) LLMs are memory bound.
The obvious solution is to choose the fastest memory interface available. From figure 3, you can see that a typically memory used in edge devices, LPDDR5, has a bandwidth of 51 Gbps, while HBM2E can support up to 461 Gbps. This does not, however, take into consideration the power-down benefits of LPDDR memory over HBM. While HBM interfaces are often used in high-end server-type AI implementations, LPDDR is almost exclusively used in power sensitive applications because of its power down abilities.
Fig. 3: The bandwidth and power difference between LPDDR and HBM.
Using LPDDR memory interfaces will automatically limit the maximum data bandwidth achievable with an HBM memory interface. That means edge applications will automatically have less bandwidth for GenAI algorithms than an NPU or GPU used in a server application. One way to address bandwidth limitations is to increase the amount of on-chip L2 memory. However, this impacts area and, therefore, silicon cost. While embedded NPUs often implement hardware and software to reduce bandwidth, it will not allow an LPDDR to approach HBM bandwidths. The embedded AI engine will be limited to the amount of LPDDR bandwidth available.
Implementation of GenAI on an NPX6 NPU IP
The Synopsys ARC NPX6 NPU IP family is based on a sixth-generation neural network architecture designed to support a range of machine learning models including CNNs and transformers. The NPX6 family is scalable with a configurable number of cores, each with its own independent matrix multiplication engine, generic tensor accelerator (GTA), and dedicated direct memory access (DMA) units for streamlined data processing. The NPX6 can scale for applications requiring less than one TOPS of performance to those requiring thousands of TOPS using the same development tools to maximize software reuse.
The matrix multiplication engine, GTA and DMA have all been optimized for supporting transformers, which allow the ARC NPX6 to support GenAI algorithms. Each core’s GTA is expressly designed and optimized to efficiently perform nonlinear functions, such as ReLU, GELU, sigmoid. These are implemented using a flexible lookup table approach to anticipate future nonlinear functions. The GTA also supports other critical operations, including SoftMax and L2 normalization needed in transformers. Complementing this, the matrix multiplication engine within each core can perform 4,096 multiplications per cycle. Because GenAI is based on transformers, there are no computation limitations for running GenAI on the NPX6 processor.
Efficient NPU design for transformer-based models like GenAI requires complex multi-level memory management. The ARC NPX6 processor has a flexible memory hierarchy and can support a scalable L2 memory up to 64MB of on chip SRAM. Furthermore, each NPX6 core is equipped with independent DMAs dedicated to the tasks of fetching feature maps and coefficients and writing new feature maps. This segregation of tasks allows for an efficient, pipelined data flow that minimizes bottlenecks and maximizes the processing throughput. The family also has a range of bandwidth reduction techniques in hardware and software to maximize bandwidth.
In an embedded GenAI application, the ARC NPX6 family will only be limited by the LPDDR available in the system. The NPX6 successfully runs Stable Diffusion (text-to-image) and Llama-2 7B (text-to-text) GenAI algorithms with efficiency dependent on system bandwidth and the use of on-chip SRAM. While larger GenAI models could run on the NPX6, they will be slower – measured in tokens per second – than server implementations. Learn more at www.synopsys.com/npx
Questions are surfacing for all types of design, ranging from small microcontrollers to leading-edge chips, over whether domain-specific design will become ubiquitous, or whether it will fall into the historic pattern of customization first, followed by lower-cost, general-purpose components.
Custom hardware always has been a double-edged sword. It can provide a competitive edge for chipmakers, but often requires more time to design, verify, and manufacture a chip, which can sometimes cost a market window. In addition, it’s often too expensive for all but the most price-resilient applications. This is a well-understood equation at the leading edge of design, particularly where new technologies such as generative AI are involved.
But with planar scaling coming to an end, and with more features tailored to specific domains, the chip industry is struggling to figure out whether the business/technical equation is undergoing a fundamental and more permanent change. This is muddied further by the fact that some 30% to 35% of all design tools today are being sold to large systems companies for chips that will never be sold commercially. In those applications, the collective savings from improved performance per watt may dwarf the cost of designing, verifying, and manufacturing a highly optimized multi-chip/multi-chiplet package across a large data center, leaving the debate about custom vs. general-purpose more uncertain than ever.
“If you go high enough in the engineering organization, you’re going to find that what people really want to do is a software-defined whatever it is,” says Russell Klein, program director for high-level synthesis at Siemens EDA. “What they really want to do is buy off-the-shelf hardware, put some software on it, make that their value-add, and ship that. That paradigm is breaking down in a number of domains. It is breaking down where we need either extremely high performance, or we need extreme efficiency. If we need higher performance than we can get from that off-the-shelf system, or we need greater efficiency, we need the battery to last longer, or we just can’t burn as much power, then we’ve got to start customizing the hardware.”
Even the selection of processing units can make a solution custom. “Domain-specific computing is already ubiquitous,” says Dave Fick, CEO and cofounder of Mythic. “Modern computers, whether in a laptop, phone, security camera, or in farm equipment, consist of a mix of hardware blocks co-optimized with software. For instance, it is common for a computer to have video encode or decode hardware units to allow a system to connect to a camera efficiently. It is common to have accelerators for encryption so that we can safely communicate. Each of these is co-optimized with software algorithms to make commonly used functions highly efficient and flexible.”
Steve Roddy, chief marketing officer at Quadric, agrees. “Heterogeneous processing in SoCs has been de rigueur in the vast majority of consumer applications for the past two decades or more. SoCs for mobile phones, tablets, televisions, and automotive applications have long been required to meet a grueling combination of high-performance plus low-cost requirements, which has led to the proliferation of function-specific processors found in those systems today. Even low-cost SoCs for mobile phones today have CPUs for running Android, complex GPUs to paint the display screen, audio DSPs for offloading audio playback in a low-power mode, video DSPs paired with NPUs in the camera subsystem to improve image capture (stabilization, filters, enhancement), baseband DSPs — often with attached NPUs — for high speed communications channel processing in the Wi-Fi and 5G subsystems, sensor hub fusion DSPs, and even power-management processors that maximize battery life.”
It helps to separate what you call general-purpose and what is application-specific. “There is so much benefit to be had from running your software on dedicated hardware, what we call bespoke silicon, because it gives you an advantage over your competitors,” says Marc Swinnen, director of product marketing in Ansys’ Semiconductor Division. “Your software runs faster, lower power, and is designed to run specifically what you want to run. It’s hard for a competitor with off-the-shelf hardware to compete with you. Silicon has become so central to the business value, the business model, of many companies that it has become important to have that optimized.”
There is a balance, however. “If there is any cost justification in terms of return on investment and deployment costs, power costs, thermal costs, cooling costs, then it always makes sense to build a custom ASIC,” says Sharad Chole, chief scientist and co-founder of Expedera. “We saw that for cryptocurrency, we see that right now for AI. We saw that for edge computing, which requires extremely ultra-low power sensors and ultra-low power processes. But there also has been a push for general-purpose computing hardware, because then you can easily make the applications more abstract and scalable.”
Part of the seeming conflict is due to the scope of specificity. “When you look at the architecture, it’s really the scope that determines the application specificity,” says Frank Schirrmeister, vice president of solutions and business development at Arteris. “Domain-specific computing is ubiquitous now. The important part is the constant moving up of the domain specificity to something more complex — from the original IP, to configurable IP, to subsystems that are configurable.”
In the past, it has been driven more by economics. “There’s an ebb and a flow to it,” says Paul Karazuba, vice president of marketing at Expedera. “There’s an ebb and a flow to putting everything into a processor. There’s an ebb and a flow to having co-processors, augmenting functions that are inside of that main processor. It’s a natural evolution of pretty much everything. It may not necessarily be cheaper to design your own silicon, but it may be more expensive in the long run to not design your own silicon.”
An attempt to formalize that ebb and flow was made by Tsugio Makimoto in the 1990s, when he was Sony’s CTO. He observed that electronics cycled between custom solutions and programmable ones approximately every 10 years. What’s changed is that most custom chips from the time of his observation contained highly programmable standard components.
Technology drivers
Today, it would appear that technical issues will decide this. “The industry has managed to work around power issues and push up the thermal envelope beyond points I personally thought were going to be reasonable, or feasible,” says Elad Alon, co-founder and CEO of Blue Cheetah. “We’re hitting that power limit, and when you hit the power limit it drives you toward customization wherever you can do it. But obviously, there is tension between flexibility, scalability, and applicability to the broadest market possible. This is seen in the fast pace of innovation in the AI software world, where tomorrow there could be an entirely different algorithm, and that throws out almost all the customizations one may have done.”
The slowing of Moore’s Law will have a fundamental influence on the balance point. “There have been a number of bespoke silicon companies in the past that were successful for a short period of time, but then failed,” says Ansys’ Swinnen. “They had made some kind of advance, be it architectural or addressing a new market need, but then the general-purpose chips caught up. That is because there’s so much investment in them, and there’s so many people using them, there’s an entire army of people advancing, versus your company, just your team, that’s advancing your bespoke solution. Inevitably, sooner or later, they bypass you and the general-purpose hardware just gets better than the specific one. Right now, the pendulum has swung toward custom solutions being the winner.”
However, general-purpose processors do not automatically advance if companies don’t keep up with adoption of the latest nodes, and that leads to even more opportunities. “When adding accelerators to a general-purpose processor starts to break down, because you want to go faster or become more efficient, you start to create truly customized implementations,” says Siemens’ Klein. “That’s where high-level synthesis starts to become really interesting, because you’ve got that software-defined implementation as your starting point. We can take it through high-level synthesis (HLS) and build an accelerator that’s going to do that one specific thing. We could leave a bunch of registers to define its behavior, or we can just hard code everything. The less general that system is, the more specific it is, usually the higher performance and the greater efficiency that we’re going to take away from it. And it almost always is going to be able to beat a general-purpose accelerator or certainly a general-purpose processor in terms of both performance and efficiency.”
At the same time, IP has become massively configurable. “There used to be IP as the building blocks,” says Arteris’ Schirrmeister. “Since then, the industry has produced much larger and more complex IP that takes on the role of sub-systems, and that’s where scope comes in. We have seen Arm with what they call the compute sub-systems (CSS), which are an integration and then hardened. People care about the chip as a whole, and then the chip and the system context with all that software. Application specificity has become ubiquitous in the IP space. You either build hard cores, you use a configurable core, or you use high-level synthesis. All of them are, by definition, application-specific, and the configurability plays in there.”
Put in perspective, there is more than one way to build a device, and an increasing number of options for getting it done. “There’s a really large market for specialized computing around some algorithm,” says Klein. “IP for that is going to be both in the form of discrete chips, as well as IP that could be built into something. Ultimately, that has to become silicon. It’s got to be hardened to some degree. They can set some parameters and bake it into somebody’s design. Consider an Arm processor. I can configure how many CPUs I want, I can configure how big I want the caches, and then I can go bake that into a specific implementation. That’s going to be the thing that I build, and it’s going to be more targeted. It will have better efficiency and a better cost profile and a better power profile for the thing that I’m doing. Somebody else can take it and configure it a little bit differently. And to the degree that the IP works, that’s a great solution. But there will always be algorithms that don’t have a big enough market for IP to address. And that’s where you go in and do the extreme customization.”
Chiplets
Some have questioned if the emerging chiplet industry will reverse this trend. “We will continue to see systems composed of many hardware accelerator blocks, and advanced silicon integration technologies (i.e., 3D stacking and chiplets) will make that even easier,” says Mythic’s Fick. “There are many companies working on open standards for chiplets, enabling communication bandwidth and energy efficiency that is an order of magnitude greater than what can be built on a PCB. Perhaps soon, the advanced system-in-package will overtake the PCB as the way systems are designed.”
Chiplets are not likely to be highly configurable. “Configuration in the chiplet world might become just a function of switching off things you don’t need,” says Schirrmeister. “Configuration really means that you do not use certain things. You don’t get your money back for those items. It’s all basically applying math and predicting what your volumes are going to be. If it’s an incremental cost that has one more block on it to support another interface, or making the block the Ethernet block with time triggered stuff in it for automotive, that gives you an incremental effort of X. Now, you have to basically estimate whether it also gives you a multiple of that incremental effort as incremental profit. It works out this way because chips just become very configurable. Chiplets are just going in the direction or finding the balance of more generic usage so that you can apply them in more chiplet designs.”
The chiplet market is far from certain today. “The promise of chiplets is that you use only the function that you want from the supplier that you want, in the right node, at the right location,” says Expedera’s Karazuba. “The idea of specialization and chiplets are at arm’s length. They’re actually together, but chiplets have a long way to go. There’s still not that universal agreement of the different things around a chiplet that have to be in order to make the product truly mass market.”
While chiplets have been proven to work, nearly all of the chiplets in use today are proprietary. “To build a viable [commercial] chiplet company, you have to be going after a broad enough market, large enough from a dollar perspective, then you can make all the investment, have success and get everything back accordingly,” says Blue Cheetah’s Alon. “There’s a similar tension where people would like to build a general-purpose chiplet that can be used anywhere, by anyone. That is the plug-and-play discussion, but you could finish up with something that becomes so general-purpose, with so much overhead, that it’s just not attractive in any particular market. In the chiplet case, for technical reasons, it might not actually really work that way at all. You might try to build it for general purpose, and it turns out later that it doesn’t plug into particular sockets that are of interest.”
The economics of chiplet viability have not yet been defined. “The thing about chiplets is they can be small,” says Klein. “Being small means that we don’t need as big a market for them as we would for a very large chip. We can also build them on different technologies. We can have some that are on older technologies, where transistors are cheaper, and we can combine those with other chiplets that might be leading-edge nodes where we could have general-purpose CPUs or NPU accelerators. There’s a mix-and-match, and we can do chiplets smaller than we can general-purpose chips. We can do smaller runs of them. We can take that IP and customize it for a particular market vertical and create some chiplets for that, change the configuration a bit, and do another run for something else. There’s a level of customization that can be deployed and supported by the market that’s a little bit more than we’ve seen in full-size chips, where the entire thing has to be built into one package.
Conclusion
What it means for a design to be general-purpose or custom is changing. All designs will contain some of each. Some companies will develop novel architectures using general-purpose processors, and these will be better than a fully general-purpose solution. Others will create highly customized hardware for some functions that are known to be stable, and general purpose for things that are likely to change. One thing has never changed, however. A company is not likely to add more customization than necessary to satisfy the needs of the market they are targeting.
Samsung introduced several AI-powered features with the Galaxy S24. Samsung called the Galaxy S24 its first AI Phone. It is the first smartphone brand to go big with AI, seeing the AI boom. And Apple will soon follow Samsung, but its approach will be a bit different compared to its South Korean rival.
Apple could only bring on-device AI features to iPhones with iOS 18
According to a report from Mark Gurman (via 9To5Mac), AI features on iPhones will be powered entirely by a Large Language Model (LLM) developed by Apple, and all the AI processing will happen on-device. We can expect Apple to heavily market the privacy and speed benefits of using on-device AI processing. These AI features will reportedly debut with iOS 18 and will be showcased during WWDC 2024.
While on-device AI has privacy and speed benefits, it isn't as powerful as AI processing offered by dedicated servers in the cloud. However, it is possible that Apple will only introduce AI features that work well with on-device AI processing. For example, it could offer better auto-replies and Siri requests.
This differs from Samsung's approach of using a mix of on-device and cloud-powered AI features. Samsung uses a mix of its own LLM and Google's Gemini for AI processing. Users have to option to process AI data locally on the device with a simple toggle. As seen on the Galaxy S24 and older phones that have received One UI 6.1 with AI features, some AI features work fast, while others are slow, depending on the workload and complexity.
While Apple hasn't revealed any AI feature that could debut with iOS 18, it could bring better language translation, more reliable autocorrect while typing, and advanced image editing features. A few weeks ago, it was revealed that Apple was in talks with Google about using Gemini to power some AI features in iOS 18. However, it isn't clear if that deal has been agreed upon.
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
Digital characters are leveling up.
Non-playable characters often play a crucial role in video game storytelling, but since they’re usually designed with a fixed purpose, they can get repetitive and boring — especially in vast worlds where there are thousands.
Thanks in part to incredible advances in visual computing like ray tracing and DLSS, video games are more immersive and realistic than ever, making dry encounters with NPCs especially jarring.
Earlier this year, production microservices for the NVIDIA Avatar Cloud Engine launched, giving game developers and digital creators an ace up their sleeve when it comes to making lifelike NPCs. ACE microservices allow developers to integrate state-of-the-art generative AI models into digital avatars in games and applications. With ACE microservices, NPCs can dynamically interact and converse with players in-game and in real time.
Leading game developers, studios and startups are already incorporating ACE into their titles, bringing new levels of personality and engagement to NPCs and digital humans.
Bring Avatars to Life With NVIDIA ACE
The process of creating NPCs starts with providing them a backstory and purpose, which helps guide the narrative and ensures contextually relevant dialogue. Then, ACE subcomponents work together to build avatar interactivity and enhance responsiveness.
NPCs tap up to four AI models to hear, process, generate dialogue and respond.
The player’s voice first goes into NVIDIA Riva, a technology that builds fully customizable, real-time conversational AI pipelines and turns chatbots into engaging and expressive assistants using GPU-accelerated multilingual speech and translation microservices.
With ACE, Riva’s automatic speech recognition (ASR) feature processes what was said and uses AI to deliver a highly accurate transcription in real time. Explore a Riva-powered demo of speech-to-text in a dozen languages.
The transcription then goes into an LLM — such as Google’s Gemma, Meta’s Llama 2 or Mistral — and taps Riva’s neural machine translation to generate a natural language text response. Next, Riva’s Text-to-Speech functionality generates an audio response.
Finally, NVIDIA Audio2Face (A2F) generates facial expressions that can be synced to dialogue in many languages. With the microservice, digital avatars can display dynamic, realistic emotions streamed live or baked in during post-processing.
The AI network automatically animates face, eyes, mouth, tongue and head motions to match the selected emotional range and level of intensity. And A2F can automatically infer emotion directly from an audio clip.
Each step happens in real time to ensure fluid dialogue between the player and the character. And the tools are customizable, giving developers the flexibility to build the types of characters they need for immersive storytelling or worldbuilding.
Born to Roll
At GDC and GTC, developers and platform partners showcased demos leveraging NVIDIA ACE microservices — from interactive NPCs in gaming to powerful digital human nurses.
Ubisoft is exploring new types of interactive gameplay with dynamic NPCs. NEO NPCs, the product of its latest research and development project, are designed to interact in real time with players, their environment and other characters, opening up new possibilities for dynamic and emergent storytelling.
The capabilities of these NEO NPCs were showcased through demos, each focused on different aspects of NPC behaviors, including environmental and contextual awareness; real-time reactions and animations; and conversation memory, collaboration and strategic decision-making. Combined, the demos spotlighted the technology’s potential to push the boundaries of game design and immersion.
Using Inworld AI technology, Ubisoft’s narrative team created two NEO NPCs, Bloom and Iron, each with their own background story, knowledge base and unique conversational style. Inworld technology also provided the NEO NPCs with intrinsic knowledge of their surroundings, as well as interactive responses powered by Inworld’s LLM. NVIDIA A2F provided facial animations and lip syncing for the two NPCs real time.
Inworld and NVIDIA set GDC abuzz with a new technology demo called Covert Protocol, which showcased NVIDIA ACE technologies and the Inworld Engine. In the demo, players controlled a private detective who completed objectives based on the outcome of conversations with NPCs on the scene. Covert Protocol unlocked social simulation game mechanics with AI-powered digital characters that acted as bearers of crucial information, presented challenges and catalyzed key narrative developments. This enhanced level of AI-driven interactivity and player agency is set to open up new possibilities for emergent, player-specific gameplay.
Built on Unreal Engine 5, Covert Protocol uses the Inworld Engine and NVIDIA ACE, including NVIDIA Riva ASR and A2F, to augment Inworld’s speech and animation pipelines.
In the latest version of the NVIDIA Kairos tech demo built in collaboration with Convai, which was shown at CES, Riva ASR and A2F were used to significantly improve NPC interactivity. Convai’s new framework allowed the NPCs to converse among themselves and gave them awareness of objects, enabling them to pick up and deliver items to desired areas. Furthermore, NPCs gained the ability to lead players to objectives and traverse worlds.
Digital Characters in the Real World
The technology used to create NPCs is also being used to animate avatars and digital humans. Going beyond gaming, task-specific generative AI is moving into healthcare, customer service and more.
NVIDIA collaborated with Hippocratic AI at GTC to extend its healthcare agent solution, showcasing the potential of a generative AI healthcare agent avatar. More work underway to develop a super-low-latency inference platform to power real-time use cases.
“Our digital assistants provide helpful, timely and accurate information to patients worldwide,” said Munjal Shah, cofounder and CEO of Hippocratic AI. “NVIDIA ACE technologies bring them to life with cutting-edge visuals and realistic animations that help better connect to patients.”
Internal testing of Hippocratic’s initial AI healthcare agents is focused on chronic care management, wellness coaching, health risk assessments, social determinants of health surveys, pre-operative outreach and post-discharge follow-up.
UneeQ is an autonomous digital human platform focused on AI-powered avatars for customer service and interactive applications. UneeQ integrated the NVIDIA A2F microservice into its platform and combined it with its Synanim ML synthetic animation technology to create highly realistic avatars for enhanced customer experiences and engagement.
“UneeQ combines NVIDIA animation AI with our own Synanim ML synthetic animation technology to deliver real-time digital human interactions that are emotionally responsive and deliver dynamic experiences powered by conversational AI,” said Danny Tomsett, founder and CEO at UneeQ.
AI in Gaming
ACE is one of the many NVIDIA AI technologies that bring games to the next level.
NVIDIA DLSS is a breakthrough graphics technology that uses AI to increase frame rates and improve image quality on GeForce RTX GPUs.
NVIDIA RTX Remix enables modders to easily capture game assets, automatically enhance materials with generative AI tools and quickly create stunning RTX remasters with full ray tracing and DLSS.
NVIDIA Freestyle, accessed through the new NVIDIA app beta, lets users personalize the visual aesthetics of more than 1,200 games through real-time post-processing filters, with features like RTX HDR, RTX Dynamic Vibrance and more.
The NVIDIA Broadcast app transforms any room into a home studio, giving livestream AI-enhanced voice and video tools, including noise and echo removal, virtual background and AI green screen, auto-frame, video noise removal and eye contact.
Experience the latest and greatest in AI-powered experiences with NVIDIA RTX PCs and workstations, and make sense of what’s new, and what’s next, with AI Decoded.
Get weekly updates directly in your inbox by subscribing to the AI Decoded newsletter.
Generative AI is capable of creating more realistic verbal and facial expressions for digital humans than ever before.
This week at GDC 2024, NVIDIA announced that leading AI application developers across a wide range of industries are using NVIDIA digital human technologies to create lifelike avatars for commercial applications and dynamic game characters. NVIDIA enables developers with state-of-the-art digital human technologies, including NVIDIA ACE for speech and animation, NVIDIA NeMo for language, and NVIDIA RTX for ray-traced rendering.
Developers showcased new digital human technology demos that used NVIDIA ACE microservices at GDC.
Embracing ACE: Partners Transforming Pixels Into Personalities
Top game and digital human developers are pioneering ways ACE and generative AI technologies can be used to transform interactions between players and NPCs in games and applications.
Demos Showcase New NVIDIA Digital Human Technologies
NVIDIA worked with developers Inworld AI and UneeQ on a series of new demos to display the potential of digital human technologies.
Inworld AI created Covert Protocol in partnership with NVIDIA, allowing players to become a skilled private detective, pushing the possibilities of non-playable character interactions. The demo taps into NVIDIA Riva automatic speech recognition (ASR) and NVIDIA Audio2Face microservices alongside the Inworld Engine.
The Inworld Engine brings together cognition, perception and behavior systems to create an immersive narrative along with the beautifully crafted RTX-rendered environments and art.
UneeQ is a digital human platform specialized in creating high-fidelity AI-powered 3D avatars for a range of enterprise applications. UneeQ’s digital humans power interactive experiences for brands enabling them to communicate with customers in real-time to give them confidence in their purchases. UneeQ integrated NVIDIA Audio2Face microservice into its platform and combined it with Synanim ML to create highly realistic avatars for a better customer experience and engagement.
New NVIDIA RTX Technologies for Dynamic Scenes
NVIDIA RTX revolutionized gaming several years ago by offering a collection of rendering technologies that enable real-time path tracing in games and applications.
The latest addition, Neural Radiance Cache (NRC), is an AI-driven RTX algorithm to handle indirect lighting in fully dynamic scenes, without the need to bake static lighting for geometry and materials beforehand.
Adding flexibility for developers, NVIDIA is introducing Spatial Hash Radiance Cache (SHaRC), which offers similar benefits as NRC but without using a neural network, and with compatibility on any DirectX or Vulkan ray tracing-capable GPU.
RTX. It’s On: More RTX and DLSS 3.5 Titles
There are now over 500 RTX games and applications that have revolutionized the ways people play and create with ray tracing, NVIDIA DLSS and AI-powered technologies. And gamers have a lot to look forward to with more full ray tracing and DLSS 3.5 titles coming.
Our latest innovation, NVIDIA DLSS 3.5, features new DLSS Ray Reconstruction technology. When activated, DLSS Ray Reconstruction replaces hand-tuned ray tracing denoisers with a new unified AI model that enhances ray tracing in supported games, elevating image quality to new heights.
Full Ray Tracing and DLSS 3.5 are coming to both Black Myth: Wukong and NARAKA: BLADEPOINT. And Portal with RTX is available now with RTX DLSS 3.5, enhancing its already beautiful full ray tracing. DLSS 3.5 With Ray Reconstruction will also be coming soon to the NVIDIA RTX Remix Open Beta, enabling modders to add RTX technologies like full ray tracing and DLSS 3.5 into classic games.
Star Wars Outlaws will launch with DLSS 3 and ray-traced effects. Ray tracing joins DLSS 3 in Diablo IV March 26. The First Berserker: Khazan will launch with DLSS 3. And Sengoku Destiny introduced support for DLSS 3 and is available now.
See our Partner Ecosystem at GDC
NVIDIA and our partners will showcase the latest in digital human technologies throughout the week of GDC. Here’s a quick snapshot:
Inworld AI (Booth P1615): Attendees will get the chance to try out Covert Protocol for themselves live at GDC.
Oracle Cloud Infrastructure (Booth S941): See Covert Protocol in action, and discover the “code assist” ability of Retrieval Augmented Generation (RAG). Register and join an exclusive networking event with Oracle and NVIDIA AI experts on March 21, open to women and allies in the gaming industry to build connections with leading voices in AI.
Dell Technologies and International Game Developer Association (Booth S1341): Playtest while building a game-ready asset on a workstation with large GPU memory. Speak to Sophie, an AI-powered assistant created by UneeQ and powered by NVIDIA ACE. Attendees can see the latest debugging and profiling tools for making ray-traced games in the latest Nsight Graphics ray tracing demo.
AWS: Developers can register and join NVIDIA, AWS, game studios, and technology partners as they discuss the game tech used to build, innovate, and maximize growth of today’s games at the AWS for Games Partner Showcase on March 20th.
Stop by these key sessions:
Transforming Gameplay with AI NPCs: This session featuring Nathan Yu, director of product at Inworld AI, Rajiv Gandhi, master principal cloud architect at Oracle Cloud and Yasmina Benkhoui, generative AI strategic partnerships lead at NVIDIA, will showcase successful examples of developers using AI NPCs to drive core game loops and mechanics that keep players engaged and immersed. Attendees will gain a deeper understanding of the potential of AI NPCs to create new and immersive experiences for players.
Alan Wake 2: A Deep Dive into Path Tracing Technology: This session will take a deep dive into the path tracing and NVIDIA DLSS Ray Reconstruction technologies implemented in Remedy Entertainment’s Alan Wake 2. Developers can discover how these cutting-edge techniques can enhance the visual experience of games.
Download our show guide to keep this summary on hand while at the show.
Get Started
Developers can start their journey on NVIDIA ACE by applying for our early access program to get in-development AI models.
If you want to explore available models, evaluate and access NVIDIA NIM, a set of easy-to-use microservices designed to accelerate the deployment of generative AI, for RIVA ASR and Audio2Face on ai.nvidia.com today.
RTXGI’s NRC and SHaRC algorithms are also available now as an experimental branch.
In the commercial sector, companies are now wrangling LLMs to build product copilots, automate tedious work, create personal assistants, and more, says Austin Henley, a former Microsoft employee who conducted a series of interviews with people developing LLM-powered copilots. “Every business is trying to use it for virtually every use case that they can imagine,” Henley says.
“The only real trend may be no trend. What’s best for any given model, dataset, and prompting strategy is likely to be specific to the particular combination at hand.” —Rick Battle & Teja Gollapudi, VMware
To do so, they’ve enlisted the help of prompt engineers professionally.
However, new research suggests that prompt engineering is best done by the model itself, and not by a human engineer. This has cast doubt on prompt engineering’s future—and increased suspicions that a fair portion of prompt-engineering jobs may be a passing fad, at least as the field is currently imagined.
Autotuned prompts are successful and strange
Rick Battle and Teja Gollapudi at California-based cloud computing company VMware were perplexed by how finicky and unpredictable LLM performance was in response to weird prompting techniques. For example, people have found that asking models to explain its reasoning step-by-step—a technique called chain-of-thought—improved their performance on a range of math and logic questions. Even weirder, Battle found that giving a model positive prompts, such as “this will be fun” or “you are as smart as chatGPT,” sometimes improved performance.
Battle and Gollapudi decided to systematically test how different prompt-engineering strategies impact an LLM’s ability to solve grade-school math questions. They tested three different open-source language models with 60 different prompt combinations each. What they found was a surprising lack of consistency. Even chain-of-thought prompting sometimes helped and other times hurt performance. “The only real trend may be no trend,” they write. “What’s best for any given model, dataset, and prompting strategy is likely to be specific to the particular combination at hand.”
According to one research team, no human should manually optimize prompts ever again.
There is an alternative to the trial-and-error-style prompt engineering that yielded such inconsistent results: Ask the language model to devise its own optimal prompt. Recently, new tools have been developed to automate this process. Given a few examples and a quantitative success metric, these tools will iteratively find the optimal phrase to feed into the LLM. Battle and his collaborators found that in almost every case, this automatically generated prompt did better than the best prompt found through trial-and-error. And, the process was much faster, a couple of hours rather than several days of searching.
The optimal prompts the algorithm spit out were so bizarre, no human is likely to have ever come up with them. “I literally could not believe some of the stuff that it generated,” Battle says. In one instance, the prompt was just an extended Star Trek reference: “Command, we need you to plot a course through this turbulence and locate the source of the anomaly. Use all available data and your expertise to guide us through this challenging situation.” Apparently, thinking it was Captain Kirk helped this particular LLM do better on grade-school math questions.
Battle says that optimizing the prompts algorithmically fundamentally makes sense given what language models really are—models. “A lot of people anthropomorphize these things because they ‘speak English.’ No, they don’t,” Battle says. “It doesn’t speak English. It does a lot of math.”
In fact, in light of his team’s results, Battle says no human should manually optimize prompts ever again.
“You’re just sitting there trying to figure out what special magic combination of words will give you the best possible performance for your task,” Battle says, “But that’s where hopefully this research will come in and say ‘don’t bother.’ Just develop a scoring metric so that the system itself can tell whether one prompt is better than another, and then just let the model optimize itself.”
Autotuned prompts make pictures prettier, too
Image-generation algorithms can benefit from automatically generated prompts as well. Recently, a team at Intel labs, led by Vasudev Lal, set out on a similar quest to optimize prompts for the image-generation model Stable Diffusion. “It seems more like a bug of LLMs and diffusion models, not a feature, that you have to do this expert prompt engineering,” Lal says. “So, we wanted to see if we can automate this kind of prompt engineering.”
“Now we have this full machinery, the full loop that’s completed with this reinforcement learning.… This is why we are able to outperform human prompt engineering.” —Vasudev Lal, Intel Labs
Lal’s team created a tool called NeuroPrompts that takes a simple input prompt, such as “boy on a horse,” and automatically enhances it to produce a better picture. To do this, they started with a range of prompts generated by human prompt-engineering experts. They then trained a language model to transform simple prompts into these expert-level prompts. On top of that, they used reinforcement learning to optimize these prompts to create more aesthetically pleasing images, as rated by yet another machine-learning model, PickScore, a recently developed image-evaluation tool.
NeuroPrompts is a generative AI auto prompt tuner that transforms simple prompts into more detailed and visually stunning StableDiffusion results—as in this case, an image generated by a generic prompt [left] versus its equivalent NeuroPrompt-generated image.Intel Labs/Stable Diffusion
Here too, the automatically generated prompts did better than the expert-human prompts they used as a starting point, at least according to the PickScore metric. Lal found this unsurprising. “Humans will only do it with trial and error,” Lal says. “But now we have this full machinery, the full loop that’s completed with this reinforcement learning.… This is why we are able to outperform human prompt engineering.”
Since aesthetic quality is infamously subjective, Lal and his team wanted to give the user some control over how the prompt was optimized. In their tool, the user can specify the original prompt (say, “boy on a horse”) as well as an artist to emulate, a style, a format, and other modifiers.
Lal believes that as generative AI models evolve, be it image generators or large language models, the weird quirks of prompt dependence should go away. “I think it’s important that these kinds of optimizations are investigated and then ultimately, they’re really incorporated into the base model itself so that you don’t really need a complicated prompt-engineering step.”
Prompt engineering will live on, by some name
Even if autotuning prompts becomes the industry norm, prompt-engineering jobs in some form are not going away, says Tim Cramer, senior vice president of software engineering at Red Hat. Adapting generative AI for industry needs is a complicated, multistage endeavor that will continue requiring humans in the loop for the foreseeable future.
“Maybe we’re calling them prompt engineers today. But I think the nature of that interaction will just keep on changing as AI models also keep changing.” —Vasudev Lal, Intel Labs
“I think there are going to be prompt engineers for quite some time, and data scientists,” Cramer says. “It’s not just asking questions of the LLM and making sure that the answer looks good. But there’s a raft of things that prompt engineers really need to be able to do.”
“It’s very easy to make a prototype,” Henley says. “It’s very hard to production-ize it.” Prompt engineering seems like a big piece of the puzzle when you’re building a prototype, Henley says, but many other considerations come into play when you’re making a commercial-grade product.
Challenges of making a commercial product include ensuring reliability—for example, failing gracefully when the model goes offline; adapting the model’s output to the appropriate format, since many use cases require outputs other than text; testing to make sure the AI assistant won’t do something harmful in even a small number of cases; and ensuring safety, privacy, and compliance. Testing and compliance are particularly difficult, Henley says, as traditional software-development testing strategies are maladapted for nondeterministic LLMs.
To fulfill these myriad tasks, many large companies are heralding a new job title: Large Language Model Operations, or LLMOps, which includes prompt engineering in its life cycle but also entails all the other tasks needed to deploy the product. Henley says LLMOps’ predecessors, machine learning operations (MLOps) engineers, are best positioned to take on these jobs.
Whether the job titles will be “prompt engineer,” “LLMOps engineer,” or something new entirely, the nature of the job will continue evolving quickly. “Maybe we’re calling them prompt engineers today,” Lal says, “But I think the nature of that interaction will just keep on changing as AI models also keep changing.”
“I don’t know if we’re going to combine it with another sort of job category or job role,” Cramer says, “But I don’t think that these things are going to be going away anytime soon. And the landscape is just too crazy right now. Everything’s changing so much. We’re not going to figure it all out in a few months.”
Henley says that, to some extent in this early phase of the field, the only overriding rule seems to be the absence of rules. “It’s kind of the Wild, Wild West for this right now.” he says.
With the 2018 launch of RTX technologies and the first consumer GPU built for AI — GeForce RTX — NVIDIA accelerated the shift to AI computing. Since then, AI on RTX PCs and workstations has grown into a thriving ecosystem with more than 100 million users and 500 AI applications.
Generative AI is now ushering in a new wave of capabilities from PC to cloud. And NVIDIA’s rich history and expertise in AI is helping ensure all users have the performance to handle a wide range of AI features.
Users at home and in the office are already taking advantage of AI on RTX with productivity- and entertainment-enhancing software. Gamers feel the benefits of AI on GeForce RTX GPUs with higher frame rates at stunning resolutions in their favorite titles. Creators can focus on creativity, instead of watching spinning wheels or repeating mundane tasks. And developers can streamline workflows using generative AI for prototyping and to automate debugging.
The field of AI is moving fast. As research advances, AI will tackle more complex tasks. And the demanding performance needs will be handled by RTX.
What Is AI?
In its most fundamental form, artificial intelligence is a smarter type of computing. It’s the capability of a computer program or a machine to think, learn and take actions without being explicitly coded with commands to do so, or a user having to control each command.
AI can be thought of as the ability for a device to perform tasks autonomously, by ingesting and analyzing enormous amounts of data, then recognizing patterns in that data — often referred to as being “trained.”
AI development is always oriented around developing systems that perform tasks that would otherwise require human intelligence, and often significant levels of input, to complete — only at speeds beyond any individual’s or group’s capabilities. For this reason, AI is broadly seen as both disruptive and highly transformational.
A key benefit of AI systems is the ability to learn from experiences or patterns inside data, adjusting conclusions on their own when fed new inputs or data. This self-learning allows AI systems to accomplish a stunning variety of tasks, including image recognition, speech recognition, language translation, medical diagnostics, car navigation, image and video enhancement, and hundreds of other use cases.
The next step in the evolution of AI is content generation — referred to as generative AI. It enables users to quickly create new content, and iterate on it, based on a variety of inputs, which can include text, images, sounds, animation, 3D models or other types of data. It then generates new content in the same or a new form.
Popular language applications, like the cloud-based ChatGPT, allow users to generate long-form copy based on a short text request. Image generators like Stable Diffusion turn descriptive text inputs into the desired image. New applications are turning text into video and 2D images into 3D renderings.
GeForce RTX AI PCs and NVIDIA RTX Workstations
AI PCs are computers with dedicated hardware designed to help AI run faster. It’s the difference between sitting around waiting for a 3D image to load, and seeing it update instantaneously with an AI denoiser.
On RTX GPUs, these specialized AI accelerators are called Tensor Cores. And they dramatically speed up AI performance across the most demanding applications for work and play.
One way that AI performance is measured is in teraops, or trillion operations per second (TOPS). Similar to an engine’s horsepower rating, TOPS can give users a sense of a PC’s AI performance with a single metric. The current generation of GeForce RTX GPUs offers performance options that range from roughly 200 AI TOPS all the way to over 1,300 TOPS, with many options across laptops and desktops in between. Professionals get even higher AI performance with the NVIDIA RTX 6000 Ada Generation GPU.
To put this in perspective, the current generation of AI PCs without GPUs range from 10 to 45 TOPS.
More and more types of AI applications will require the benefits of having a PC capable of performing certain AI tasks locally — meaning on the device rather than running in the cloud. Benefits of running on an AI PC include that computing is always available, even without an internet connection; systems offer low latency for high responsiveness; and increased privacy so that users don’t have to upload sensitive materials to an online database before it becomes usable by an AI.
AI for Everyone
RTX GPUs bring more than just performance. They introduce capabilities only possible with RTX technology. Many of these AI features are accessible — and impactful — to millions, regardless of the individual’s skill level.
From AI upscaling to improved video conferencing to intelligent, personalizable chatbots, there are tools to benefit all types of users.
RTX Video uses AI to upscale streaming video and display it in HDR. Bringing lower-resolution video in standard dynamic range to vivid, up to 4K high-resolution high dynamic range. RTX users can enjoy the feature with one-time, one-click enablement on nearly any video streamed in a Chrome or Edge browser.
NVIDIA Broadcast, a free app for RTX users with a straightforward user interface, has a host of AI features that improve video conferencing and livestreaming. It removes unwanted background sounds like clicky keyboards, vacuum cleaners and screaming children with Noise and Echo Removal. It can replace or blur backgrounds with better edge detection using Virtual Background. It smooths low-quality camera images with Video Noise Removal. And it can stay centered on the screen with eyes looking at the camera no matter where the user moves, using Auto Frame and Eye Contact.
The tech demo, originally released in January, will get an update with Google’s Gemma soon.
Users can easily connect local files on a PC to a supported large language model simply by dropping files into a single folder and pointing the demo to the location. It enables queries for quick, contextually relevant answers.
Since Chat with RTX runs locally on Windows with GeForce RTX PCs and NVIDIA RTX workstations, results are fast — and the user’s data stays on the device. Rather than relying on cloud-based services, Chat with RTX lets users process sensitive data on a local PC without the need to share it with a third party or have an internet connection.
AI for Gamers
Over the past six years, game performance has seen the greatest leaps with AI acceleration. Gamers have been turning NVIDIA DLSS on since 2019, boosting frame rates and improving image quality. It’s a technique that uses AI to generate pixels in video games automatically. With ongoing improvements, it now increases frame rates by up to 4x.
And with the introduction of Ray Reconstruction in the latest version, DLSS 3.5, visual quality is further enhanced in some of the world’s top titles, setting a new standard for visually richer and more immersive gameplay.
There are now over 500 games and applications that have revolutionized the ways people play and create with ray tracing, DLSS and AI-powered technologies.
Beyond frames, AI is set to improve the way gamers interact with characters and remaster classic games.
NVIDIA ACE microservices — including generative AI-powered speech and animation models — are enabling developers to add intelligent, dynamic digital avatars to games. Demonstrated at CES, ACE won multiple awards for its ability to bring game characters to life as a glimpse into the future of PC gaming.
NVIDIA RTX Remix, a platform for modders to create stunning RTX remasters of classic games, delivers generative AI tools that can transform basic textures from classic games into modern, 4K-resolution, physically based rendering materials. Several projects have already been released or are in the works, including Half-Life 2 RTX and Portal with RTX.
AI for Creators
AI is unlocking creative potential by reducing or automating tedious tasks, freeing up time for pure creativity. These features run fastest or solely on PCs with NVIDIA RTX or GeForce RTX GPUs.
Adobe Premiere Pro’s Enhance Speech tool is accelerated by RTX, using AI to remove unwanted noise and improve the quality of dialogue clips so they sound professionally recorded. It’s up to 4.5x faster on RTX vs. Mac. Another Premiere feature, Auto Reframe, uses GPU acceleration to identify and track the most relevant elements in a video and intelligently reframes video content for different aspect ratios.
Another time-saving AI feature for video editors is DaVinci Resolve’s Magic Mask. Previously, if editors needed to adjust the color/brightness of a subject in one shot or remove an unwanted object, they’d have to use a combination of rotoscoping techniques or basic power windows and masks to isolate the subject from the background.
Magic Mask has completely changed that workflow. With it, simply draw a line over the subject and the AI will process for a moment before revealing the selection. And GeForce RTX laptops can run the feature 2.5x faster than the fastest non-RTX laptops.
This is just a sample of the ways that AI is increasing the speed of creativity. There are now more than 125 AI applications accelerated by RTX.
AI for Developers
AI is enhancing the way developers build software applications through scalable environments, hardware and software optimizations, and new APIs.
NVIDIA AI Workbench helps developers quickly create, test and customize pretrained generative AI models and LLMs using PC-class performance and memory footprint. It’s a unified, easy-to-use toolkit that can scale from running locally on RTX PCs to virtually any data center, public cloud or NVIDIA DGX Cloud.
After building AI models for PC use cases, developers can optimize them using NVIDIA TensorRT — the software that helps developers take full advantage of the Tensor Cores in RTX GPUs.
TensorRT acceleration is now available in text-based applications with TensorRT-LLM for Windows. The open-source library increases LLM performance and includes pre-optimized checkpoints for popular models, including Google’s Gemma, Meta Llama 2, Mistral and Microsoft Phi-2.
Developers also have access to a TensorRT-LLM wrapper for the OpenAI Chat API. With just one line of code change, continue.dev — an open-source autopilot for VS Code and JetBrains that taps into an LLM — can use TensorRT-LLM locally on an RTX PC for fast, local LLM inference using this popular tool.
Every week, we’ll demystify AI by making the technology more accessible, and we’ll showcase new hardware, software, tools and accelerations for RTX AI PC users.
The iPhone moment of AI is here, and it’s just the beginning. Welcome to AI Decoded.
Get weekly updates directly in your inbox by subscribing to the AI Decoded newsletter.
Imagine being at a packed Chainsmokers concert. Up front, the music is infectious and loud, and it’s hard to hear friends. But farther away from the band, it’s possible to talk with them. Or picture gathering with family members across the globe for vibrant holiday celebrations, or a bridal party meeting up in a virtual fitting room and laughing as they make funny faces while trying on life-like dresses.
These are all things people can do in real life, and will soon be able to do on Roblox. In this blog post, we’ll be diving into our vision of enabling everyone to connect with others, communicate, and express themselves however they like with:
Personalized and Expressive Avatars
Connecting with Friends
Immersive Communication
Last month at RDC, we unveiled innovative products and technologies to accelerate this future. Today, we’re sharing what our company vision will look and feel like as we reimagine the way people come together and advance our goal of connecting a billion people with optimism and civility.
Personalized and Expressive Avatars
We know a person’s avatar is an essential part of how they wish to be seen, and we want Roblox to be the go-to digital platform for connecting with others as one’s authentic self. Indeed, research shows that the vast majority of Gen Z Roblox users have customized avatars, and half of them change their avatar’s clothing at least once a week.
We’re excited by how our next generation of avatars will make everyone’s time on Roblox richer and more fun, no matter who they are or want to be with. So think about how great it could feel one day to hang out with friends who can be and look like anyone they want—a jetpack-wearing ninja, an emo princess, or just like they do in real life. Or to collaborate at a company meeting where colleagues can see each other’s expressions and body movements.
Self-Expression
The way people appear on Roblox is a vital part of their identity. Building the perfect avatar requires that it be easy to choose realistic-looking customizations—skin tone, face and body shape, or body size—that expresses someone’s ethnic, cultural, and/or gender identity.
An exciting new technology that will aid that in the future is generative AI. It will let anyone create an avatar body or hairstyle that embodies who they want to be, whether it’s photo-realistic or picked from numerous art styles—fantasy, cartoony, absurd, and so on. Then, they can augment their avatar with clothing, tattoos, and jewelry. So if dad wants to sport his signature mohawk and leather jacket in Roblox, he’ll be able to do just that. And if his daughter wants to be Cleopatra in the 1920s, so can she.
Avatars that build emotional connection
In real life, people read others’ feelings by their visible emotions and body language: if they’re smiling broadly and standing up straight and loose, they’re happy. That should be the same on Roblox.
This is complex work, but we’re already incorporating these dynamics with things like animating avatars with movement. Over time, we’ll accelerate these lifelike avatar features with authentic blink rates and gestures.
Ultimately, our users’ avatars should be extensions of who they are and aspire to be. That’s why it’s essential for everyone to be able to create an avatar they love. At Roblox, avatars aren’t the end goal—they’re the foundation.
Connecting With Friends
When people are with friends on Roblox, they’re happier and they return more often to explore more experiences together. Research shows that being with real-life friends is the top reason people come to Roblox and that 35% of new users find at least one real life friend within a week of joining.
We want to foster a rich, interconnected network of relationships on Roblox, which is why we’re building tools, such as Contact Importer, which launched last year, to make it easy to connect with existing friends—or make new ones, like the millions of new friendships formed on Roblox every day.
In addition, in the next month, we’ll let users customize friends’ names—including using real names for people 17 and older—to make them easier to identify. So envision two long-lost friends who reconnect on Roblox. They decide to call each other by the childhood nicknames neither has forgotten rather than Roblox names neither can remember, which will make it even easier to instantly find each other.
Another aspect of enhancing people’s ability to connect on Roblox is sharing memorable moments with others. So imagine that one day, the two old friends go to a virtual theme park with their families. After an hour of laughing, they take a screenshot capturing their joyful expressions on a digital roller coaster. We’re building a way for people to share that roller coaster image—or other videos or 3D moments—to contacts outside of Roblox, and in the process, potentially discover that some of them are already on the platform.
Immersive Communication
When people interact on Roblox, we want them to feel like they’re together. In the coming months and years, we’ll introduce immersive communications features that people will use every day to connect. For example, a K-pop band could put on a private concert for some contest winners. As the singers play their biggest hit, the fans get more and more excited, which pumps up the band and together, the fans and the singers belt out the lyrics. That’s a kind of real-world connection that will soon be possible because they’ll all feel like they’re in the same place.
At RDC, we announced Roblox Connect, a way for friends to call each other as their avatars, is coming soon. When we roll out Connect, they’ll be able to come together in a shared immersive space and sit at a bonfire, on the beach, or by a campfire, conveying their feelings and emotions with lively facial expressions and real body language.
Eventually, we’ll allow users to initiate video calls on Roblox with people in different experiences. So imagine being able to call a friend and almost look over their shoulder as they model a new outfit from Fashion Klossette or take on a series of bad guys in Jailbreak.
We’ll be providing developers with the technologies that make Connect possible and we’re excited to see the endless collection of communication experiences they’ll build for our community.
Becoming a Daily Utility
Roblox is a platform for communication and connection. This post reflects our vision for immersive communication which, alongside safety and civility, a virtual economy, and being available everywhere to everyone, is at the heart of what Roblox is about. We’re still in the early days of implementing our vision, but we’re excited by the ways it will eventually help people feel like they’re together with the people they care most about.
The AI revolution returned to where it started this week, putting powerful new tools into the hands of gamers and content creators.
Generative AI models that will bring lifelike characters to games and applications and new GPUs for gamers and creators were among the highlights of a news-packed address Monday ahead of this week’s CES trade show in Las Vegas.
“Today, NVIDIA is at the center of the latest technology transformation: generative AI,” said Jeff Fisher, senior vice president for GeForce at NVIDIA, who was joined by leaders across the company to introduce products and partnerships across gaming, content creation, and robotics.
A Launching Pad for Generative AI
As AI shifts into the mainstream, Fisher said NVIDIA’s RTX GPUs, with more than 100 million units shipped, are pivotal in the burgeoning field of generative AI, exemplified by innovations like ChatGPT and Stable Diffusion.
And with our new Chat with RTX playground, releasing later this month, enthusiasts can connect an RTX-accelerated LLM to their own data, from locally stored documents to YouTube videos, using retrieval-augmented generation, or RAG, a technique for enhancing the accuracy and reliability of generative AI models.
Fisher also introduced TensorRT acceleration for Stable Diffusion XL and SDXL Turbo in the popular Automatic1111 text-to-image app, providing up to a 60% boost in performance.
NVIDIA Avatar Cloud Engine Microservices Debut With Generative AI Models for Digital Avatars
NVIDIA ACE is a technology platform that brings digital avatars to life with generative AI. ACE AI models are designed to run in the cloud or locally on the PC.
In an ACE demo featuring Convai’s new technologies, NVIDIA’s Senior Product Manager Seth Schneider showed how it works.
First, a player’s voice input is passed to NVIDIA’s automatic speech recognition model, which translates speech to text. Then, the text is put into an LLM to generate the character’s response.
After that, the text response is vocalized using a text-to-speech model, which is passed to an animation model to create a realistic lip sync. Finally, the dynamic character is rendered into the game scene.
At CES, NVIDIA is announcing ACE Production Microservices for NVIDIA Audio2Face and NVIDIA Riva Automatic Speech Recognition. Available now, each model can be incorporated by developers individually into their pipelines.
NVIDIA is also announcing game and interactive avatar developers are pioneering ways ACE and generative AI technologies can be used to transform interactions between players and non-playable characters in games and applications. Developers embracing ACE include Convai, Charisma.AI, Inworld, miHoYo, NetEase Games, Ourpalm, Tencent, Ubisoft and UneeQ.
Getty Images Releases Generative AI by iStock and AI Image Generation Tools Powered by NVIDIA Picasso
Generative AI empowers designers and marketers to create concept imagery, social media content and more. Today, iStock by Getty Images is releasing a genAI service built on NVIDIA Picasso, an AI foundry for visual design, Fisher announced.
The iStock service allows anyone to create 4K imagery from text using an AI model trained on Getty Images’ extensive catalog of licensed, commercially safe creative content. New editing application programming interfaces that give customers powerful control over their generated images are also coming soon.
The generative AI service is available today at istock.com, with advanced editing features releasing via API.
NVIDIA Introduces GeForce RTX 40 SUPER Series
Fisher announced a new series of GeForce RTX 40 SUPER GPUs with more gaming and generative AI performance.
Fisher said that the GeForce RTX 4080 SUPER can power fully ray-traced games at 4K. It’s 1.4x faster than the RTX 3080 Ti without frame gen in the most graphically intensive games. With 836 AI TOPS, NVIDIA DLSS Frame Generation delivers an extra performance boost, making the RTX 4080 SUPER twice as fast as an RTX 3080 Ti.
Creators can generate video with Stable Video Diffusion 1.5x faster and images with Stable Diffusion XL 1.7x faster. The RTX 4080 SUPER features more cores and faster memory, giving it a performance edge at a great new price of $999. It will be available starting Jan. 31.
Next up is the RTX 4070 Ti SUPER. NVIDIA has added more cores and increased the frame buffer to 16GB and the memory bus to 256 bits. It’s 1.6x faster than a 3070 Ti and 2.5x faster with DLSS 3, Fisher said. The RTX 4070 Ti SUPER will be available starting Jan. 24 for $799.
Fisher also introduced the RTX 4070 SUPER. NVIDIA has added 20% more cores, making it faster than the RTX 3090 while using a fraction of the power. And with DLSS 3, it’s 1.5x faster in the most demanding games. It will be available for $599 starting Jan. 17.
NVIDIA RTX Remix Open Beta Launches This Month
There are over 10 billion game mods downloaded each year. With RTX Remix, modders can remaster classic games with full ray tracing, DLSS, NVIDIA Reflex and generative AI texture tools that transform low-resolution textures into 4K, physically accurate materials. The RTX Remix app will be released in open beta on Jan. 22.
Check out this new Half-Life 2 RTX gameplay trailer:
Twitch and NVIDIA to Release Multi-Encode Livestreaming
Twitch is one of the most popular platforms for content creators, with over 7 million streamers going live each month to 35 million daily viewers. Fisher explained that these viewers are on all kinds of devices and internet services.
Yet many Twitch streamers are limited to broadcasting at a single resolution and quality level. As a result, they must broadcast at lower quality to reach more viewers.
To address this, Twitch, OBS and NVIDIA announced Enhanced Broadcasting, supported by all RTX GPUs. This new feature allows streamers to transmit up to three concurrent streams to Twitch at different resolutions and quality so each viewer gets the optimal experience.
Beta signups start today and will go live later this month. Twitch will also experiment with 4K and AV1 on the GeForce RTX 40 Series GPUs to deliver even better quality and higher resolution streaming.
‘New Wave’ of AI-Ready RTX Laptops
RTX is the fastest-growing laptop platform, having grown 5x in the last four years. Over 50 million devices are enjoyed by gamers and creators across the globe.
More’s coming. Fisher announced “a new wave” of RTX laptops launching from every major manufacturer. “Thanks to powerful RT and Tensor Cores, every RTX laptop is AI-ready for the best gaming and AI experiences,” Fisher said.
With an installed base of 100 million GPUs and 500 RTX games and apps, GeForce RTX is the world’s largest platform for gamers, creators and, now, generative AI.
Activision and Blizzard Games Embrace RTX
More than 500 games and apps now take advantage of NVIDIA RTX technology, NVIDIA’s Senior Consumer Marketing Manager Kristina Bartz said, including Alan Wake 2, which won three awards at this year’s Game Awards.
NVIDIA Consumer Marketing Manager Kristina Bartz spoke about how NVIDIA technologies are being integrated into popular games.
It’s a list that keeps growing with 14 new RTX titles announced at CES.
Horizon Forbidden West, the critically acclaimed sequel to Horizon Zero Dawn, will come to PC early this year with the Burning Shores expansion, accelerated by DLSS 3.
Pax Dei is a social sandbox massively multiplayer online game inspired by the legends of the medieval era. Developed by Mainframe Industries with veterans from CCP Games, Blizzard and Remedy Entertainment, Pax Dei will launch in early access on PC with AI-accelerated DLSS 3 this spring.
Last summer, Diablo IV launched with DLSS 3 and immediately became Blizzard’s fastest-selling game. RTX ray tracing will now be coming to Diablo IV in March.
More than 500 games and apps now take advantage of NVIDIA RTX technology, with more coming.
Day Passes and G-SYNC Technology Coming to GeForce NOW
NVIDIA’s partnership with Activision also extends to the cloud with GeForce NOW, Bartz said. In November, NVIDIA welcomed the first Activation and Blizzard game, Call of Duty: Modern Warfare 3. Diablo IV and Overwatch 2 are coming soon.
GeForce NOW will get Day Pass membership options starting in February. Priority and Ultimate Day Passes will give gamers a full day of gaming with the fastest access to servers, with all the same benefits as members, including NVIDIA DLSS 3.5 and NVIDIA Reflex for Ultimate Day Pass purchasers.
NVIDIA also announced Cloud G-SYNC technology is coming to GeForce NOW, which varies the display refresh rate to match the frame rate on G-SYNC monitors, giving members the smoothest, tear-free gaming experience from the cloud.
Generative AI Powers Smarter Robots With NVIDIA Isaac
NVIDIA Vice President of Robotics and Edge Computing Deepu Talla addressed the intersection of AI and robotics.
Closing out the special address, NVIDIA Vice President of Robotics and Edge Computing Deepu Talla shared how the infusion of generative AI into robotics is speeding up the ability to bring robots from proof of concept to real-world deployment.
Talla gave a peek into the growing use of generative AI in the NVIDIA robotics ecosystem, where robotics innovators like Boston Dynamics and Collaborative Robots are changing the landscape of human-robot interaction.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.
To enhance the gaming experience, studios and developers spend tremendous effort creating photorealistic, immersive in-game environments.
But non-playable characters (NPCs) often get left behind. Many behave in ways that lack depth and realism, making their interactions repetitive and forgettable.
Inworld AI is changing the game by using generative AI to drive NPC behaviors that are dynamic and responsive to player actions. The Mountain View, Calif.-based startup’s Character Engine, which can be used with any character design, is helping studios and developers enhance gameplay and improve player engagement.
Register for NVIDIA GTC, which takes place March 17-21, to hear how leading companies like Inworld AI are using the latest innovations in AI and graphics. And join us at Game Developers Conference (GDC) to discover how the latest generative AI and RTX technologies are accelerating game development.
Elevate Gaming Experiences: Achievement Unlocked
The Inworld team aims to develop AI-powered NPCs that can learn, adapt and build relationships with players while delivering high-quality performance and maintaining in-game immersion.
To make it easier for developers to integrate AI-based NPCs into their games, Inworld built Character Engine, which uses generative AI running on NVIDIA technology to create immersive, interactive characters. It’s built to be production-ready, scalable and optimized for real-time experiences.
The Character Engine comprises three layers: Character Brain, Contextual Mesh and Real-Time AI.
The layer also enables AI-based NPCs to learn and adapt, navigate relationships and perform motivated actions. For example, users can create triggers using the “Goals and Action” feature to program NPCs to behave in a certain way in response to a given player input.
Contextual Mesh allows developers to set parameters for content and safety mechanisms, custom knowledge and narrative controls. Game developers can use the “Relationships” feature to create emergent narratives, such that an ally can turn into an enemy or vice versa based on how players treat an NPC.
One big challenge developers face when using generative AI is keeping NPCs in-world and on-message. Inworld’s Contextual Mesh layer helps overcome this hurdle by rendering characters within the logic and fantasy of their worlds, effectively avoiding the hallucinations that commonly appear when using large language models (LLMs).
The Real-Time AI layer ensures optimal performance and scalability for real-time experiences.
Inworld used the open-source NVIDIA Triton Inference Server software to standardize other non-generative machine learning model deployments required to power Character Brain features, such as emotions. The startup also plans to use the open-source NVIDIA TensorRT-LLM library to optimize inference performance. Both NVIDIA Triton Inference Server and TensorRT-LLM are available with the NVIDIA AI Enterprise software platform, which provides security, stability and support for production AI.
Inworld also used NVIDIA A100 GPUs within Slurm-managed bare-metal machines for its production training pipelines. Similar machines wrapped in Kubernetes help manage character interactions during gameplay. This setup delivers real-time generative AI at the lowest possible cost.
“We chose to use NVIDIA A100 GPUs because they provided the best, most cost-efficient option for our machine learning workloads compared to other solutions,” said Igor Poletaev, vice president of AI at Inworld.
“Our customers and partners are looking to find novel and innovative ways to drive player engagement metrics by integrating AI NPC functionalities into their gameplay,” said Poletaev. “There’s no way to achieve real-time performance without hardware accelerators, which is why we required GPUs to be integrated into our backend architecture from the very beginning.”
Inworld’s generative AI-powered NPCs have enabled dynamic, evergreen gaming experiences that keep players coming back. Developers and gamers alike have reported enhanced player engagement, satisfaction and retention.
Inworld has powered AI-based NPC experiences from Niantic, LG UPlus, Alpine Electronics and more. One open-world virtual reality game using the Inworld Character Engine saw a 5% increase in playtime, while a detective-themed indie game garnered over $300,000 in free publicity after some of the most popular Twitch streamers discovered it.
The 2024 International Solid State Circuits Conference was held this week in San Francisco. Submissions were up 40% and contributed to the quality of the papers accepted and the presentations given at the conference.
The mood about the future of semiconductor technology was decidedly upbeat with predictions of a $1 trillion industry by 2030 and many expecting that the soaring demand for AI enabling silicon to speed up that timeline.
Dr. Kevin Zhang, Senior Vice President, Business Development and Overseas Operations Office for TSMC, showed the following slide during his opening plenary talk.
Fig. 1: TSMC semiconductor industry revenue forecast to 2030.
The 2030 semiconductor market by platform was broken out as 40% HPC, 30% Mobile, 15% Automotive, 10% IoT and 5% “Others”.
Dr. Zhang also outlined several new generations of transistor technologies, showing that there’s still more improvements to come.
TSMC’s N2 will be going into production next year and is transitioning TSMC from finFET to nanosheet, and the figure still shows a next step of stacking NMOS and PMOS transistor to get increased density in silicon.
Lip Bu Tan, Chairman, Walden International, also backed up the $1T prediction.
Fig. 3: Walden semiconductor market drivers.
Mr. Tan also referenced an MIT paper from September 2023 titled, “AI Models are devouring energy. Tools to reduce consumption are here, if data centers will adopt.” It states that huge, popular models like ChatGPT signal a trend of large-scale AI, boosting some forecasts that predict data centers could draw up to 21% of the world’s electricity supply by 2030. That’s an astounding over 1/5 of the world’s electricity.
There also appears to be a virtuous cycle of using this new AI technology to create even better computing machines.
Fig. 4: Walden design productivity improvements.
The figure above shows a history of order of magnitude improvements in design productivity to help engineers make use of all the transistors that have been scaling with Moore’s Law. There are also advances in packaging and companies like AMD, Intel and Meta all presented papers of implementations using fine pitch hybrid bonding to build systems with even higher densities. Mr. Tan presented data attributed to market.us predicting that AI will drive a CAGR of 42% in 3D-IC chiplet growth between 2023 and 2033.
Jonah Alben, Senior Vice President of GPU Engineering for NVIDIA, further backed up the claim of generative AI enabling better productivity and better designs. Figure 5 below shows how NVIDIA was able to use their PrefixRL AI system to produce better designs along a whole design curve and stated that this technology was used to design nearly 13,000 circuits in NVIDIA’s Hopper.
There was also a Tuesday night panel session on generative AI for design, and the fairly recent Si Catalyst panel discussion held last November was covered here. This is definitely an area that is growing and gaining momentum.
Fig. 5: NVIDIA example improvements from PrefixRL.
To wrap up, let’s look at some work that’s been reporting best in class performance metrics in terms of efficiency, IBM’s NorthPole. Researchers at IBM published and presented the paper 11.4: “IBM NorthPole: An Architecture for Neural Network Inference with a 12nm Chip.” Last September after HotChips, the article IBM’s Energy-Efficient NorthPole AI Unit included many of the industry competition comparisons, so those won’t be included again here, but we will look at some of the other results that were reported.
The brain-inspired research team has been working for over a decade at IBM. In fact, in October 2014 their earlier spike-based research was reported in the article Brain-Inspired Power. Like many so-called asynchronous approaches, the information and communication overhead for the spikes meant that the energy efficiency didn’t pan out and the team re-thought how to best incorporate brain model concepts into silicon, hence the brain-inspired, silicon optimized tag line.
NorthPole makes use of what IBM refers to as near memory compute. As pointed out and shown here, the memory is tightly integrated with the compute blocks, which reduces how far data must travel and saves energy. As shown in figure 6, for ResNet-50 NorthPole is most efficient running at approximately 680mV and approximately 200MHz (in 12nm FinFET technology). This yields an energy metric of ~1100 frames/joule (equivalently fps/W).
Fig. 6: NorthPole voltage/frequency scaling results for ResNet-50.
To optimize the communication for NorthPole, IBM created 4 NoCs:
Partial Sum NoC (PSNoC) communicates within a layer – for spatial computing
Activation NoC (ANoC) reorganizes activations between layers
Model NoC (MNoC) delivers weights during layer execution
Instruction NoC (INoC) delivers the program for each layer prior to layer start
The Instruction and Model NoCs share the same architecture. The protocols are full-custom and optimized for 0 stall cycles and are 2-D meshes. The PSNoC is communicating across short distances and could be said to be NoC-ish. The ANoC is again its own custom protocol implementation. Along with using software to compile executables that are fully deterministic and perform no speculation and optimize the bit width of computations between 8-, 4- and 2-bit calculations, this all leads to a very efficient implementation.
Fig. 7: NorthPole exploded view of PCIe assembly.
IBM had a demonstration of NorthPole running at ISSCC. The unit is well designed for server use and the team is looking forward to the possibility of implementing NorthPole in a more advanced technology node. My thanks to John Arthur from IBM for taking some time to discuss NorthPole.
Jon Herlocker, co-founder and CEO of Tignis, sat down with Semiconductor Engineering to talk about how AI in advanced process control reduces equipment variability and corrects for process drift. What follows are excerpts of that conversation.
SE: How is AI being used in semiconductor manufacturing and what will the impact be?
Herlocker: AI is going to create a completely different factory. The real change is going to happen when AI gets integrated, from the design side all the way through the manufacturing side. We are just starting to see the beginnings of this integration right now. One of the biggest challenges in the semiconductor industry is it can take years from the time an engineer designs a new device to that device reaching high-volume production. Machine learning is going to cut that to half, or even a quarter. The AI technology that Tignis offers today accelerates that very last step — high-volume manufacturing. Our customers want to know how to tune their tools so that every time they process a wafer the process is in control. Traditionally, device makers get the hardware that meets their specifications from the equipment manufacturer, and then the fab team gets their process recipes working. Depending on the size of the fab, they try to physically replicate that process in a ‘copy exact’ manner, which can take a lot of time and effort. But now device makers can use machine learning (ML) models to autonomously compensate for the differences in equipment variation to produce the exact same outcome, but with significantly less effort by process engineers and equipment technicians.
SE: How is this typically done?
Herlocker: A classic APC system on the floor today might model three input parameters using linear models. But if you need to model 20 or 30 parameters, these linear models don’t work very well. With AI controllers and non-linear models, customers can ingest all of their rich sensor data that shows what is happening in the chamber, and optimally modulate the recipe settings to ensure that the outcome is on-target. AI tools such as our PAICe Maker solution can control any complex process with a greater degree of precision.
SE: So, the adjustments AI process control software makes is to tweak inputs to provide consistent outputs?
Herlocker: Yes, I preach this all the time. By letting AI automate the tasks that were traditionally very manual and time-consuming, engineers and technicians in the fab can remove a lot of the manual precision tasks they needed to do to control their equipment, significantly reducing module operating costs. AI algorithms also can help identify integration issues — interacting effects between tools that are causing variability. We look at process control from two angles. Software can autonomously control the tool by modulating the recipe parameters in response to sensor readings and metrology. But your autonomous control cannot control the process if your equipment is not doing what it is supposed to do, so we developed a separate AI learning platform that ensures equipment is performing to specification. It brings together all the different data silos across the fab – the FDC trace data, metrology data, test data, equipment data, and maintenance data. The aggregation of all that data is critical to understanding the causes of a variation in equipment. This is where ML algorithms can automatically sift through massive amount of data to help process engineers and data scientists determine what parameters are most influencing their process outcomes.
SE: Which process tools benefit the most from AI modeling of advanced process control?
Herlocker: We see the most interest in thin film deposition tools. The physics involved in plasma etching and plasma-enhanced CVD are non-linear processes. That is why you can get much better control with ML modeling. You also can model how the process and equipment evolves over time. For example, every time you run a batch through the PECVD chamber you get some amount of material accumulation on the chamber walls, and that changes the physics and chemistry of the process. AI can build a predictive model of that chamber. In addition to reacting to what it sees in the chamber, it also can predict what the chamber is going to look like for the next run, and now the ML model can tweak the input parameters before you even see the feedback.
SE: How do engineers react to the idea that the AI will be shifting the tool recipe?
Herlocker: That is a good question. Depending on the customer, they have different levels of comfort about how frequently things should change, and how much human oversight there needs to be for that change. We have seen everything from, ‘Just make a recommendation and one of our engineers will decide whether or not to accept that recommendation,’ to adjusting the recipe once a day, to autonomously adjusting for every run. The whole idea behind these adjustments is for variability reduction and drift management, and customers weigh the targeted results versus the perceived risk of taking a novel approach.
SE: Does this involve building confidence in AI-based approaches?
Herlocker: Absolutely, and our systems have a large number of fail-safes, and some limits are hard-coded. We have people with PhDs in chemical engineering and material science who have operated these tools for years. These experts understand the physics of what is happening in these tools, and they have the practical experience to know what level of change can be expected or not.
SE: How much of your modeling is physics-based?
Herlocker: In the beginning, all of our modeling was physics-based, because we were working with equipment makers on their next-generation tools. But now we are also bringing our technology to device makers, where we can also deliver a lot of value by squeezing the most juice out of a data-driven approach. The main challenge with physics models is they are usually IP-protected. When we work with equipment makers, they typically pay us to build those physics-based models so they cannot be shared with other customers.
SE: So are your target customers the toolmakers or the fabs?
Herlocker: They are both our target customers. Most of our sales and marketing efforts are focused on device makers with legacy fabs. In most cases, the fab manager has us engage with their team members to do an assessment. Frequently, that team includes a cross section of automation, process, and equipment teams. The automation team is most interested in reducing the time to detect some sort of deviation that is going to cause yield loss, scrap, or tool downtime. The process and equipment engineers are interested in reducing variability or controlling drift, which also increases chamber life.
For example, let’s consider a PECVD tool. As I mentioned, every time you run the process, byproducts such as polymer materials build up on the chamber walls. You want a thickness of x in your deposition, but you are getting a slightly different wafer thickness uniformity due to drift of that chamber because of plasma confinement changes. Eventually, you must shut down the tool, wet clean the chamber, replace the preventive maintenance kit parts, and send them through the cleaning loop (i.e., to the cleaning vendor shop). Then you need to season the chamber and bring it back online. By controlling the process better, the PECVD team does not have to vent the chamber as often to clean parts. Just a 5% increase in chamber life can be quite significant from a maintenance cost reduction perspective (e.g., parts spend, refurb spend, cleaning spend, etc.). Reducing variability has a similarly large impact, particularly if it is a bottleneck tool, because then that reduction directly contributes to higher or more stable yields via more ‘sweet spot’ processing time, and sometimes better wafer throughput due to the longer chamber lifetime. The ROI story is more nuanced on non-bottleneck tools because they don’t modulate fab revenue, but the ROI there is still there. It is just more about chamber life stability.
SE: Where does this go next?
Herlocker: We also are working with OEMs on next-generation toolsets. Using AI/ML as the core of process control enables equipment makers to control processes that are impossible to implement with existing control strategies and software. For example, imagine on each process step there are a million different parameters that you can control. Further imagine that changing any one parameter has a global effect on all the other parameters, and only by co-varying all the million parameters in just the right way will you get the ideal outcome. And to further complicate things, toss in run-to-run variance, so that the right solution continues to change over time. And then there is the need to do this more than 200 times per hour to support high-volume manufacturing. AI/ML enables this kind of process control, which in turn will enable a step function increase in the ability to produce more complex devices more reliably.
SE: What additional changes do you see from AI-based algorithms?
Herlocker: Machine learning will dramatically improve the agility and productivity of the facility broadly. For example, process engineers will spend less time chasing issues and have more time to implement continuous improvement. Maintenance engineers will have time to do more preventive maintenance. Agility and resiliency — the ability to rapidly adjust to or maintain operations, despite disturbances in the factory or market — will increase. If you look at ML combined with upcoming generative AI capabilities, within a year or two we are going to have agents that effectively will understand many aspects of how equipment or a process works. These agents will make good engineers great, and enable better capture, aggregation, and transfer of manufacturing knowledge. In fact, we have some early examples of this running in our labs. These ML agents capture and ingest knowledge very quickly. So when it comes to implementing the vision of smart factories, machine learning automation will have a massive impact on manufacturing in the future.
The Galaxy S24, Galaxy S24+, and Galaxy S24 Ultra were the first Samsung devices to run One UI 6.1, featuring several new AI features and additional tweaks. Samsung announced last month that it will release the One UI 6.1 update to older devices before the end of the first half of this year. The company has now offered a more accurate timeline for the release of the One UI 6.1 update.
One UI 6.1 update is coming to some high-end phones in March 2024
Samsung has announced that it will start rolling out the One UI 6.1 update to the Galaxy S23, Galaxy S23+, Galaxy S23 Ultra, Galaxy S23 FE, Galaxy Z Flip 5, Galaxy Z Fold 5, and the Galaxy Tab S9 series at the end of March 2024. This update will bring several Galaxy AI features seen on the Galaxy S24 series to older high-end phones through a hybrid approach. Some AI features will work on-device, while others need an active internet connection.
By the end of 2024, Samsung aims to bring Galaxy AI features to over 100 million Galaxy smartphones, tablets, and wearables.
List of AI features coming with One UI 6.1 to older Galaxy devices
The One UI 6.1 update will bring Browsing Assist, Chat Assist, Circle to Search with Google, Generative Edit, Instant Slow-Mo, Interpreter, Live Translate, Note Assist, and Transcript Assist to the devices mentioned above.
The Browsing Assist feature allows users to create summaries of articles or webpages, and it only works with the Samsung Internet web browser. It helps users read content and understand it faster.
The Chat Assist feature will enable users to adjust the tone of their language while messaging. Users can get grammar and tone improvements, and the feature works with messaging apps in 13 different languages. With the Circle to Search with Google feature, users can circle anything on the screen to get more information about it online.
With Generative Edit, users can select and erase unwanted objects from images. They can also choose and realign/reposition objects to make an image look like a great shot. They can also adjust images with bad angles and fill the remaining space with matching content created by Generative AI. The Instant Slow-Mo feature lets users turn any regular video into a slow-motion video. It uses AI to generate intermediate frames to double the frames in a video.
The Interpreter mode allows people to converse with others who don't speak their language. This mode opens in split-screen mode on conventional phones, foldable phones, and tablets. Words spoken by a Galaxy device user are transcribed and converted to any other chosen language. Translated text is then converted to voice so the other person can hear it in their language. Similarly, the Live Translate feature translates languages in real time during voice calls. It also works in supported messaging apps, including WhatsApp.
You can check out all these features in our in-depth video below.
The Note Assist feature helps users summarize the text in a note inside Samsung Notes. Summaries can even be used with certain text formatting templates. The Transcript Assist feature works with Samsung's stock Voice Recorder app. It transcribes voice in the recording to text and can even tag up to ten speakers so that users can understand things better. All that transcription can then be summarized, which is great for classes and meetings.
In our video below, you can watch other non-AI features introduced with the One UI 6.1 update. Some of those features, such as wallpaper support on Always On Display, will not be coming to any Galaxy smartphone or tablet launched before the Galaxy S24.
As for other Galaxy phones, many will receive One UI 6.1, but the AI features are currently expected to be exclusive to Samsung's flagship devices launched in 2023 and beyond.
TM Roh, President and Head of the Mobile eXperience Business at Samsung Electronics, said, “Our goal with Galaxy AI is not only to pioneer a new era of mobile AI but also to empower users by making AI more accessible. This is only the beginning of Galaxy AI, as we plan to bring the experience to over 100 million Galaxy users within 2024 and continue to innovate ways to harness the unlimited possibilities of mobile AI.“
Generative AI continues to be the hot topic in the digital world – and beyond. A previous blog post noted that this has led to people finally asking the important question whether copyright is fit for the digital world. As far as AI is concerned, there are two sides to the question. The first is whether generative AI systems can be trained on copyright materials without the need for licensing. That has naturally dominated discussions, because many see an opportunity to impose what is effectively a copyright tax on generative AI. The other question is whether the output of generative AI systems can be copyrighted. As another Walled Post explained, the current situation is unclear. In the US, purely AI-generated art cannot currently be copyrighted and forms part of the public domain, but it may be possible to copyright works that include significant human input.
Given the current interest in generative AI, it’s no surprise that there are lots of pundits out there pontificating on what it all means. I find Christopher S. Penn’s thoughts on the subject to be consistently insightful and worth reading, unlike those of many other commentators. Even better, his newsletter and blog are free. His most recent newsletter will be of particular interest to Walled Culture readers, and has a bold statement concerning AI and copyright:
We should unequivocally ensure machine-made content can never be protected under intellectual property laws, or else we’re going to destroy the entire creative economy.
His newsletter includes a short harmonized tune generated using AI. Penn points out that it is trivially easy to automate the process of varying that tune and its harmony using AI, in a way that scales to billions of harmonized tunes covering a large proportion of all possible songs:
If my billion songs are now copyrighted, then every musician who composes a song from today forward has to check that their composition isn’t in my catalog of a billion variations – and if it is (which, mathematically, it probably will be), they have to pay me.
Moreover, allowing copyright in this way would result in a computing arms race. Those with the deepest pockets could use more powerful hardware and software to produce more AI tunes faster than anyone else, allowing them to copyright them first:
That wipes out the music industry. That wipes out musical creativity, because suddenly there is no incentive to create and publish original music for commercial purposes, including making a living as a musician. You know you’ll just end up in a copyright lawsuit sooner or later with a company that had better technology than you.
That’s one good reason for not allowing music – or images, videos or text – generated by AI to be granted copyright. As Penn writes, doing so would just create a huge industry whose only purpose is generating a library of works that is used for suing human creators for alleged copyright infringement. The bullying and waste already caused by the similar patent troll industry shows why this is not something we would want. Here’s another reason why copyright for AI creations is a bad idea according to Penn:
If machine works remain non-copyrightable, there’s a strong disincentive for companies like Disney to use machine-made works. They won’t be able to enforce copyright on them, which makes those works less valuable than human-led works that they can fully protect. If machine works suddenly have the same copyright status as human-led works, then a corporation like Disney has much greater incentive to replace human creators as quickly as possible with machines, because the machines will be able to scale their created works to levels only limited by compute power.
This chimes with something that I have argued before: that generative AI could help to make human-generated art more valuable. The value of human creativity will be further enhanced if companies are unable to claim copyright in AI-generated works. It’s an important line of thinking, because it emphasizes that it is not in the interest of artists to allow copyright on AI-generated works, whatever Big Copyright might have them believe.
Generative AI is today’s buzziest form of artificial intelligence, and it’s what powers chatbots like ChatGPT, Ernie, LLaMA, Claude, and Command—as well as image generators like DALL-E 2, Stable Diffusion, Adobe Firefly, and Midjourney. Generative AI is the branch of AI that enables machines to learn patterns from vast datasets and then to autonomously produce new content based on those patterns. Although generative AI is fairly new, there are already many examples of models that can produce text, images, videos, and audio.
Many “foundation models” have been trained on enough data to be competent in a wide variety of tasks. For example, a large language model can generate essays, computer code, recipes, protein structures, jokes, medical diagnostic advice, and much more. It can also theoretically generate instructions for building a bomb or creating a bioweapon, though safeguards are supposed to prevent such types of misuse.
What’s the difference between AI, machine learning, and generative AI?
Artificial intelligence (AI) refers to a wide variety of computational approaches to mimicking human intelligence.
Machine learning (ML) is a subset of AI; it focuses on algorithms that enable systems to learn from data and improve their performance. Before generative AI came along, most ML models learned from datasets to perform tasks such as classification or prediction. Generative AI is a specialized type of ML involving models that perform the task of generating new content, venturing into the realm of creativity.
What architectures do generative AI models use?
Generative models are built using a variety of neural network architectures—essentially the design and structure that defines how the model is organized and how information flows through it. Some of the most well-known architectures are
variational autoencoders (VAEs), generative adversarial networks (GANs), and transformers. It’s the transformer architecture, first shown in this seminal 2017 paper from Google, that powers today’s large language models. However, the transformer architecture is less suited for other types of generative AI, such as image and audio generation.
Autoencoders learn efficient representations of data through an
encoder-decoder framework. The encoder compresses input data into a lower-dimensional space, known as the latent (or embedding) space, that preserves the most essential aspects of the data. A decoder can then use this compressed representation to reconstruct the original data. Once an autoencoder has been trained in this way, it can use novel inputs to generate what it considers the appropriate outputs. These models are often deployed in image-generation tools and have also found use in drug discovery, where they can be used to generate new molecules with desired properties.
With generative adversarial networks (GANs), the training involves a
generator and a discriminator that can be considered adversaries. The generator strives to create realistic data, while the discriminator aims to distinguish between those generated outputs and real “ground truth” outputs. Every time the discriminator catches a generated output, the generator uses that feedback to try to improve the quality of its outputs. But the discriminator also receives feedback on its performance. This adversarial interplay results in the refinement of both components, leading to the generation of increasingly authentic-seeming content. GANs are best known for creating deepfakes but can also be used for more benign forms of image generation and many other applications.
The transformer is arguably the reigning champion of generative AI architectures for its ubiquity in today’s powerful large language models (LLMs). Its strength lies in its attention mechanism, which enables the model to focus on different parts of an input sequence while making predictions. In the case of language models, the input consists of strings of words that make up sentences, and the transformer predicts what words will come next (we’ll get into the details below). In addition, transformers can process all the elements of a sequence in parallel rather than marching through it from beginning to end, as earlier types of models did; this
parallelization makes training faster and more efficient. When developers added vast datasets of text for transformer models to learn from, today’s remarkable chatbots emerged.
How do large language models work?
A transformer-based LLM is trained by giving it a vast dataset of text to learn from. The attention mechanism comes into play as it processes sentences and looks for patterns. By looking at all the words in a sentence at once, it gradually begins to understand which words are most commonly found together and which words are most important to the meaning of the sentence. It learns these things by trying to predict the next word in a sentence and comparing its guess to the ground truth. Its errors act as feedback signals that cause the model to adjust the weights it assigns to various words before it tries again.
These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
To explain the training process in slightly more technical terms, the text in the training data is broken down into elements called
tokens, which are words or pieces of words—but for simplicity’s sake, let’s say all tokens are words. As the model goes through the sentences in its training data and learns the relationships between tokens, it creates a list of numbers, called a vector, for each one. All the numbers in the vector represent various aspects of the word: its semantic meanings, its relationship to other words, its frequency of use, and so on. Similar words, like elegant and fancy, will have similar vectors and will also be near each other in the vector space. These vectors are called word embeddings. The parameters of an LLM include the weights associated with all the word embeddings and the attention mechanism. GPT-4, the OpenAI model that’s considered the current champion, is rumored to have more than 1 trillion parameters.
Given enough data and training time, the LLM begins to understand the subtleties of language. While much of the training involves looking at text sentence by sentence, the attention mechanism also captures relationships between words throughout a longer text sequence of many paragraphs. Once an LLM is trained and is ready for use, the attention mechanism is still in play. When the model is generating text in response to a prompt, it’s using its predictive powers to decide what the next word should be. When generating longer pieces of text, it predicts the next word in the context of all the words it has written so far; this function increases the coherence and continuity of its writing.
Why do large language models hallucinate?
You may have heard that LLMs sometimes “hallucinate.” That’s a polite way to say they make stuff up very convincingly. A model sometimes generates text that fits the context and is grammatically correct, yet the material is erroneous or nonsensical. This bad habit stems from LLMs training on vast troves of data drawn from the Internet, plenty of which is not factually accurate. Since the model is simply trying to predict the next word in a sequence based on what it has seen, it may generate plausible-sounding text that has no grounding in reality.
Why is generative AI controversial?
One source of controversy for generative AI is the provenance of its training data. Most AI companies that train large models to generate text, images, video, and audio have
not been transparent about the content of their training datasets. Various leaks and experiments have revealed that those datasets include copyrighted material such as books, newspaper articles, and movies. A number of lawsuits are underway to determine whether use of copyrighted material for training AI systems constitutes fair use, or whether the AI companies need to pay the copyright holders for use of their material.
On a related note, many people are concerned that the widespread use of generative AI will take jobs away from creative humans who make art, music, written works, and so forth. People are also concerned that it could take jobs from humans who do a wide range of white-collar jobs, including translators, paralegals, customer-service representatives, and journalists. There have already been a few
troubling layoffs, but it’s hard to say yet whether generative AI will be reliable enough for large-scale enterprise applications. (See above about hallucinations.)
Finally, there’s the danger that generative AI will be used to make bad stuff. And there are of course many categories of bad stuff it could theoretically be used for. Generative AI can be used for personalized scams and phishing attacks: For example, using “voice cloning,” scammers can
copy the voice of a specific person and call the person’s family with a plea for help (and money). All formats of generative AI—text, audio, image, and video—can be used to generate misinformation by creating plausible-seeming representations of things that never happened, which is a particularly worrying possibility when it comes to elections. (Meanwhile, as IEEE Spectrum reported this week, the U.S. Federal Communications Commission has responded by outlawing AI-generated robocalls.) Image- and video-generating tools can be used to produce nonconsensual pornography, although the tools made by mainstream companies disallow such use. And chatbots can theoretically walk a would-be terrorist through the steps of making a bomb, nerve gas, and a host of other horrors. Although the big LLMs have safeguards to prevent such misuse, some hackers delight in circumventing those safeguards. What’s more, “uncensored” versions of open-source LLMs are out there.
Despite such potential problems, many people think that generative AI can also make people more productive and could be used as a tool to enable entirely new forms of creativity. We’ll likely see both disasters and creative flowerings and plenty else that we don’t expect. But knowing the basics of how these models work is increasingly crucial for tech-savvy people today. Because no matter how sophisticated these systems grow, it’s the humans’ job to keep them running, make the next ones better, and with any luck, help people out too.
A culture war in AI is emerging between those who believe that the development of models should be restricted or unrestricted by default. In 2024, that clash is spilling over into the law, and it has major implications for the future of open innovation in AI.
Today, the AI technologies under most scrutiny are generative AI models that have learned how to read, write, draw, animate, and speak, and that can be used to power tools like ChatGPT. Intertwined with the wider debate over AI regulation is a heated and ongoing disagreement over the risk of open models—models that can be used, modified, and shared by other developers—and the wisdom of releasing their distinctive settings, or “weights,” to the public.
Since the launch of powerful open models like the Llama, Falcon, Mistral, and Stable Diffusion families, critics have pressed to keep other such genies in the bottle. “Open source software and open data can be an extraordinary resource for furthering science,” wrote two U.S. senators to Meta (creator of Llama), but “centralized AI models can be more effectively updated and controlled to prevent and respond to abuse.” Think tanks and closed-source firms have called for AI development to be regulated like nuclear research, with restrictions on who can develop the most powerful AI models. Last month, one commentator argued in IEEE Spectrum that “open-source AI is uniquely dangerous,” echoing calls for the registration and licensing of AI models.
The debate is surfacing in recent efforts to regulate AI. First, the European Union has just finalized its AI Act to govern the development and deployment of AI systems. Among its most hotly contested provisions was whether to apply these rules to “free and open-source” models. Second, following President Biden’s executive order on AI, the U.S. government has begun to compel reports from the developers of certain AI models, and will soon launch a public inquiry into the regulation of “widely-available” AI models.
However our governments choose to regulate AI, we need to promote a diverse AI ecosystem: from large companies building proprietary superintelligence to everyday tinkerers experimenting with open technology. Open models are the bedrock for grassroots innovation in AI.
I serve as head of public policy for Stability AI (makers of Stable Diffusion), where I work with a small team of passionate researchers who share media and language models that are freely used by millions of everyday developers and creators around the world. My concern is that this grassroots ecosystem is uniquely vulnerable to mounting restrictions on who can develop and share models. Eventually, these regulations may lead to limits on fundamental research and collaboration in ways that erode this culture of open development, which made AI possible in the first place and helps make it safer.
Open models promote transparency and competition
Open models play a vital role in helping to drive transparency and competition in AI. Over the coming years, generative AI will support creative, analytic, and scientific applications that go far beyond today’s text and image generators; we’ll see such applications as personalized tutors, desktop healthcare assistants, and backyard film studios. These models will revolutionize essential services, reshape how we access information online, and transform our public and private institutions. In short, AI will become critical infrastructure.
As I have argued before the U.S. Congress and U.K. Parliament, the next wave of digital services should not rely solely on a few “black box” systems operated by a cluster of big tech firms. Today, our digital economy runs on opaque systems that feed us content, control our access to information, determine our exposure to advertising, and mediate our online interactions. We’re unable to inspect these systems or build competitive alternatives. If models—our AI building blocks—are owned by a handful of firms, we risk repeating what played out with the Internet.
We’ve seen what happens when critical digital infrastructure is controlled by just a few companies.
In this environment, open models play a vital role. If a model’s weights are released, researchers, developers, and authorities can “look under the hood” of these AI engines to understand their suitability and to mitigate their vulnerabilities before deploying them in real-world tools. Everyday developers and small businesses can adapt these open models to create new AI applications, tune safer AI models for specific tasks, train more representative AI models for diverse communities, or launch new AI ventures without spending tens of millions of dollars to build a model from scratch.
We know from experience that transparency and competition are the foundation for a thriving digital ecosystem. That’s why open-source software like Android powers most of the world’s smartphones, and why Linux can be found in data centers, nuclear submarines, and SpaceX rockets. Open-source software has contributed as much as US $8.8 trillion in value globally. Indeed, recent breakthroughs in AI were only possible because of open research like the transformer architecture, open code libraries like PyTorch, and open collaboration from researchers and developers around the world.
Regulations may stifle grassroots innovation
Fortunately, no government has ventured to abolish open models altogether. If anything, governments have resisted the most extreme calls to intervene. The White House declined to require premarket licenses for AI models in its executive order. And after a confrontation with its member state governments in December, the E.U. agreed to partially exempt open models from its AI Act. Meanwhile, Singapore is funding a US $52 million open-source development effort for Southeast Asia, and the UAE continues to bankroll some of the largest available open generative AI models. French President Macron has declared “on croit dans l’open-source”—we believe in open-source.
However, the E.U. and U.S. regulations could put the brakes on this culture of open development in AI. For the first time, these instruments establish a legal threshold beyond which models will be deemed “dual use” or “systemic risk” technologies. Those thresholds are based on a range of factors, including the computing power used to train the model. Models over the threshold will attract new regulatory controls, such as notifying authorities of test results and maintaining exhaustive research and development records, and they will lose E.U. exemptions for open-source development.
In one sense, these thresholds are a good faith effort to avoid overregulating AI. They focus regulatory attention on future models with unknown capabilities instead of restricting existing models. Few existing models will meet the current thresholds, and those that do first will be models from well-resourced firms that are equipped to meet the new obligations.
In another sense, however, this approach to regulation is troubling, and augurs a seismic shift in how we govern novel technology. Grassroots innovation may become collateral damage.
Regulations could hurt everyday developers
First, regulating “upstream” components like models could have a disproportionate chilling effect on research in “downstream” systems. Many of the restrictions for above-the-threshold models assume that developers are sophisticated firms with formal relationships to those who use their models. For example, the U.S. executive order requires developers to report on individuals who can access the model’s weights, and detail the steps taken to secure those weights. The E.U. legislation requires developers to conduct “state of the art” evaluations and systematically monitor for incidents involving their models.
For the first time, these instruments establish a legal threshold beyond which models will be deemed “dual use” or “systemic risk” technologies.
Yet the AI ecosystem is more than a handful of corporate labs. It also includes countless developers, researchers, and creators who can freely access, refine, and share open models. They can iterate on powerful “base” models to create safer, less biased, or more reliable “fine-tuned” models that they release back to the community.
If governments treat these everyday developers the same as the companies that first released the model, there will be problems. Developers operating from dorm rooms and dining tables won’t be able to comply with the premarket licensing and approval requirements that have been proposed in Congress, or the “one size fits all” evaluation, mitigation, and documentation requirements initially drafted by the European Parliament. And they would never contribute to model development—or any other kind of software development—if they thought a senator might hold them liable for how downstream actors use or abuse their research. Individuals releasing new and improved models on GitHub shouldn’t face the same compliance burden as OpenAI or Meta.
The thresholds for restrictions seem arbitrary
Second, the criteria underpinning these thresholds are unclear. Before we put up barriers around the development and distribution of a useful technology, governments should assess the initial risk of the technology, the residual risk after considering all available legal and technical mitigations, and the opportunity cost of getting it wrong.
Yet there is still no framework for determining whether these models actually pose a serious and unmitigated risk of catastrophic misuse, or for measuring the impact of these rules on AI innovation. The preliminary U.S. threshold—1026 floating point operations (FLOPs) in training computation—first appeared as a passing footnote in a research paper. The EU threshold of 1025 FLOPs is an order of magnitude more conservative, and didn’t appear at all until the final month of negotiation. We may cross that threshold in the foreseeable future. What’s more, both governments reserve the right to move these goalposts for any reason, potentially bringing into scope a massive number of smaller but increasingly powerful models, many of which can be run locally on laptops or smartphones.
Restrictions are based on speculative risks
Third, there is no consensus about precisely which risks justify these exceptional controls. Online safety, election disinformation, smart malware, and fraud are some of the most immediate and tangible risks posed by generative AI. Economic disruption is possible too. However, these risks are rarely invoked to justify premarket controls for other helpful software technologies with dual-use applications. Photoshop, Word, Facebook, Google Search, and WhatsApp have contributed to the proliferation of deepfakes, fake news, and phishing scams, but our first instinct isn’t to regulate their underlying C++ or Java libraries.
Instead, critics have focused on “existential risk” to make the case for regulating model development and distribution, citing the prospect of runaway agents or homebuilt weapons of mass destruction. However, as a recent paper from Stanford’s Institute for Human-Centered Artificial Intelligence (HAI) notes of these claims, “the weakness of evidence is striking.” If these arguments are to justify a radical departure from our conventional approach to regulating technology, the standard of proof should be higher than speculation.
We should regulate AI while preserving openness
There is no debate that AI should be regulated, and all actors—from model developers to application deployers—have a role to play in mitigating emerging risks. However, new rules must account for grassroots innovation in open models. Right now, well-intended efforts to regulate models run the risk of stifling open development. Taken to their extreme, these frameworks may limit access to foundational technology, saddle hobbyists with corporate obligations, or formally restrict the exchange of ideas and resources between everyday developers.
In many ways, models are regulated already, thanks to a complex patchwork of legal frameworks that governs the development and deployment of any technology. Where there are gaps in existing law—such as U.S. federal law governing abusive, fraudulent, or political deepfakes—they can and should be closed.
However, presumptive restrictions on model development should be the option of last resort. We should regulate for emerging risks while preserving the culture of open development that made these breakthroughs possible in the first place, and that drives transparency and competition in AI.
Generative AI continues to be the hot topic in the digital world – and beyond. A previous blog post noted that this has led to people finally asking the important question whether copyright is fit for the digital world. As far as AI is concerned, there are two sides to the question. The first is whether generative AI systems can be trained on copyright materials without the need for licensing. That has naturally dominated discussions, because many see an opportunity to impose what is effectively a copyright tax on generative AI. The other question is whether the output of generative AI systems can be copyrighted. As another Walled Post explained, the current situation is unclear. In the US, purely AI-generated art cannot currently be copyrighted and forms part of the public domain, but it may be possible to copyright works that include significant human input.
Given the current interest in generative AI, it’s no surprise that there are lots of pundits out there pontificating on what it all means. I find Christopher S. Penn’s thoughts on the subject to be consistently insightful and worth reading, unlike those of many other commentators. Even better, his newsletter and blog are free. His most recent newsletter will be of particular interest to Walled Culture readers, and has a bold statement concerning AI and copyright:
We should unequivocally ensure machine-made content can never be protected under intellectual property laws, or else we’re going to destroy the entire creative economy.
His newsletter includes a short harmonized tune generated using AI. Penn points out that it is trivially easy to automate the process of varying that tune and its harmony using AI, in a way that scales to billions of harmonized tunes covering a large proportion of all possible songs:
If my billion songs are now copyrighted, then every musician who composes a song from today forward has to check that their composition isn’t in my catalog of a billion variations – and if it is (which, mathematically, it probably will be), they have to pay me.
Moreover, allowing copyright in this way would result in a computing arms race. Those with the deepest pockets could use more powerful hardware and software to produce more AI tunes faster than anyone else, allowing them to copyright them first:
That wipes out the music industry. That wipes out musical creativity, because suddenly there is no incentive to create and publish original music for commercial purposes, including making a living as a musician. You know you’ll just end up in a copyright lawsuit sooner or later with a company that had better technology than you.
That’s one good reason for not allowing music – or images, videos or text – generated by AI to be granted copyright. As Penn writes, doing so would just create a huge industry whose only purpose is generating a library of works that is used for suing human creators for alleged copyright infringement. The bullying and waste already caused by the similar patent troll industry shows why this is not something we would want. Here’s another reason why copyright for AI creations is a bad idea according to Penn:
If machine works remain non-copyrightable, there’s a strong disincentive for companies like Disney to use machine-made works. They won’t be able to enforce copyright on them, which makes those works less valuable than human-led works that they can fully protect. If machine works suddenly have the same copyright status as human-led works, then a corporation like Disney has much greater incentive to replace human creators as quickly as possible with machines, because the machines will be able to scale their created works to levels only limited by compute power.
This chimes with something that I have argued before: that generative AI could help to make human-generated art more valuable. The value of human creativity will be further enhanced if companies are unable to claim copyright in AI-generated works. It’s an important line of thinking, because it emphasizes that it is not in the interest of artists to allow copyright on AI-generated works, whatever Big Copyright might have them believe.




 Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.
Renée DiResta has been tracking online misinformation for many years as the technical research manager at Stanford’s Internet Observatory.









 Andrea J. Goldsmith
Andrea J. Goldsmith  Juraj Čorba
Juraj Čorba Samuel Naffziger
Samuel Naffziger







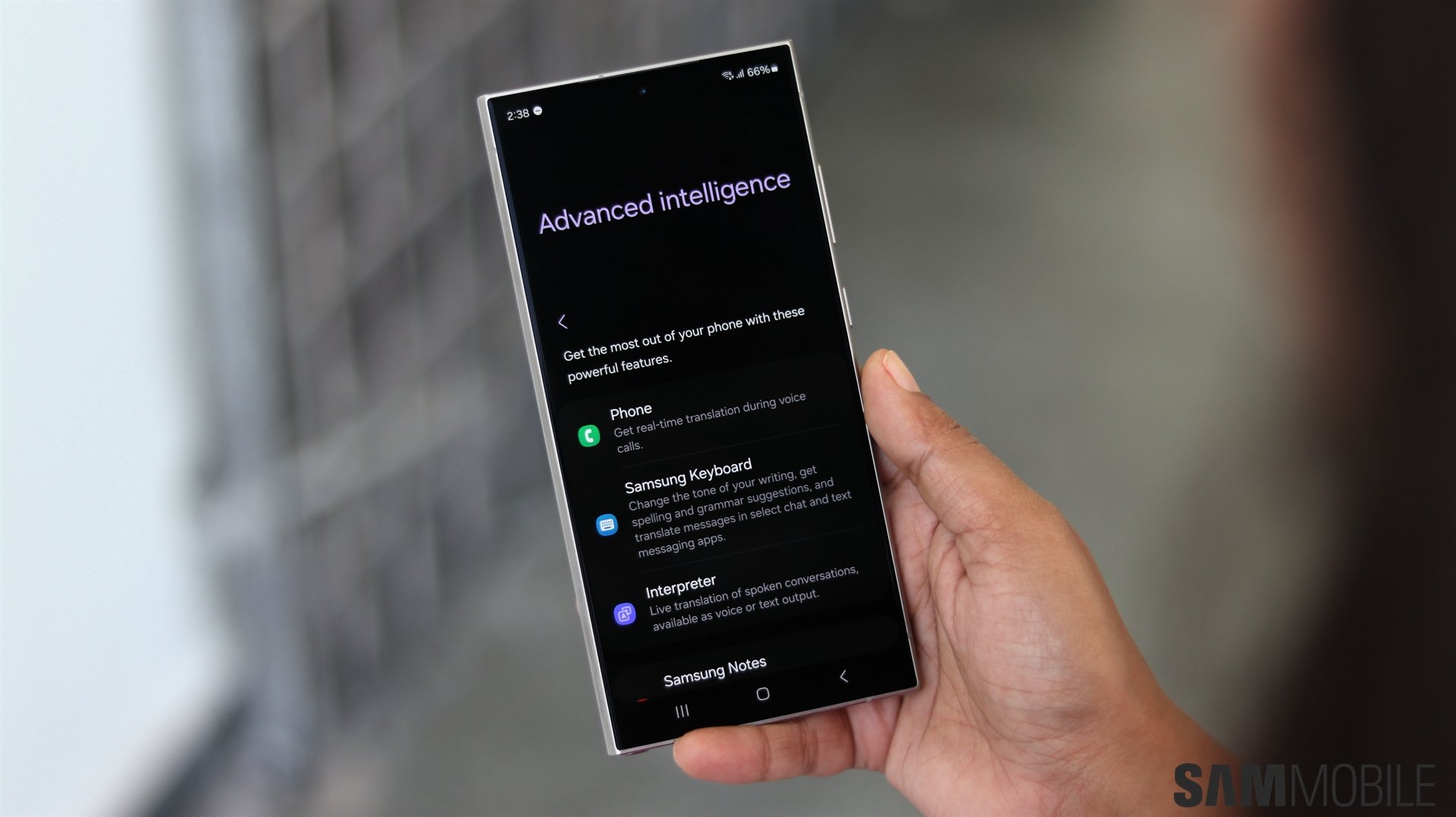





 NeuroPrompts is a generative AI auto prompt tuner that transforms simple prompts into more detailed and visually stunning StableDiffusion results—as in this case, an image generated by a generic prompt [left] versus its equivalent NeuroPrompt-generated image.Intel Labs/Stable Diffusion
NeuroPrompts is a generative AI auto prompt tuner that transforms simple prompts into more detailed and visually stunning StableDiffusion results—as in this case, an image generated by a generic prompt [left] versus its equivalent NeuroPrompt-generated image.Intel Labs/Stable Diffusion









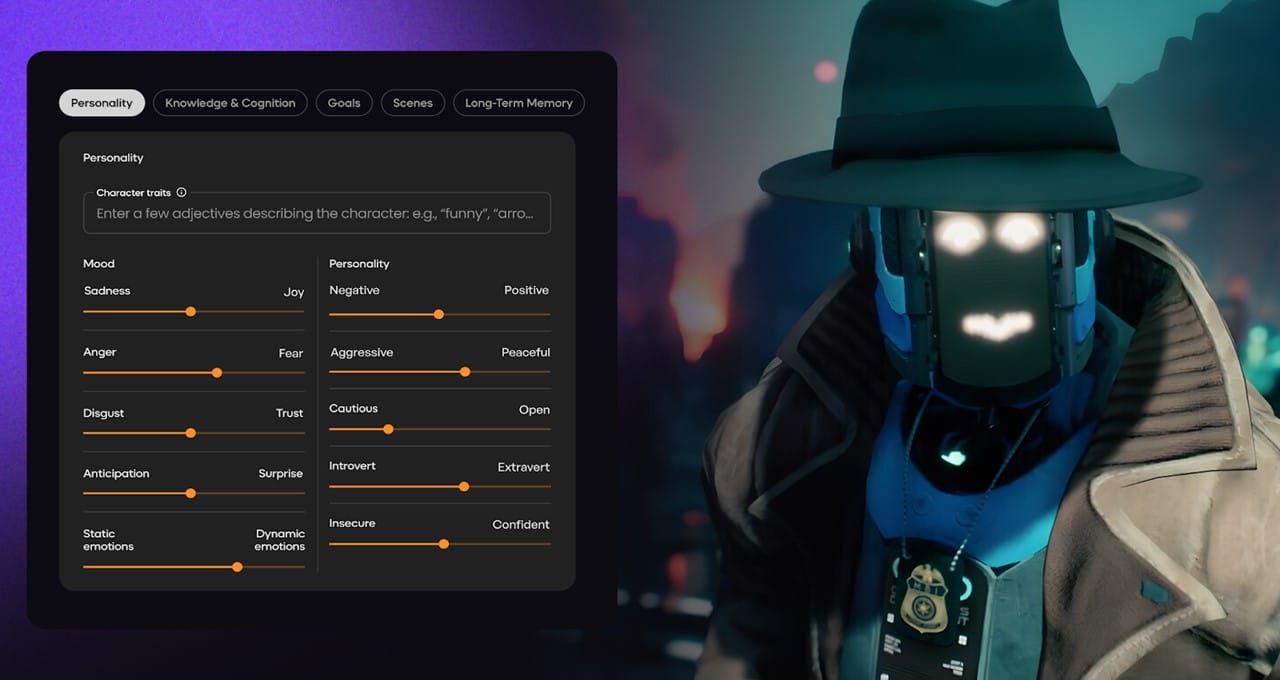









 side. We are just starting to see the beginnings of this integration right now. One of the biggest challenges in the semiconductor industry is it can take years from the time an engineer designs a new device to that device reaching high-volume production. Machine learning is going to cut that to half, or even a quarter. The AI technology that Tignis offers today accelerates that very last step — high-volume manufacturing. Our customers want to know how to tune their tools so that every time they process a wafer the process is in control. Traditionally, device makers get the hardware that meets their specifications from the equipment manufacturer, and then the fab team gets their process recipes working. Depending on the size of the fab, they try to physically replicate that process in a ‘copy exact’ manner, which can take a lot of time and effort. But now device makers can use machine learning (ML) models to autonomously compensate for the differences in equipment variation to produce the exact same outcome, but with significantly less effort by process engineers and equipment technicians.
side. We are just starting to see the beginnings of this integration right now. One of the biggest challenges in the semiconductor industry is it can take years from the time an engineer designs a new device to that device reaching high-volume production. Machine learning is going to cut that to half, or even a quarter. The AI technology that Tignis offers today accelerates that very last step — high-volume manufacturing. Our customers want to know how to tune their tools so that every time they process a wafer the process is in control. Traditionally, device makers get the hardware that meets their specifications from the equipment manufacturer, and then the fab team gets their process recipes working. Depending on the size of the fab, they try to physically replicate that process in a ‘copy exact’ manner, which can take a lot of time and effort. But now device makers can use machine learning (ML) models to autonomously compensate for the differences in equipment variation to produce the exact same outcome, but with significantly less effort by process engineers and equipment technicians.

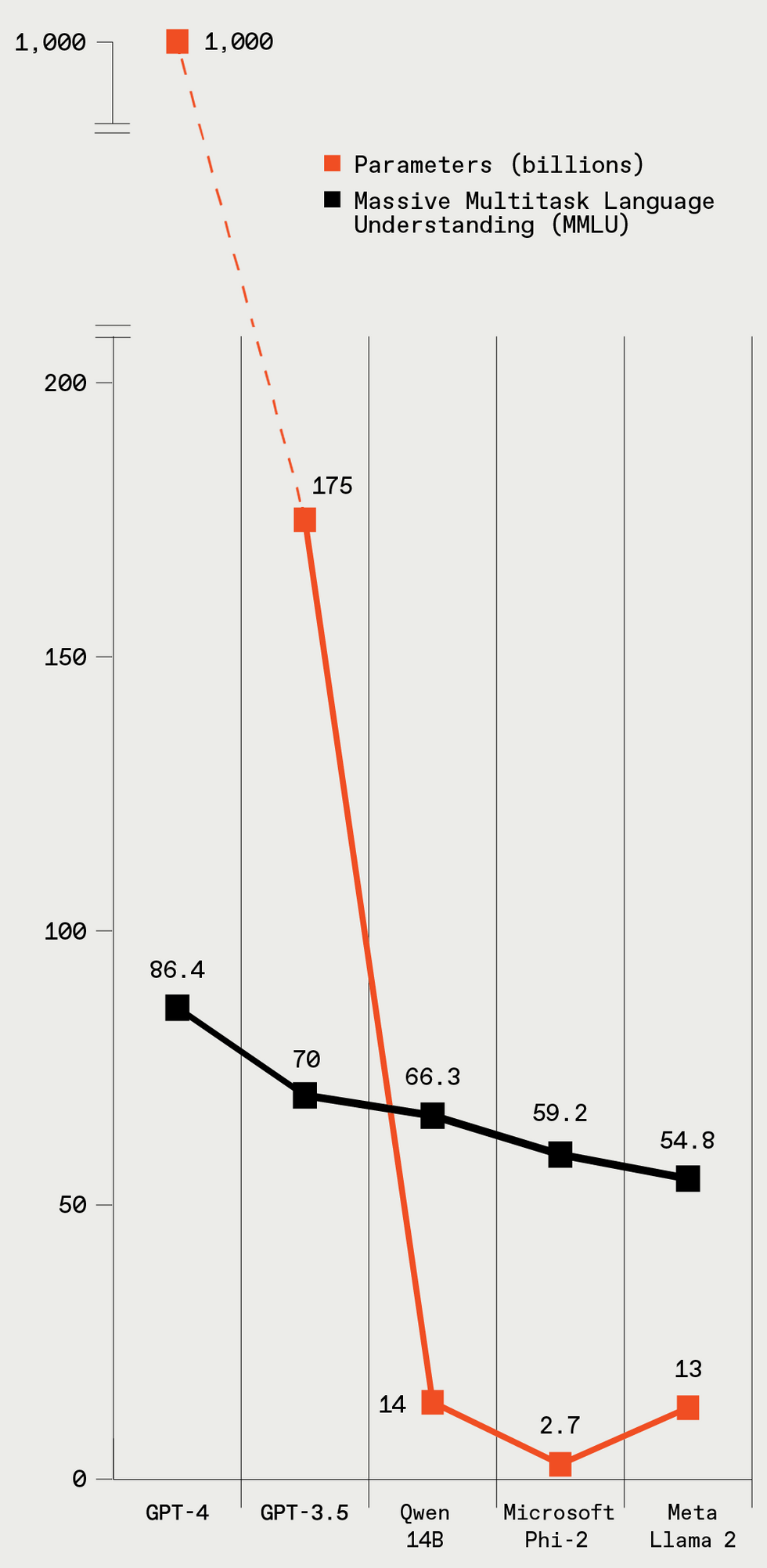 These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum



{kind=link}
{kind=link}
{kind=link}