3.5D: The Great Compromise
The semiconductor industry is converging on 3.5D as the next best option in advanced packaging, a hybrid approach that includes stacking logic chiplets and bonding them separately to a substrate shared by other components.
This assembly model satisfies the need for big increases in performance while sidestepping some of the thorniest issues in heterogeneous integration. It establishes a middle ground between 2.5D, which already is in widespread use inside of data centers, and full 3D-ICs, which the chip industry has been struggling to commercialize for the better part of a decade.
A 3.5D architecture offers several key advantages:
- It creates enough physical separation to effectively address thermal dissipation and noise.
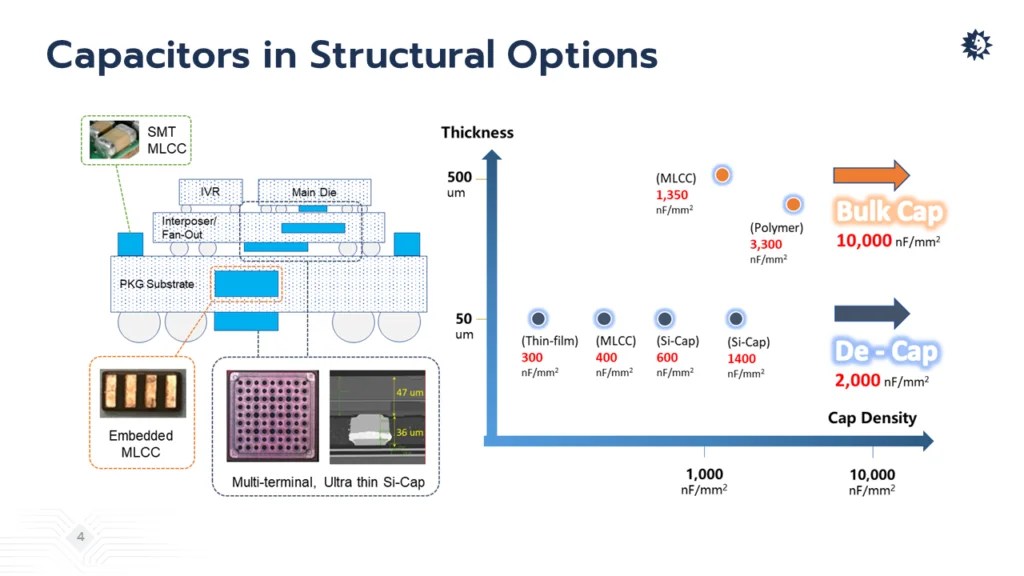
- It provides a way to add more SRAM into high-speed designs. SRAM has been the go-to choice for processor cache since the mid-1960s, and remains an essential element for faster processing. But SRAM no longer scales at the same rate as digital transistors, so it is consuming more real estate (in percentage terms) at each new node. And because the size of a reticle is fixed, the best available option is to add area by stacking chiplets vertically.
- By thinning the interface between processing elements and memory, a 3.5D approach also can shorten the distances that signals need to travel and greatly improve processing speeds well beyond a planar implementation. This is essential with large language models and AI/ML, where the amount of data that needs to be processed quickly is exploding.
Chipmakers still point to fully integrated 3D-ICs as the best performing alternative to a planar SoC, but packing everything into a 3D configuration makes it harder to deal with physical effects. Thermal dissipation is probably the most difficult to contend with. Workloads can vary significantly, creating dynamic thermal gradients and trapping heat in unexpected places, which in turn reduce the lifespan and reliability of chips. On top of that, power and substrate noise become more problematic at each new node, as do concerns about electromagnetic interference.
“What the market has adopted first is high-performance chips, and those produce a lot of heat,” said Marc Swinnen, director of product marketing at Ansys. “They have gone for expensive cooling systems with a huge number of fans and heat sinks, and they have opted for silicon interposers, which arguably are some of the most expensive technologies for connecting chips together. But it also gives the highest performance and is very good for thermal because it matches the coefficient of thermal expansion. Thermal is one of the big reasons that’s been successful. In addition to that, you may want bigger systems with more stuff that you can’t fit on one chip. That’s just a reticle-size limitation. Another is heterogeneous integration, where you want multiple different processes, like an RF process or the I/O, which don’t need to be in 5nm.”
A 3.5D assembly also provides more flexibility to add additional processor cores, and higher yield because known good die can be manufactured and tested separately, a concept first pioneered by Xilinx in 2011 at 28nm.
3.5D is a loose amalgamation of all these approaches. It can include two to three chiplets stacked on top of each other, or even multiple stacks laid out horizontally.
“It’s limited vertical, and not just for thermal reasons,” said Bill Chen, fellow and senior technical advisor at ASE Group. “It’s also for performance reasons. But thermal is the limiting factor, and we’ve talked about many different materials to help with that — diamond and graphene — but that limitation is still there.”
This is why the most likely combination, at least initially, will be processors stacked on SRAM, which simplifies the cooling. The heat generated by high utilization of different processing elements can be removed with heat sinks or liquid cooling. And with one or more thinned out substrates, signals will travel shorter distances, which in turn uses less power to move data back and forth between processors and memory.
“Most likely, this is going to be logic over memory on a logic process,” said Javier DeLaCruz, fellow and senior director of Silicon Ops Engineering at Arm. “These are all contained within an SoC normally, but a portion of that is going to be SRAM, which does not scale very well from node to node. So having logic over memory and a logic process is really the winning solution, and that’s one of the better use cases for 3D because that’s what really shortens your connectivity. A processor generally doesn’t talk to another processor. They talk to each other through memory, so having the memory on a different floor with no latency between them is pretty attractive.”
The SRAM doesn’t necessarily have to be at the same node as the processors advanced node, which also helps with yield, and reliability. At a recent Samsung Foundry event, Taejoong Song, the company’s vice president of foundry business development, showed a roadmap of a 3.5D configuration using a 2nm chiplet stacked on a 4nm chiplet next year, and a 1.4nm chiplet on top of a 2nm chiplet in 2027.

Fig. 1: Samsung’s heterogeneous integration roadmap showing stacked DRAM (HBM), chiplets and co-packaged optics. Source: Samsung Foundry
Intel Foundry’s approach is similar in many ways. “Our 3.5D technology is implemented on a substrate with silicon bridges,” said Kevin O’Buckley, senior vice president and general manager of Foundry Services at Intel. “This is not an incredibly costly, low-yielding, multi-reticle form-factor silicon, or even RDL. We’re using thin silicon slices in a much more cost-efficient fashion to enable that die-to-die connectivity — even stacked die-to-die connectivity — through a silicon bridge. So you get the same advantages of silicon density, the same SI (signal integrity) performance of that bridge without having to put a giant monolithic interposer underneath the whole thing, which is both cost- and capacity-prohibitive. It’s working. It’s in the lab and it’s running.”

Fig. 2: Intel’s 3.5D model. Source: Intel
The strategy here is partly evolutionary — 3.5D has been in R&D for at least several years — and part revolutionary, because thinning out the interconnect layer, figuring out a way to handle these thinner interconnect layers, and how to bond them is still a work in progress. There is a potential for warping, cracking, or other latent defects, and dynamically configuring data paths to maximize throughput is an ongoing challenge. But there have been significant advances in thermal management on two- and three-chiplet stacks.
“There will be multiple solutions,” said C.P. Hung, vice president of corporate R&D at ASE. “For example, besides the device itself and an external heat sink, a lot of people will be adding immersion cooling or local liquid cooling. So for the packaging, you can probably also expect to see the implementation of a vapor chamber, which will add a good interface from the device itself to an external heat sink. With all these challenges, we also need to target a different pitch. For example, nowadays you see mass production with a 45 to 40 pitch. That is a typical bumping solution. We expect the industry to move to a 25 to 20 micron bump pitch. Then, to go further, we need hybrid bonding, which is a less than 10 micron pitch.”

Fig. 3: Today’s interposers support more than 100,000 I/Os at a 45m pitch. Source: ASE
Hybrid bonding solves another thorny problem, which is co-planarity across thousands of micro-bumps. “People are starting to realize that the densities we’re interconnecting require a level of flatness, which the guys who make traditional things to be bonded are having a hard time meeting with reasonable yield,” David Fromm, COO at Promex Industries. “That makes it hard to build them, and the thinking is, ‘So maybe we’ve got to do something else.’ You’re starting to see some of that.”
Taming the Hydra
Managing heat remains a challenge, even with all the latest advances and a 3.5D assembly, but the ability to isolate the thermal effects from other components is the best option available today, and possibly well into the future. Still, there are other issues to contend with. Even 2.5D isn’t easy, and a large percentage of the 2.5D implementations have been bespoke designs by large systems companies with very deep pockets.
One of the big remaining challenges is closing timing so that signals arrive at the right place at the right fraction of a second. This becomes harder as more elements are added into chips, and in a 3.5D or 3D-IC, this can be incredibly complex.
“Timing ultimately is the key,” said Sutirtha Kabir, R&D director at Synopsys. “It’s not guaranteed that at whatever your temperature is, you can use the same library for timing. So the question is how much thermal- and IR-aware timing do you have to do? These are big systems. You have to make sure your sign-off is converging. There are two things coming out. There are a bunch of multi-physics effects that are all clumped together. And yes, you could traditionally do one at a time as sign-off, but that isn’t going to work very well. You need to figure out how to solve these problems simultaneously. Ultimately, you’re doing one design. It’s not one for thermal, one for IR, one for timing. The second thing is the data is exploding. How do you efficiently handle the data, because you cannot wait for days and days of runtime and simulation and analysis?”
Physically assembling these devices isn’t easy, either. “The challenge here is really in the thermal, electrical, and mechanical connection of all these various die with different thicknesses and different coefficients of thermal expansion,” said Intel’s O’Buckley. “So with three die, you’ve got the die and an active base, and those are substantially thinned to enable them to come together. And then EMIB is in the substrate. There’s always intense thermal-mechanical qualification work done to manage not just the assembly, but to ensure in the final assembly — the second-level assembly when this is going through system-level card attach — that this thing stays together.”
And depending upon demands for speed, the interconnects and interconnect materials can change. “Hybrid bonding gives you, by far, the best signal and power density,” said Arm’s DeLaCruz. “And it gives you the best thermal conductivity, because you don’t have that underfill that you would otherwise have to put in between the die, which is a pretty significant barrier. This is likely where the industry will go. It’s just a matter of having the production base.”
Hybrid bonding has been used for years for image sensors using wafer-on-wafer connections. “The tricky part is going into the logic space, where you’re moving from wafer-on-wafer to a die-on-wafer process, which is more complex,” DeLaCruz said. “While it currently would cost more, that’s a temporary problem because there’s not much of an installed base to support it and drive down the cost. There’s really no expensive material or equipment costs.”
Toward mass customization
All of this is leading toward the goal of choosing chiplets from a menu and then rapidly connecting them into some sort of architecture that is proven to work. That may not materialize for years. But commercial chiplets will show up in advanced designs over the next couple years, most likely in high-bandwidth memory with a customized processor in the stack, with more following that path in the future.
At least part of this will depend on how standardized the processes for designing, manufacturing, and testing become. “We’re seeing a lot of 2.5D from customers able to secure silicon interposers,” said Ruben Fuentes, vice president for the Design Center at Amkor Technology. “These customers want to place their chiplets on an interposer, then the full module is placed on a flip-chip substrate package. We also have customers who say they either don’t want to use a silicon interposer or cannot secure them. They prefer an RDL interconnect with S-SWIFT or with S-Connect, which serves as an interposer in very dense areas.”
But with at least a third of these leading designs only for internal use, and the remainder confined to large processor vendors, the rest of the market hasn’t caught up yet. Once it does, that will drive economies of scale and open the door to more complete assembly design kits, commercial chiplets, and more options for customization.
“Everybody is generally going in the same direction,” said Fuentes. “But not everything is the same height. HBMs are pre-packaged and are taller than ICs. HBMs could have 12 or 16 ICs stacked inside. It makes a difference from a co-planarity and thermal standpoint, and metal balancing on different layers. So now vendors are having a hard time processing all this data because suddenly you have these huge databases that are a lot bigger than the standard packaging databases. We’re seeing bridges, S-Connect, SWIFT, and then S-SWIFT. This is new territory, and we’re seeing a performance gap in the packaging tools. There’s work that needs to be done here, but software vendors have been very proactive in finding solutions. Additionally, these packages need to be routed. There is limited automated routing, so a good amount of interactive routing is still required, so it takes a lot of time.”

Fig. 4: Packaging roadmap showing bridge and hybrid bonding connections for modules and chiplets, respectively. Source: Amkor Technology
What’s missing
The key challenges ahead for 3.5D are proven reliability and customizability — requirements that are seemingly contradictory, and which are beyond the control of any single company. There are four major pieces to making all of this work.
EDA is the first important piece of the puzzle, and the challenge extends just beyond a single chip. “The IC designers have to think about a lot of things concurrently, like thermal, signal integrity, and power integrity,” said Keith Lanier, technical product management director at Synopsys. “But even beyond that, there’s a new paradigm in terms of how people need to work. Traditional packaging folks and IC designers need to work closely together to make these 3.5D designs successful.”
It’s not just about doing more with the same or fewer people. It’s doing more with different people, too. “It’s understanding the architecture definition, the functional requirements, constraints, and having those well-defined,” Lanier said. “But then it’s also feasibility, which includes partitioning and technology selection, and then prototyping and floor-planning. This is lots and lots of data that is required to be generated, and you need analysis-driven exploration, design, and implementation. And AI will be required to help designers and system design teams manage the sheer complexity of these 3.5D designs.”
Process/assembly design kits are a second critical piece, and this is likely to be split between the foundries and the OSATs. “If the customer wants a silicon interposer for a 2.5D package, it would be up to the foundry that’s going to manufacture the interposer to provide the PDK. We would provide the PDK for all of our products, such as S-SWIFT and S-Connect,” said Amkor’s Fuentes.
Setting realistic parameters is the third piece of the puzzle. While the type of processing elements and some of the analog functions may change — particularly those involving power and communication — most of the components will remain the same. That determines what can be pre-built and pre-tested, and the speed and ease of assembly.
“A lot of the standards that are being deployed, like UCIe interfaces and HBM interfaces are heading to where 20% is customization and 80% is on the shelf,” said Intel’s O’Buckley. “But we aren’t there today. At the scale that our customers are deploying these products, the economics of spending that extra time to optimize an implementation is a decimal point. It’s not leveraging 80/20 standards. We’ll get there. But most of these designs you can count on your fingers and toes because of the cost and scale required to do them. And until the infrastructure for standards-based chiplets gets mature, the barrier of entry for companies that want to do this without that scale is just too high. Still, it is going to happen.”
Ensuring processes are consistent is the fourth piece of the puzzle. The tools and the individual processes don’t need to change. “The customer has a ‘target’ for the outcome they want for a particular tool, which typically is a critical dimension measured by a metrology tool,” said David Park, vice president of marketing at Tignis. “As long as there is some ‘measurement’ that determines the goodness of some outcome, which typically is the result of a process step, we can either predict the bad outcome — and engineers have to take some corrective or preventive action — or we can optimize the recipe of that tool in real time to keep the result in the range they want.”
Park noted there is a recipe that controls the inputs. “The tool does whatever it is supposed to do,” he said. “Then you measure the output to see how far you deviated from the acceptable output.”
The challenge is that inside of a 3.5D system, what is considered acceptable output is still being defined. There are many processes with different tolerances. Defining what is consistent enough will require a broad understanding of how all the pieces work together under specific workloads, and where the potential weaknesses are that need to be adjusted.
“One of the problems here is as these densities get higher and the copper pillars get smaller, the amount of space you need between the pillar and the substrate have to be highly controlled,” said Dick Otte, president and CEO of Promex. “There’s a conflict — not so much with how you fabricate the chip, because it usually has the copper pillars on it — but with the substrate. A lot of the substrate technologies are not inherently flat. It’s the same issue with glass. You’ve got a really nice flat piece of glass. The first thing you’re going to do is put down a layer of metal and you’re going to pattern it. And then you put down a layer of dielectric, and suddenly you’ve got a lump where the conductor goes. And now, where do you put the contact points? So you always have the one plan which is going to be the contact point where all the pillars come in. But what if I only need one layer and I don’t need three?”
Conclusion
For the past decade, the chip industry has been trying to figure out a way to balance faster processing, domain-specific designs, limited reticle size, and the enormous cost of scaling an SoC. After investigating nearly every possible packaging approach, interconnect, power delivery method, substrate and dielectric material, 3.5D has emerged as the front runner — at least for now.
This approach provides the chip industry with a common thread on which to begin developing assembly design kits, commercial chiplets, and to fill in the missing tools and services throughout the supply chain. Whether this ultimately becomes a springboard for full 3D-ICs, or a platform on which to use 3D stacking more effectively, remains to be seen. But for the foreseeable future, large chipmakers have converged on a path forward to provide orders of magnitude performance improvements and a way to contain costs. The rest of the industry will be working to smooth out that path for years to come.
Related Reading
Intel Vs. Samsung Vs. TSMC
Foundry competition heats up in three dimensions and with novel technologies as planar scaling benefits diminish.
3D Metrology Meets Its Match In 3D Chips And Packages
Next-generation tools take on precision challenges in three dimensions.
Design Flow Challenged By 3D-IC Process, Thermal Variation
Rethinking traditional workflows by shifting left can help solve persistent problems caused by process and thermal variations.
Floor-Planning Evolves Into The Chiplet Era
Automatically mitigating thermal issues becomes a top priority in heterogeneous designs.
The post 3.5D: The Great Compromise appeared first on Semiconductor Engineering.








![Fig. 1: Asymmetric forward back-biasing scheme for permanent erasing. (a) All the data are reset to 1. (b) All the data are reset to 0. Whether all the data where reset to 1 or 0 is determined by the asymmetric forward back-biasing scheme. Source: KAIST/Creative Commons [2]](https://i0.wp.com/semiengineering.com/wp-content/uploads/Fig01_KAIST_SRAM_back-biasing_CC.png?resize=1264%2C1404&ssl=1)






















 noted the foundry will be offer Intel developments and innovations developed by the product teams. “The à la carte menu is wide open for the industry,” he said during a Q&A session. “Clearwater Forest, which I showed today, is a construct that was innovated by my Xeon team — how to do hybrid bonding, Intel three base dies, 18A top die, being able to solve a lot of the CoWoS/Foveros problems using EMIB and hybrid bonding. That will become a set of collaterals that will benefit the foundry. They’re going to sell that constructional opportunity as a better way to build AI chips. So clearly, I’m taking product group intellectual property and leveraging it on the foundry side.”
noted the foundry will be offer Intel developments and innovations developed by the product teams. “The à la carte menu is wide open for the industry,” he said during a Q&A session. “Clearwater Forest, which I showed today, is a construct that was innovated by my Xeon team — how to do hybrid bonding, Intel three base dies, 18A top die, being able to solve a lot of the CoWoS/Foveros problems using EMIB and hybrid bonding. That will become a set of collaterals that will benefit the foundry. They’re going to sell that constructional opportunity as a better way to build AI chips. So clearly, I’m taking product group intellectual property and leveraging it on the foundry side.”
