As device scaling slows down, a key system functional integration technology is emerging: heterogeneous integration (HI). It leverages advanced packaging technology to achieve higher functional density and lower cost per function. With the continuous development of major semiconductor applications such as AI HPC, edge AI and autonomous electrical vehicles, traditional chips are transforming into smaller, well-partitioned chiplets that require chip-to-chip interconnections to be denser, faster and more reliable. This boosts the demand for heterogeneous integration, elevating demand for innovative advanced packaging technologies.
HI uses advanced packaging to integrate chiplets with heterogeneous designs and process nodes into a single package. This allows enterprises to choose optimum process nodes for specific system demands, such as 3nm for computing chiplets, 7nm for radio frequency chiplets, or to quickly produce super chips with specific functions in a cost-effective manner. HI not only aims for higher interconnection density, but also integrates various functional components, such as logic chips, sensors, memory, and others, which are needed to complete the whole system in one package. Overall energy efficiency and performance is greatly improved, while package size can be significantly reduced.
Advanced packaging solutions for AI HPC
The typical high-density advanced package size for AI cloud computing processors is 55mm x 55mm or more, and contains a 5-2-5 (top 5 layers, middle 2 layers, bottom 5 layers) advanced substrate, or even up to 11-2-11 wiring layers. Chiplets can be interconnected by fan-out technology with silicon bridge or 2.5D with Si Interposer as the integration platform. Through this technique, industry aims to gain more computing power within the same space.
ASE provides high-density packaging solutions, including Flip Chip Ball Grid Array (FCBGA), Fan Out Chip-on-Substrate (FOCoS), FOCoS-Bridge and 2.5D. The chip-to-chip interconnections in FCBGA is accomplished through BGA substrate, and its minimum L/S (line width/line spacing) is only about 10μm/10μm. The very popular and in-demand CoWoS (Chip on Wafer on Substrate) is a 2.5D packaging technology that uses RDL (redistribution layer) on Si interposer to connect chiplets, and its L/S can be significantly reduced to 0.5μm/0.5μm.
In the Si interposer of a 2.5D package, all the chiplets are connected in a side-by-side arrangement, and as the required number of chiplets increases, its area becomes larger and larger, resulting in fewer and fewer Si interposer chips that can be made from each 12-inch wafer (generally less than 50). This indeed significantly increases the manufacturing cost of 2.5D packaging. However, not all applications require 0.5μm/0.5μm L/S, so ASE came up with FOCoS, which uses fan-out technology’s RDL to integrate different chiplets, and its L/S can reach 2μm/2μm. This gives alternative solutions to the market with lower costs. In addition, ASE’s FOCoS-Bridge technology uses silicon bridge to provide high-density routing for interconnecting different chips (such as logic chips and memory) in areas that require high-speed transmission and uses Fan-Out RDL to integrate in other areas. As such, it delivers both 0.5μm/0.5μm and 2μm/2μm flexibility in L/S design, while achieving a significant increase in packaging density and bandwidth.

High performance chip-package-system co-design
To achieve the aforementioned high bandwidth, the chip, package, and entire system must be designed together to achieve holistic design optimization instead of just considering the individual parts. When using electronic design automation (EDA) for design optimization, consideration must be given to overall signal change along the entire transmission path, including Cu pillar, RDL fine line, TSV, μbump, etc. Eye diagrams can then be used to analyze the SerDes link’s electrical performance. When designing differential pairs for high-speed signals, it is necessary to reduce return and insertion loss, especially in the operating frequency band. From chip to package to the entire system, Taiwan’s manufacturing advantage lies in the ability to accomplish the turnkey design process, from beginning to end.

Providing more computing power with less energy
The industry is currently focused on optimizing energy efficiency. One of the key questions being asked is whether the power regulation and decoupling components, which were previously located on the system board, can be moved closer to the package or processor chip. There is even talk of redesigning the on-chip power delivery network (PDN), including supplying power directly from the backside of the chip (Backside PDN).

Power integrity design for power delivery network (PDN)
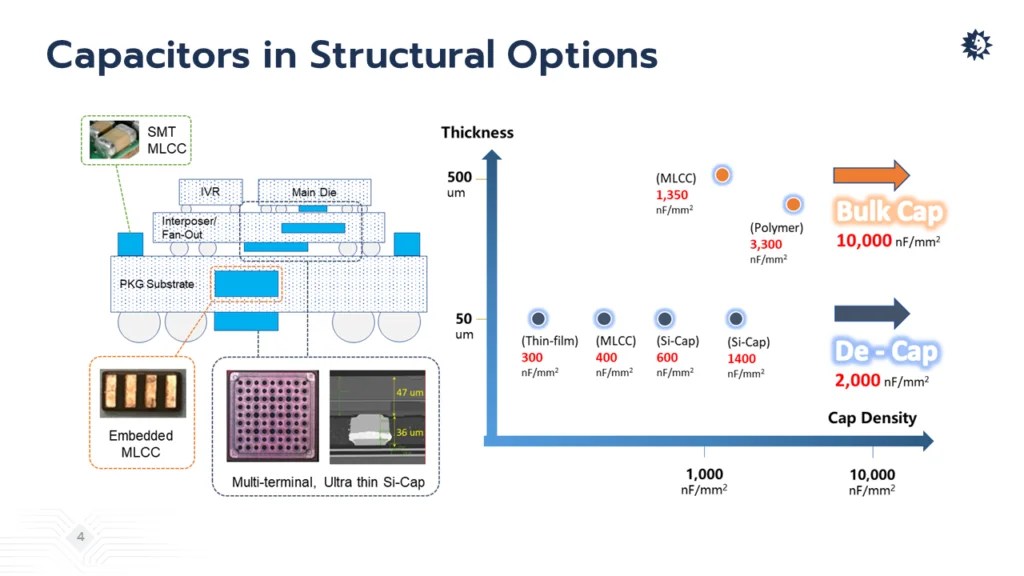
Optimizing power integrity and minimizing noise can be achieved by strategically positioning the capacitor. Ideally, the capacitor should be placed as close to the chip as possible, but this is dependent on the capacitor’s size and the manufacturing process, both of which can impact cost and performance. Traditional surface-mount technology (SMT) capacitors are relatively large, but chip-level silicon capacitors (Si-Cap) are now available that offer decent capacitance values.

UCIe (Universal Chiplet Interconnect Express) Consortium
Traditionally, there are many standard communication protocols (such as Block-to-Block, Memory Bus, or Interconnection Interface Protocols) at the chip level and the board level for system designers. Industry protocols that specify package-level integration are growing, especially given the need for a universal interface for chiplet integration using 2.5D and FOCoS packaging technologies.
In March 2022, Intel invited upstream and downstream manufacturers in the semiconductor industry chain to form the UCIe Consortium, and a standardized data transmission architecture for chiplet integration was introduced to reduce the cost of advanced packaging design. ASE is proud to be a founding member (Promoter member).
ASE offers a diverse range of advanced packaging types. We have developed packaging design specifications that can be integrated with foundry solutions specifications as well as the system requirements of original equipment manufacturers (OEMs) and cloud service providers to create a comprehensive UCIe package standard. The standard can assist in realizing ubiquitous chiplet heterogeneous integration for HPC applications using various advanced packaging technology architectures, such as 2.5D, 3D, FOCoS, Fan-out, EMIB, CoWoS, etc. Headquartered in Taiwan, ASE is enthusiastically participating in the formulation of international standards and relentlessly providing integrated solutions to the global industry.

Heterogeneous integration has been in development for many years. It can be used to integrate not only homogeneous and heterogeneous chiplets but also other passive and active components including connectors, into a single package. Achieving this requires not only advanced packaging technologies but also design and testing coordination. ASE offers a comprehensive one-stop service solution that includes system design, packaging, and testing to help customers shorten chip design cycles and accelerate product innovation.
The post Advanced Packaging Design For Heterogeneous Integration appeared first on Semiconductor Engineering.